

I. 서론
II. 선행연구 검토
1. 소셜 네트워크 서비스 데이터를 이용한 공간정보 빅데이터 분석
2. 관심지점(POI) 구축
III. 관심 지점(POI) 구축 모델 개발
1. 관심지점 구축 알고리즘
2. 레벤슈타인 거리
IV. 관심 지점(POI) 구축 모델의 구현
1. 데이터 수집 및 전처리
2. 명칭쌍 생성
3. 레벤슈타인 거리 계산
4. 관심지점 데이터 구축
5. 관심정보 구축모델의 정확도 평가
V. 결론
I. 서론
관심 지점(POI)이란 현실 세계 또는 지도나 도면상의 특정한 지리적 위치를 뜻하는 것으로, 주로 디지털 지도 위에서 표현될 수 있는 주요 시설물(학교, 은행 관광지, 교통시설, 문화시설, 음식점, 연례 축제 장소 등)과 지역 등을 지칭한다. 이러한 POI는 위치 기반 서비스에서 대부분의 데이터를 연결하고 관리하는 기준점으로 쓰인다(김경민, 2014). 즉 지도 검색 서비스나 내비게이션에서 디스플레이하거나 검색할 때 나타나는 지점들이 바로 POI라 할 수 있다. 국토지리정보원에서는 우리나라의 주요 관심 지점을 선정하여 국가 관심 지점 정보로 관리하고 있다. 국가 관심 지점이란 우리나라의 주요 지형지물을 대상으로 공공기관이 보유한 위치 정보와 다양한 속성정보를 포함하는 점(point) 타입의 공간적 객체이다. 여기에는 국가 관심 지점 정보 분류와 지점 명칭, 법정 코드, 주소 및 전화번호, 위도, 경도, 위치 정확도가 제공된다.
이러한 국가 관심 지점을 구축하고 관리하는 과정에서 많은 제약이 따르고 있다. POI 데이터 취득을 위해서는 다소 복잡한 구축 과정이 필요하다. POI 데이터 취득을 위해 사전에 지역별로 조사를 위한 작업계획을 수립해야 한다. 이를 기반으로 현장조사와 관련 문헌 자료를 참조하여 POI 데이터를 취득하게 된다. 이렇듯 POI의 구축 과정에는 시간과 비용의 문제가 발생한다. 또한 공공과 민간의 정보 갱신 주기의 차이로 데이터를 통합하는 데 지도로 구현된 데이터의 시간 정확성이 미흡하며, 위치 정보 제공의 바탕이 되는 시설물에 대하여 공공과 민간의 유지 관리 비용의 중복 투입과 위치 정보 유지 관리의 한계점이 나타난다.
이러한 문제를 해결하기 위하여 소셜 네트워크 서비스(social network servic, SNS)와 위치기반 서비스(location based service, LBS)를 결합한 위치기반 소셜 네트워크 서비스(location based social network service, LBSNS) 데이터를 활용하여 POI를 구축할 수 있는 모델을 개발하고자 한다. LBSNS는 사용자들이 특정 장소를 중심으로 콘텐츠를 작성하거나 사용자들 간 정보를 교환한다는 점에서 기존의 SNS와 차이점을 갖는다. 대표적인 LBSNS의 하나인 포스퀘어(FourSquare)는 사용자들과 위치를 공유하는 SNS로 스마트폰을 이용하여 특정 장소에 체크인하면 해당 장소에 대한 정보와 평판 등을 공유할 수 있는 서비스이다(구자용, 2020).
본 연구에서는 관심 지점(Point Of Interest, POI) 구축 모델을 개발하는 과정에서 LBSNS 데이터를 활용하고자 한다. 대표적인 LBSNS인 포스퀘어의 베뉴 데이터를 추출하고 이를 기존의 POI에 추가하는 모델을 개발하여, POI 구축 모델의 활용가능성을 제시하고자 한다. 이를 위하여 LBSNS 데이터와 국가 관심 지점 데이터를 수집하고 전처리하고 두 데이터 간 명칭쌍을 생성하고 레벤슈타인 거리(Levenshtein Distance)를 계산하는 과정을 거쳐 새로운 POI를 구축하였다.
본 연구의 수행과정에서 사용된 프로그래밍 언어는 파이썬(Python)을 활용하였고 개발환경은 비주얼 스튜디오 코드(visual studio code) 소프트웨어를 사용하였다. 구축된 POI의 시각화 및 공간 분포 특성을 분석하기 위해 ArcGIS 소프트웨어를 사용하였다. 본 연구의 모델 개발을 위해 서울시 종로구를 연구 대상 지역으로 선정하였다.
II. 선행연구 검토
1. 소셜 네트워크 서비스 데이터를 이용한 공간정보 빅데이터 분석
빅 데이터란 디지털 환경에서 생성되는 대규모의 데이터를 뜻하는 것으로 크기가 너무 커서 기존 방법이나 도구로 수집 및 저장, 분석 등이 어려운 정형 또는 비정형 데이터를 의미한다(오충원, 2013). 최근에는 빅 데이터에서 공간정보의 비중이 점차 커지고 있는데 ‘공간정보 빅 데이터(spatial big data)’란 스마트폰과 같은 모바일 환경에서 위치 기반 서비스를 사용하면서 SNS데이터에 GNSS 등의 위치 정보가 추가되어 공간정보에 초점을 둔 빅 데이터를 칭한다(구자용, 2015; 오충원, 2013). SNS를 통하여 생산되고 유통되는 데이터는 대표적인 빅 데이터라 할 수 있다. SNS는 사용자 간의 자유로운 의사소통과 정보 공유, 그리고 인맥 확대를 통해 사회적 관계를 생성하고 강화해주는 온라인 플랫폼이다(유은혜, 2021). 사람들에게 SNS가 일상화되면서 사용자 간 정보교환, 팔로우 그룹 형성, 의사소통 및 정보전달, 휴식 및 오락, 사적 기록 등의 활동 등이 데이터 형태로 저장되고 있다(강애띠・강영옥, 2015).
SNS를 활용한 공간정보 빅 데이터 분석 연구는 크게 두 가지 연구로 나누어 볼 있다. 첫 번째 연구는 SNS 상의 텍스트를 마이닝하여 시공간적 분포를 유추하는 연구와 지역적 특성을 분석하는 연구이다. 강애띠・강영옥(2015)은 트위터 사용자의 거주 지역을 유추하는 방법으로 사용자 타임라인 데이터 속에서 찾아낸 일상 생활 활동 패턴을 이용하는 방법을 고안하였다. 구자용(2015, 2017)은 트윗 데이터가 가지고 있는 시공간 정보, 그리고 사용자 정보를 이용하여 시간별 공간분포 변화, 시간대별 이동 경로, 개인의 시공간 경로 등 시공간 활동 패턴을 분석하였다. 이러한 연구들을 통해 SNS의 텍스트 데이터를 이용해 시공간 분포를 유추하고 지역별 특징의 분석이 가능함을 확인하였다. 두 번째는 연구는 LBS의 발전으로 SNS에 지오 태그 기능이 특화된 LBSNS가 등장함에 따라 LBSNS의 위치 정보를 이용하여 공간 패턴을 분석하는 연구이다. 구자용(2016)은 LBSNS인 포스퀘어 자료를 이용하여 그 분포 특성을 파악하고 서울시 상업공간의 분포와 비교함으로써 공간정보 분야에서 LBSNS 데이터의 활용 가능성을 제시하였다. 홍일영(2016)은 포스퀘어를 사례로 베뉴와 팁에 관한 정보를 수집하여 데이터의 지역 간 특징 및 차이를 분석하고자 하였다. 서일정・조재희(2020)는 서울시에서 발생한 포스퀘어 사용자들의 체크인 데이터를 이용하여 LBSNS 사용자의 집단적 활동 군집을 발견하는 방법을 제안하였다.
이와 같이 SNS를 활용한 공간정보 빅 데이터 분석 연구는 SNS의 텍스트 데이터로 시공간적 분포를 유추하는 연구와 지역적 특성을 분석하는 연구, LBSNS의 위치 정보를 이용하여 공간 패턴을 분석하는 연구가 주를 이루고 있었다.
2. 관심지점(POI) 구축
지형공간정보체계 용어사전(이강원・손호웅, 2016)에 의하면 관심 지점(POI)이란 특정인이 관심을 가지는 현실 세계 또는 지도나 도면상의 특정 위치를 말한다. 관심지점(POI)은 전자 지도나 내비게이션 화면에서 주요 시설물의 위치와 목적지 검색, 그리고 바탕화면에 나타나는 데이터라 할 수 있다. 국토지리정보원에서는 국가 차원에서 POI를 관리하고 있으며, 이를 국가 관심지점이라 한다. 국가 관심 지점 정보는 개별 공공기관이 보유한 주요 지형지물(주요 시설물, 공공기관, 기차역, 공항, 버스터미널 등 자연 및 인공 지형지물 모두 포함)의 위치정보가 반영된 명칭으로 지도 서비스에서 POI를 지도에 시각화하거나 검색할 때 사용할 수 있는 모든 정보(좌표, 명칭, 전화번호, 주소 등)를 뜻한다. 이러한 POI를 구축하기 위해서는 데이터 선정, 현지 조사, 검수, 입력 등의 절차를 거쳐야 하며, 이러한 과정에서 많은 인력과 비용이 소요된다. 따라서 POI 구축과정에서 나타나는 문제를 최소화하고 시간과 비용면에서 효율적으로 POI를 구축하기 위한 연구가 수행되어 왔다.
POI의 구축과 관련된 연구는 크게 네 주제로 나뉜다. 첫 번째는 LBSNS 데이터를 이용하여 POI의 분포 특징 및 사용자의 특징을 분석하는 연구이다. 오효정 등(2014)은 기존 연구가 단말기의 현재 위치 정보만 활용하는 단점을 보완하기 위해 SNS 데이터의 내용을 분석하고 메타데이터를 활용하여 사용자 프로파일을 구축, 이를 기반으로 POI들 간의 상관성 분석을 수행하는 방법을 제안하였다. Yun(2015)은 위치 서비스를 제공하는 트위터에서 생성된 대용량 문서 및 서비스를 이용하여 사용자 프로파일을 추출하여 성별, 지역, 시간에 따른 주요 POI를 분석하고 해당 프로파일에 따른 POI 상관관계를 확인하였다.
두 번째는 POI 검색 알고리즘을 개선하는 연구이다. 검색 시 사용자의 부정확한 검색어로 인한 성능 저하 문제 해결을 위한 POI 검색 알고리즘에 대해 다양한 방법론이 개발되었다. 고은별・이종우(2014)는 부정확한 POI 검색 서비스의 성능 저하의 문제를 해결할 수 있는 새로운 POI 데이터 검색 알고리즘을 제시하였다. 이재원(2013)은 사용자의 POI 입력 질의어의 오류를 자동으로 복원할 수 있는 새로운 검색 기법을 제안하였다. 최지혜 등(2018)은 기존 POI 검색 방법과는 다르게 한글로 이루어진 POI 데이터와 심층 신경망 딥러닝을 접목하여 POI 검색 결과의 성공률과 정확도 향상 가능성을 비교하도록 하였다.
세 번째는 POI의 추출 과정에서 모호성을 해결하기 위한 연구이다. 김정옥 등(2009)은 이종의 공간정보를 통합하는 연구를 진행하였다. 실세계의 대응되는 공간객체를 매칭하는 연구를 중심으로 전자지도와 POI와 같은 이종의 공간정보를 효율적으로 통합하는 방법을 개발하였다. 김경민(2014)은 여행 후기의 한글 텍스트로부터 POI 후보를 탐지하고 POI를 POI 집합에 연결하는데 나타나는 모호성을 해소하는 두 단계의 관심 지점 탐지 방법을 제안하였다. 김민규・박수홍(2014)은 SNS 중 트위터를 이용하여 POI를 추출하고 기구축되어 있는 기존 POI로부터 공간 관계를 추출해 사람이 인지할 수 있는 공간 범위를 산정하였다.
네 번째 주제는 POI 추천 시스템에 대한 연구이다. POI 추천에 관한 연구는 POI를 주제로 한 연구에서 활발하게 이루어지고 있다. 김범수 등(2012)은 실내 위치 기반 서비스의 POI 추천 시스템의 구현과 사용자들의 이동 데이터로부터 다양한 관심 지점을 고려하기 위해 사용자가 일정 시간 동안 머무른 지점을 ‘Stay Point’라 정의하고 실내 공간에서 Stay Point를 탐색하는 알고리즘을 제안하였다. 김서경 등(2015)은 LBSN에 축적된 위치정보 데이터가 사용자들의 관심 지점인 POI 추출에 활용될 수 있을 뿐 아니라 사용자들의 POI를 순차적으로 연결한 이동경로를 파악하는 데에 활용될 수 있다고 보았다. 이규남 등(2018)은 LBSNS에서 시간과 사용자 활동을 고려한 장소 추천 기법을 제안하였다. 정구임・안병익(2014)은 사용자 체크인 데이터를 활용할 수 있는 LBSNS 기반 장소 추천 시스템을 개발하고자 하였다.
이와 같이 POI의 구축과정을 개선하고 보다 명확한 POI를 구축하기 위하여 다양한 연구가 수행되어 왔으며, 특히 POI 구축 과정에서 LBSNS 데이터를 활용한 연구가 활발히 수행되고 있다. 본 연구에서는 이러한 연구의 일환으로 포스퀘어에서 추출한 LBSNS데이터를 이용하여 POI를 구축하는 모델을 개발하고자 한다.
III. 관심 지점(POI) 구축 모델 개발
1. 관심지점 구축 알고리즘
POI 구축을 위해서는 시간과 비용, 지도 데이터의 시간 정확성, 위치 정보의 유지 관리라는 한계점이 따른다. 본 연구에서는 이러한 한계를 보완하기 위하여 LBSNS 데이터를 기반으로 파이썬을 사용하여 POI를 구축하는 모델을 개발하였다.
모델 개발 알고리즘은 그림 1과 같이 구성되어 있다. 첫 번째 단계는 국가 관심 지점 정보 데이터와 포스퀘어 데이터를 수집, 입력, 전처리하는 단계이다. 이를 위하여 국가 공간정보 포털에서 국가 관심 지점 정보 데이터를 수집하고, 포스퀘어 API를 이용하여 포스퀘어 베뉴 데이터를 수집한다.
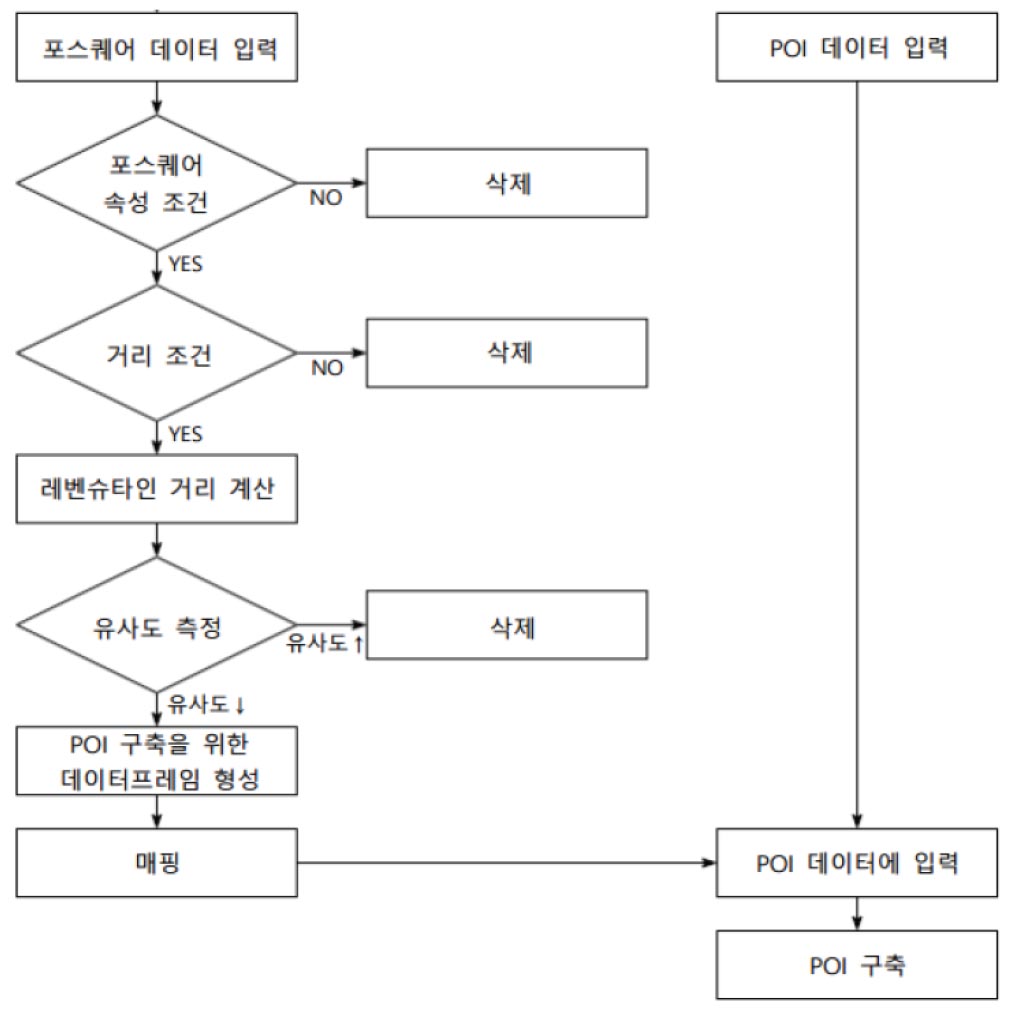
다음 단계는 포스퀘어 데이터를 필터링하고 명칭쌍을 생성하는 단계이다. 데이터의 필터링 단계에서는 포스퀘어 데이터 중에서 무의미한 데이터를 제거하고, 명칭쌍 생성 대상인 데이터를 선택한다. 포스퀘어 데이터의 체크인 수, 팁 수, 유저 수가 0인 데이터는 무의미한 데이터이므로 제거한다. 또한 국가 관심 지점 정보 데이터와 포스퀘어 데이터 간의 공간 거리를 측정하여 임계반경 이내의 데이터를 선택한다. 본 연구에서는 국가 관심 지점 정보인 POI를 기준으로 반경을 조정하여 해당 반경 내에 있는 명칭쌍의 수를 분석하여 그 수가 급격히 줄어드는 구간인 50m를 임계반경으로 설정하였다. 이러한 과정을 거쳐 필터링된 포스퀘어 데이터를 대상으로 명칭쌍을 생성한다.
다음 단계에서는 생성된 명칭쌍을 대상으로 명칭쌍 간 문자열 거리(레벤슈타인 거리)를 계산하고 유사도를 측정한다. 계산된 값으로 유사도를 측정하여 국가 관심 지점 정보 데이터와 포스퀘어 데이터의 명칭쌍이 유사하면 데이터의 중복 가능성이 있으므로 해당 데이터를 삭제한다. 이러한 과정을 거쳐 남은 데이터는 새로운 POI 후보가 된다.
마지막으로 이미 구축된 국가 POI에 POI 후보를 합쳐서 최종적인 POI를 구축한다. 앞의 단계를 거쳐 남아있는 포스퀘어 데이터를 추출하고 매핑(Mapping) 메서드를 이용하여 필드를 정리한 후 어펜드(Append) 메서드를 이용하여 국가 관심 지점 정보와 포스퀘어 데이터를 결합한다. 매핑 메서드란 시리즈나 데이터프레임의 개별 원소를 특정 함수에 일대일 대응시키는 과정을 의미한다. 본 모델에서는 국가 관심 지점 데이터와 결합하기 위해 필요한 필드(위도, 경도)를 생성하고 추출된 포스퀘어 베뉴의 명칭을 기준으로 대응시킨다. 어펜드 메서드는 데이터 프레임을 병합하는 함수로 본 모델에서는 국가 관심 지점 데이터와 추출된 포스퀘어 데이터를 열 이름을 기준으로 병합한다. 결합한 데이터들로 POI를 구축한다.
2. 레벤슈타인 거리
편집 거리(Edit Distance) 알고리즘으로 알려져 있는 레벤슈타인 거리는 1956년 러시아의 수학자 Vladimir Levenshtein에 의해 고안되었다. 레벤슈타인 거리는 두 개의 문자열 간 유사성을 보여주는 척도이다. 데이터 항목이 놓인 순서가 중요한 문자열이나 서열의 유사도를 측정하는 데 유용하게 사용할 수 있다. 레벤슈타인 거리는 언어학과 데이터 과학 같이 폭 넓은 분야에서 사용되고 있으며 문장과 DNA 유사도 분석에도 사용되고 있다.
레벤슈타인 거리는 일반적으로 하나의 문자열을 다른 문자열로 변환할 때 필요한 최소한의 연산의 횟수를 의미한다(고상기・한요섭, 2012). 편집거리를 계산할 때 허용되는 편집 연산에는 삽입(insert), 삭제(deletion), 치환(substitution)이 존재한다. 비교하고자 하는 두 문자열을 2차원 배열로 나타내어 문자를 한 글자씩 비교하며 추가와 삭제 시 연산 비용은 1을 부여하고 대체 연산은 문자의 일치 유무에 따라 0 또는 1을 부여하여 유사도를 계산한다(양유정・이기용, 2019). 두 개의 문자열에 대한 레벤슈타인 거리 산출 방법은 다음과 같이 정의된다.
여기서 문자열 x의 tail은 x의 첫 문자를 제외한 모든 문자열이며 x[n]은 0부터 세는 문자열 x의 n번째 문자이다. 최소값의 첫 번째 요소는 a와 b 사이의 삭제, 두 번째 요소는 삽입, 세 번째 요소는 교체에 해당한다. 레벤슈타인 거리는 a≠b일 경우 1, 그렇지 않을 경우를 0으로 하여 이전 숫자 중 최솟값에 더하여 산정한다(Levenshtein, 1966).
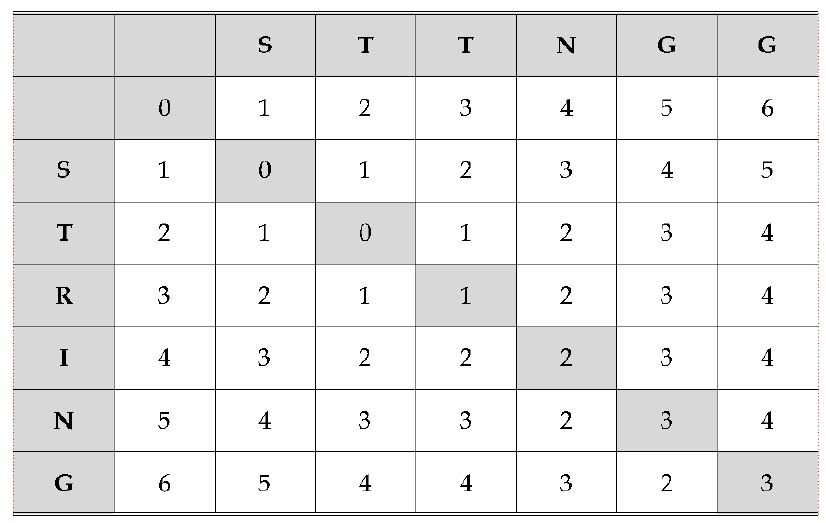
레벤슈타인 거리 알고리즘은 문자열의 문자를 한 자씩 비교해가면서 배열의 형태로 모든 경우의 수를 계산한다. 예를 들어 문자열 ‘STRING’과 문자열 ‘STTINGG’ 간의 레벤슈타인 거리를 계산하는 과정은 다음과 같다. 첫 번째 단계에서는 그림 2와 같이 배열의 행과 열에 각 문자들을 배치하고 숫자를 순서대로 입력한다. 다음 단계에서는 한 자씩 비교하며 삽입, 변경, 삭제 여부를 결정한다. 글자가 서로 동일하면 대각선의 숫자를 가져오고, 변경이 필요한 경우 대각선 수의 1을 더하고, 삽입이 필요한 경우 위의 수에서 1을 더하고, 삭제가 필요한 경우 왼쪽 수에서 1을 더한다. 이와 같은 연산 중 가장 낮은 수를 배열에 입력한다. 마지막 단계에서는 모든 경우의 수를 반복하여 레벤슈타인 거리를 계산한다. 배열의 맨 마지막 수가 레벤슈타인 거리가 된다. 따라서 이 사례의 경우 레벤슈타인 거리는 3이 된다.
IV. 관심 지점(POI) 구축 모델의 구현
1. 데이터 수집 및 전처리
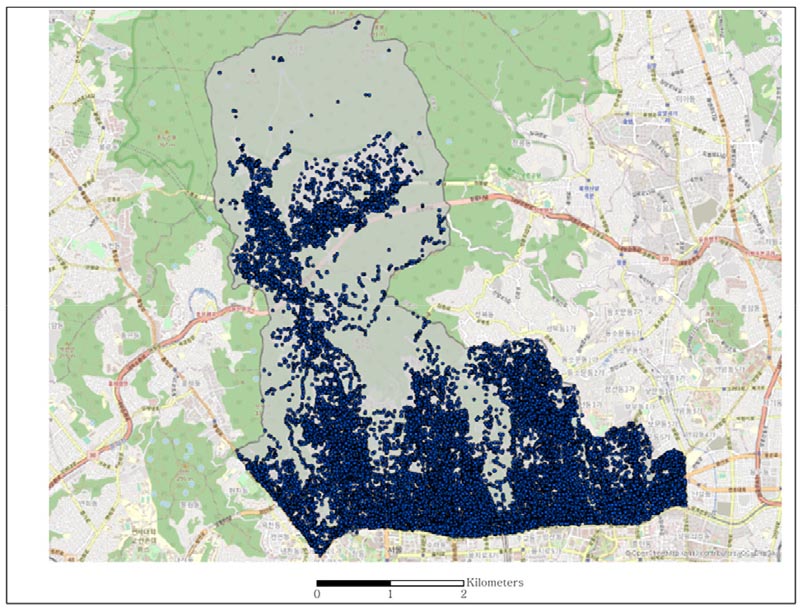
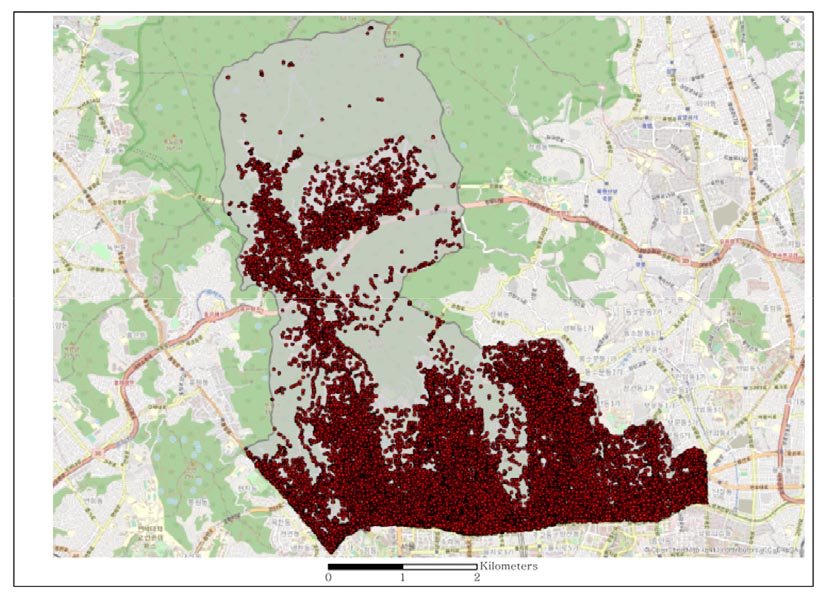
관심 지점 구축의 첫 단계로 국가 관심 지점 정보 데이터와 포스퀘어 데이터를 수집 및 입력하고 전처리하였다. 국가 공간정보 포털에서 2017년 국가 관심지점 정보를 수집하고 서울시 종로구 데이터를 추출하였다. 서울시 종로구의 국가 POI는 그림 3과 같다.
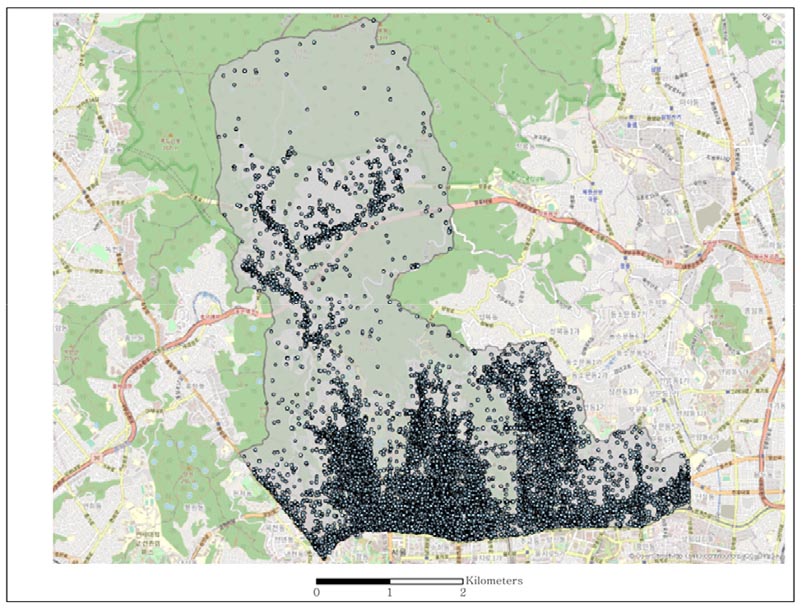
다음으로 포스퀘어 API를 이용하여 2020년 기준 서울시 종로구의 베뉴, 체크인 수, 팁 수, 유저 수, 위도, 경도, 카테고리가 포함되어 있는 데이터를 추출하였다. 포스퀘어에서는 사용자들이 작성한 베뉴, 팁, 그리고 사용자 정보에 대하여 API를 통한 접근을 제공하고 있다. 포스퀘어 API에 대한 접근은 다양한 프로그래밍 언어로 가능하며 본 연구에서는 파이썬을 사용하였다. API를 통해 얻을 수 있는 정보로는 베뉴, 사용자 관계, 팁, 체크인 이력 등을 라이브러리를 활용한 프로그램을 통하여 수집할 수 있다. 파이썬에서 웹 인터페이스를 통하여 URL에 검색 코드를 입력하고 검색 결과 획득한 ‘JSON’ 형식의 데이터로부터 연구에 필요한 데이터를 추출하였다. 서울시 종로구를 대상으로 포스퀘어 데이터를 추출한 결과는 그림 4와 같다.
2. 명칭쌍 생성
두 번째 단계에서는 레벤슈타인 거리를 계산하기 위한 명칭쌍을 생성하였다. 명칭쌍 생성 이전에 두 가지 조건을 주어 데이터를 필터링하였다. 첫 번째 조건에서는 포스퀘어의 체크인 수, 팁 수, 유저 수가 0인 데이터는 무의미한 데이터에 해당하므로 이를 제거하였다. 두 번째 조건에서는 명칭쌍 간 공간 거리를 계산하여 기존에 구축된 POI와 가까이 위치한 데이터를 선택하였다. 국가 관심지점 POI를 기준으로 반경 간격을 조정하면서 해당 반 경 내에 있는 명칭쌍의 수를 분석하고 그 수가 급속히 줄어드는 구간을 임계 반경으로 설정하였다. 본 연구에서는 명칭쌍 수가 급속히 줄어드는 50m를 임계 반경으로 설정하였다. 이러한 임계 반경을 만족하는 데이터를 추출하기 위해 기존에 구축된 POI 각 점들과 포스퀘어의 각 점들 간 거리를 계산하였다. 계산에 앞서 POI와 포스퀘어의 좌표계를 UTM-K로 통일하였다. 이 때 포스퀘어의 WGS84 좌표계를 UTM-K 좌표계로 변환하고 데이터 프레임에 추가하였다. 이와같이 데이터가 모두 정리되면 POI와 포스퀘어 각 지점 간의 유클리드 거리를 계산한다. 거리 계산에는 sklearn.neighbor 라이브러리의 유클리디언 거리를 이용하였다. 거리 계산 결과 POI와 포스퀘어 데이터 간 거리가 50m 이내인 데이터를 선택하였다. 이와 같은 필터링 과정을 거친 데이터를 대상으로 명칭쌍을 생성하고 레벤슈타인 거리의 계산에 적용하였다.
3. 레벤슈타인 거리 계산
세 번째 단계에서는 앞서 생성한 명칭쌍의 문자열 유사도 측정을 위해 레벤슈타인 거리를 계산하였다. 레벤슈타인 거리를 구하는 구체적인 과정은 다음과 같다.
우선 numpy 라이브러리를 이용해 [문자열 길이 + 1][문자열 길이 + 1] 만큼의 2차원 배열을 만들었다. [0][n]과 [n][0] 배열 모두 0부터 문자열 길이만큼 초기화하였다. 여기서 두 문자열의 첫 단어가 같으면 0을 부여하고, [i – 1][j – 1] + 0만큼을 [i][j]에 부여하였다. 첫 문자열의 단어와 두 번째 문자열의 단어가 다르면 두 번째 단어를 제거해야 하므로 [i – 1][j] + 1 = [i][j]에 부여하였다. 두 문자열 간의 단어의 개수가 적으면 한 단어를 더 추가시켜야 하므로 [i][j – 1] = [i][j]를 부여하였다. [i][j]는 위의 세 경우 중 가장 값이 적은 것을 부여하였다. 마지막으로 [배열 크기 – 1] [배열 크기 – 1]만큼의 값을 반환하였다. 이 값이 레벤슈타인 거리이다. 계산된 레벤슈타인 거리를 데이터 프레임에 추가하여 그 값을 통해 유사도를 측정하였다.
레벤슈타인 거리 계산 결과 명칭쌍의 문자열이 유사하면 기존 POI와 같다고 판단하여 해당 명칭쌍은 삭제하고 그렇지 않으면 새로운 POI로 구축하였다. 기존 POI와 포스퀘어 데이터의 명칭쌍 중 유사성이 낮은 포스퀘어 데이터를 POI로 구축하였다.
4. 관심지점 데이터 구축
본 단계에서는 새로운 POI를 구축하기 위해 기존 POI 데이터에 레벤슈타인 거리에 의해 추출된 포스퀘어 데이터를 병합하였다. 이에 따라 새로운 POI로 구축될 포스퀘어 데이터 프레임을 생성하였다.
레벤슈타인 거리 데이터 프레임 내에 중복된 필드 이름들은 제거하고 위도와 경도, 체크인 수, 유저 수, 팁 수, 카테고리 수의 필드를 추가하였다. 이 과정에서 매핑 메서드를 사용하였다. 매핑 메서드란 시리즈나 데이터 프레임의 개별 원소를 특정 함수에 일대일 대응시키는 과정을 의미한다. 모든 필드의 값들이 추가되어 csv 파일로 저장하였다.
다음은 기존 POI 데이터와 결합하는 과정으로, 이 과정에서 어펜드 메서드를 사용하였다. 어펜드 메서드란 데이터 프레임을 병합하는 함수로 본 모델에서는 기존 POI와 추출된 포스퀘어 데이터를 열 이름을 기준으로 결합하는 것이다. 어펜드 메서드를 적용하기 위해 필요한 필드(포스퀘어 이름(베뉴), 위도, 경도)만을 남기고 다른 필드들은 삭제하였다.
이러한 과정을 거처 본 연구에서 개발한 모델을 적용한 결과 서울시 종로구 전체 POI 데이터 33,537건에서 이상치를 제거한 후 26,609건이 추출되었고 포스퀘어 데이터 23,832건이 추가되었다. 새로 구축된 데이터는 총 50,345건으로 기존 POI 데이터에서 47.14%가 추가되었다(표 1).
표 1.
POI 구축 모형에 따른 결과
| 연산 과정 | POI 데이터 개수 | 포스퀘어 데이터 개수 |
| 데이터 추출 | 33,537 | 25,472 |
| ↓ | ||
| 이상치 제거 | 26,609 | 25,472 |
| ↓ | ||
| POI 구축 모델 적용 | 26,609 | 23,832 |
| ↓ | ||
| POI 구축 | POI 데이터 + 포스퀘어 데이터 = 50,345 | |
새로 구축된 데이터는 ArcGIS로 시각화한 결과는 다음 그림과 같다. 그림 5에서는 포스퀘어 데이터로부터 추출한 POI 후보의 위치를 표현한 것이며, 그림 6에서는 기존의 국가 POI (그림 3)에 POI 후보(그림 5)를 합친 결과이다. 시각화 결과 기존 POI 데이터에 추가된 포스퀘어 데이터가 가시적으로 드러나는 것을 확인할 수 있었다. 모델 구축 시와 마찬가지로 대부분의 포스퀘어 데이터가 추가된 것을 알 수 있는데 포스퀘어 데이터는 사용자가 직접 생성하였지만 본 연구의 기존 POI는 국가 관심 지점으로서 공공기관이 보유한 주요 지형지물의 위치정보를 나타내고 있기 때문으로 판단된다.
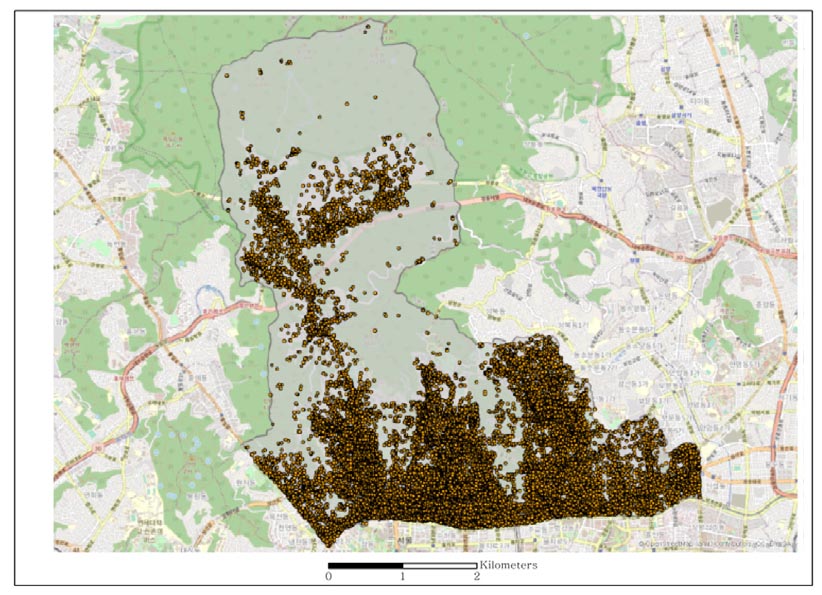
5. 관심정보 구축모델의 정확도 평가
본 절에서는 종로구의 국가 POI와 포스퀘어 데이터를 POI 구축 모델에 적용하고 정확도 평가를 수행하였다. 위치 정확도를 평가하기 위해 구글(Google)의 지오코딩(geocoding) API를 사용하였다. 지오코딩이란 주소 및 고유명칭을 가지고 위도와 경도의 좌표값을 얻는 것을 칭한다. 구글이 지원하는 지오코딩 API는 입력한 위치의 주소와 우편번호, 지오메트리(위도, 경도, 위치의 정확도)를 제공한다. 따라서 구글 지오코딩 API를 이용하여 POI로 구축된 포스퀘어 데이터의 위치 정확도를 추출하였다.
POI로 구축된 포스퀘어 데이터의 주소 정보가 미흡하여 위도, 경도 데이터로 주소 정보를 추출하는 역 지오코딩(Reverse Geocoding)을 수행한다. 추출된 주소 정보를 다시 지오코딩하여 위치 정확도를 추출한다. 이는 포스퀘어 데이터의 위경도 값을 기준 가장 가까운 주소 정보(건물 정보)를 찾도록 판단하는 기능을 사용한 것으로, 초기 포스퀘어 위경도 좌표값과 다를 수 있다.
위치 정확도의 결과는 네 가지로 ‘ROOFTOP’, ‘RANGE_INTERPOLATED’, ‘GEOMETRIC_CENTER’, ‘APPROXIMATE’로 나타난다. ‘ROOFTOP’은 지오코딩 결과, 주소 정밀도까지 파악하여 위치 정보가 있는 정확하다는 것을 의미한다. ‘RANGE_INTERPOLATED’는 지오코딩 결과가 도로 위에 위치한다는 것을 의미한다. 일반적으로 도로 주소에 대해 ‘ROOFTOP’을 사용할 수 없을 때 출력된다. ‘GEOMETRIC_CENTER’는 지오코딩 결과가 지역(폴리곤)의 기하학적 중심에 위치한다는 것을 의미한다. 마지막으로 ‘APPROXIMATE’는 지오코딩 결과가 정확하지 않다는 것을 의미한다.
POI로 구축된 포스퀘어 데이터를 지오코딩한 결과 전체 데이터 23,832개에서 ‘ROOFTOP’이 22,413개로 94.05%, ‘GEOMETRIC_CENTER’가 665개로 2.79%, ‘APPROXIMATE’가 740개로 3.10%, 지오코딩이 되지 않은 데이터 14개로 0.06%로 나타났다(표 2). 위치 정확성 평가 결과 대부분의 데이터가 ‘ROOFTOP’으로 나타나므로 본 모델에서 POI로 구축된 포스퀘어 데이터는 위치 정확도가 유의미하다고 판단할 수 있다.
이와 같이 서울시 종로구의 국가 POI와 포스퀘어 데이터를 개발된 POI 구축 모델에 적용하고 위치 정확도를 이용하여 평가한 결과 유의미한 결과를 보이고 있다. 즉, 본 연구에서 개발한 POI 구축 모델은 정확도 측면에서 어느 정도 활용 가능성이 높다고 할 수 있다.
V. 결론
본 연구는 POI의 구축 과정에 소요되는 시간과 비용이라는 한계점을 보완하기 위한 방안으로 LBSNS인 포스퀘어를 활용하여 POI의 구축 모델을 개발하였다. 현재 구축과 갱신에 있어 제약이 따르고 있는 POI 데이터는 시간과 비용, 지도의 정확성, 위치 정보 유지 관리의 문제라는 한계점이 존재하고 있다. 따라서 본 연구는 위와 같은 POI 문제 중 시간과 비용의 문제를 해결하기 위한 방안을 제시하고자 하였다.
본 연구에서의 POI는 국가 관심 지점으로 한정하고, 국가 관심 지점을 LBSNS 데이터와 융합시키는 효과적인 POI 구축방안을 제안하고자 하였다. 기존의 POI 구축 방법에서 수반되는 시간과 비용의 문제를 보완할 수 있는 현시성의 특징을 가진 LBSNS를 고려하였다. 파이썬으로 기구축된 POI 데이터와 포스퀘어 데이터 간 명칭쌍을 생성하고 문자열 편집거리 기법을 적용하여 POI 구축 모델을 개발하였다. 개발된 모델을 서울시 종로구 지역의 데이터에 적용하고 그 효용성을 평가하였다.
모델 적용 결과 종로구 전체 POI 데이터에서 47.14%가 추가되었다. 구축된 모델을 평가하기 위해 구글 지오코딩 API로 위치 정확도를 평가한 결과 모델의 위치 정확도는 유의미하다고 평가된다. 본 연구는 LBSNS가 POI 구축 과정에서 나타나는 한계점을 보완할 수 있다는 것을 POI 구축 모델 개발로 입증하였다. 특히 본 연구의 모델은 시간과 비용을 크게 절감할 수 있음을 확인할 수 있었다. 또한 POI 검색 알고리즘과 POI 추천 등의 연구와 달리 속성 정보를 분석하여 상업 공간 분포가 어떤 차이가 있는지 지리적인 측면에서 분석할 수 있었다. 본 연구는 POI와 LBSNS 간 공간 정보 융합 방법을 제시하였다는 점에서 의의가 있다. 앞으로 LBSNS가 POI 구축 뿐만 아니라 사업체의 공간 분포 특성의 효용성을 제시한다는 점에서 LBSNS가 다방면으로 활용될 수 있을 것으로 기대한다.
