

I. 서론
II. 연구 자료 및 방법
1. 불균형 지수
2. 공간통계 방법론
III. 분석 결과 및 고찰
1. 소득분포의 지역 불균형 현황
2. 국내 월평균소득분포의 공간적 특성
IV. 요약 및 결론
I. 서론
현재 국내에서 추진되고 있는 「제 4차 국가균형발전 5개년 계획」 수립 배경에는 경제력 부문에서의 지역 간 불균형의 지속에 대한 관점이 한 축을 담당하고 있다. 이에 이를 해결하기 위한 “지역 주도의 분권형 균형발전 추진”을 통한 “분권”의 가치 구현 및 “국가균형발전 체계의 발전적 복원”의 “포용”의 가치 그리고 “지역 주도의 자립적 성장기반 마련 목표”의 “혁신” 가치를 계획에 반영ㆍ구현하고 있다(국가균형발전위원회, 2019). 이와 같은 정책추진의 현황과 결과를 파악하기 위해서는 국내 지역 간 불균형에 대한 현황 파악이 우선적 이뤄져야 할 것이다. 그러나 현재까지 지역 성장에 대한 중요한 통찰력을 얻을 수 있는 공간적 측면이 반영된(Rey, 2004) 경제력의 지역 간 불균형을 공간적 관점에서 분석한 연구가 많지 않아 지역 전략 수립이나 정책 시행 결과 평가에 어려움을 겪고 있다.
기존의 경제적 측면의 불균형에 대한 국내의 선행 연구들(유항근, 2004; 김진욱, 2004; 손병돈, 2009; 김영미·한준, 2007; 윤형호·임병인, 2012; 이순배·하채수, 2009; 정준호·전병유, 2017)은 대부분 불균형 지수 또는 불균형 지수의 분해(decomposition) 방법론이나 요인분해 방법론을 이용하여 소득 계층 간, 연령 간 또는 자산 등의 거시적 수준의 분석과 연구지역 내 불평등을 분석한 바 있으나 전국 단위에서 지역 간 지역 내 경제 수준의 불균형 및 그 공간적인 측면의 함의는 끌어내지 못했다.
경제적 측면의 국외의 많은 연구들(Fan and Casetti, 1994; Yao, 1997; Mishra and Parikh, 1992; Dagum, 1998; Akita et al., 1999; Förster et al., 2002; Tadjoeddin et al., 2003; Balisacan and Fuwa, 2003; Gray et al., 2004; Novotný, 2007)도 불균형지수의 분해 방법을 이용하여 연구대상 및 지역의 불균형에 대한 논의가 이루어졌으나 1990년대 후반 이후 지역 소득 수렴(Regional Income Convertgence) 및 불균형 연구에서 공간적 의존성과 공간적 이질성 등으로 대표되는 공간의 영향(spatial effects)의 유용성과 중요성을 알린 연구(Rey and Montouri, 1999; Fingleton, 2004; Rey, 2004)들이 발표된 이후 공간의 영향을 반영할 수 있는 방법론과 기존의 불균형 지수를 결합하여 각 하나의 방법에 의해서는 발견될 수 없는 중요한 지역 소득 수렴 및 공간적 불균형에 대한 의미들을 도출한 많은 연구들(Lin et al., 2015; Ezcurra et al., 2007; Paas and Schlitte, 2008; Fei and Chenghu, 2009; Ahmed, 2011; Rey, 2018; Mastronardi and Cavallo, 2020; Siddique and Khan, 2021)이 최근까지 지속해서 발표됐다.
이에 이 연구에서는 기존 연구에서는 접근, 분석하지 못한 미시적 공간 단위인 격자 단위(100m×100m)의 월평균 소득 빅데이터(KCB(Korea Credit Bureau) 빅데이터)를 바탕으로 하여 전국 대상의 시·군·구 단위, 시·도 단위 수준의 지역 내 격차를 분석하였으며 동단위로 집계된 자료를 이용 국내 소득 분포의 전역적 국지적 특성을 파악하여 다계층(multi-scale)적 유연계층(flexible-scale)적 관점에서(김동한 등, 2019)의 소득불균형에 대한 접근을 시도하였다. 또한 분석 방법론으로 일반적으로 소득불균형 연구에 사용되고 있는 불균형 지수(Inequality index)만이 아닌 공간의 영향(spatial effects)을 파악할 수 있는 공간통계적 방법론 또한 이용하여 국내 지역간 지역내 불균형에 대한 공간적 특성을 파악하였다. 이로써 국내 소득 불균형에 대하여 단편적인 접근이 아닌 입체적인 접근을 시도하여 기존연구들과의 차별화를 시도하였다. 이 연구에서 제시한 분석 방법론은 국내 지역간 지역내 불균형에 대한 공간적인 이해를 도와 국가균형발전 전략 수립 및 결과에 대한 평가 방안에 활용될 수 있을 것으로 기대한다.
II. 연구 자료 및 방법
이 연구에서 지역 간 지역 내 경제 수준의 지역내 공간적 불균형에 대한 함의를 이끌어 내기 위해 이용한 가계소득 빅데이터인 KCB(Korea Credit Bureau) 빅데이터는 KCB에 등록된 4,400만 개인신용정보 및 KCB가 수집한 정보(부동산 등)를 바탕으로 사람들이 활동하는 주소 지역을 기반으로 익명 처리한 데이터를 말한다(KCB, 2021). KCB 빅데이터셑 중 이 연구에서 이용한 월평균소득은 약 200만 명의 개인 급여소득자들의 건강보험료 납부내역, 국세청 소득증명원 등의 금융(신용)거래를 기반으로 KCB가 자체 모형으로 추정한 정보이다(김태환 등, 2021).
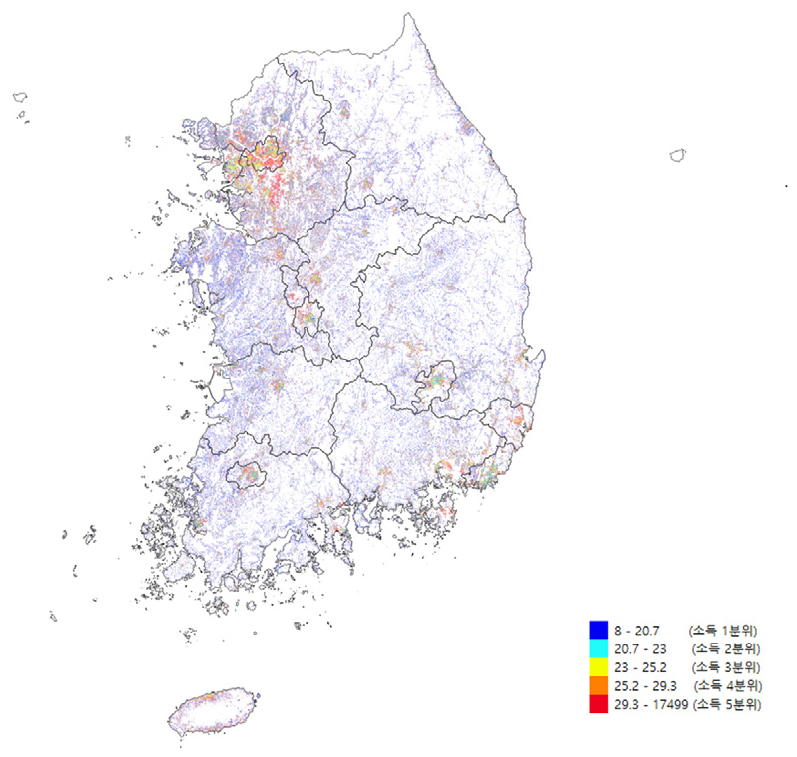
이 연구에서는 지역에 따른 소득 분포의 불균형성을 파악하기 위해 KCB 빅데이터(2019.06 기준, 월평균추정 총소득)를 기반으로 두 가지 측면으로 소득 분포의 불균형에 대한 접근을 시도하였다. 첫 번째는 소득 불균형에 대하여 불균형도를 측정할 수 있는 불균형지수들을 이용하여 지역 간 지역 내 불균형도를 측정하였다. 두 번째는 공간통계기법을 이용하여 공간적인 접근을 통해 국내 소득 분포의 공간적 불균형의 현황을 파악하고 시각화하여 국내 소득 불균형도에 대하여 입체적인 접근을 시도하였다. KCB 빅데이터 전처리와 불균형지수 계산은 R4.1.1 오픈소스 프로그램을 사용하였으며 ineq 패키지를 이용하여 타일지수 값과 앳킨슨지수값을 산출하였다. 격자 단위(100m×100m)의 원시데이터에는 각 격자 당 연령대별 인구와 이에 해당하는 소득정보가 주어져 있어 이를 정보를 이용하여 격자당 월평균 소득을 산출하여 연구를 수행하였다. 공간통계기법은 ArcGIS10.8 프로그램을 사용하였으며 지도를 통한 시각화는 QGIS3.20과 ArcGIS10.8 프로그램을 사용하였다. (그림 1)은 이 연구의 분석 단위인 격자(100m×100m) 단위의 소득 자료이며 분석 내용에 따라 전국 시・도, 시・군・구, 읍・면・동으로 집계한 자료를 이용하였다.
1. 불균형 지수
이 연구에서 사용된 불균형 지수는 앳킨슨(Atkinson) 지수(Atkinson, 1970)(식1)와 타일(Theil’s T)(Theil, 1967)지수(식2)이다. 앳킨슨( Atkinson) 지수는 균등한 분배에 따른 소득과 현 소득 간의 차이에 의한 불평등을 계산하여 소득분배가 불평등할수록 지수값은 커지게 되며 사회후생에 관한 불평등 지수중 하나로 많은 연구에서 사용되고 있다(최승훈 등, 2020). 앳킨슨(Atkinson) 지수는 0에서 1 사이의 값을 가지며 0이면 완전 균등, 1이면 완전 불균등을 의미한다. 이 연구에서 ε값은 0.5로 설정하였다.
타일지수(Theil's T)는 불평등을 측정하는 지표로 가장 널리 사용되고 있는 지표 중의 하나로 명확하게 집단 간 집단 내 불평등으로 분해하여 분석할 수 있는 장점을 갖는다(Liao, 2016). 타일지수는 모든 사람이 균등하게 같은 소득을 갖는다면 0이 되고 한사람이 모든 소득을 모두 갖는다면 의 값을 갖게 된다.
앳킨슨지수는 소득분포의 하위계층의 변화에 민감하고 타일지수는 상위계층의 변화에 민감하다고 알려져 있기 때문에 어떤 불균형지수를 이용하느냐에 따라 불균형에 대한 다른 주장을 펼칠 수 있어(김우철 등, 2006) 이 연구에서는 이 두 가지 지수 모두를 사용하여 연구를 진행하였다.
2. 공간통계 방법론
국내 소득 분포의 전역적인 공간 특성을 파악하기 위해 이 연구에서는 대표적인 공간적 자기상관성(spatial autocorrelation) 측도인 Moran’s I(Cliff and Ord, 1981)(식3)를 사용하였다. 국지적인 공간 특성을 파악하기 위해서는 국지적 공간 자기상관성 지표(LISA:Local Indicators of Spatial Association)중의 하나인 Local Moran’s I(Anselin, 1995)와 Gi*(Ord and Getis, 1995)를 사용하였으며, 각 측도의 식은 각 식(4), 식(5)와 같다.
・ Moran‘s I
・ local moran’s I
・ Getis-Ord Gi*
위 식에서 와 는 각각 지역과 지역에서 나타나는 속성값을, 는 전체 지역에 대한 속성값의 평균이다. 는 지역과 지역 사이의 관계를 나타내는 공간가중치를 의미한다.
III. 분석 결과 및 고찰
1. 소득분포의 지역 불균형 현황
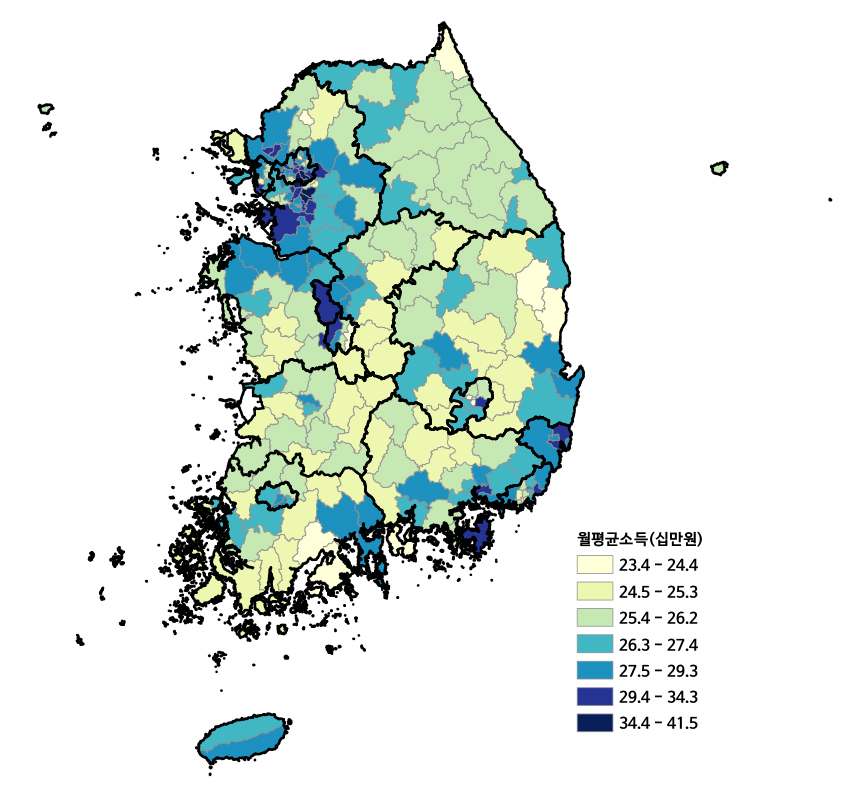
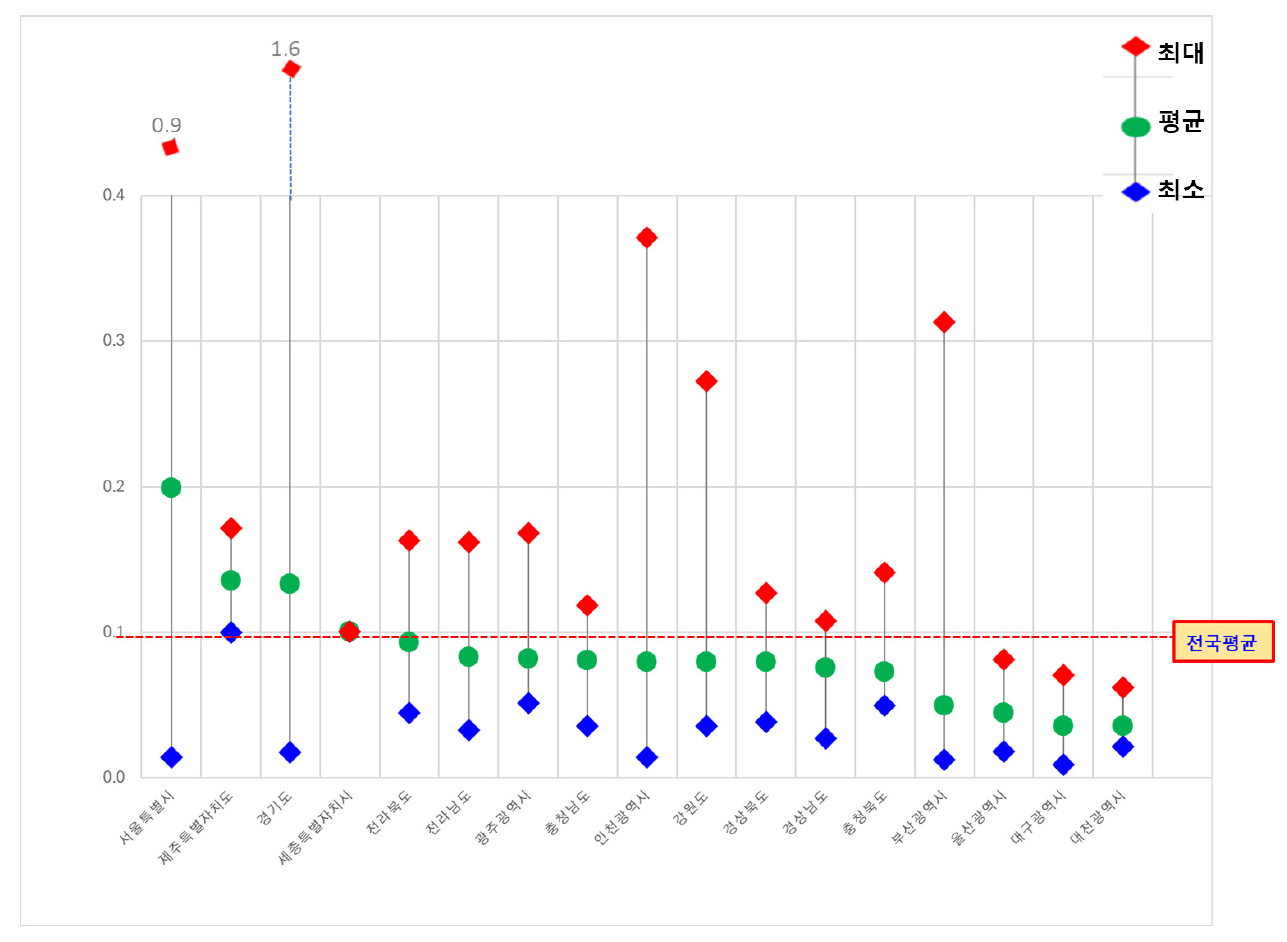
광역시・도별 월평균 소득은 세종특별자치시가 31.63(십만원)으로 가장 높게 나타났으며 울산광역시(29.87 십만원)와 서울시(29.71 십만원)가 그 뒤를 이었다(그림 2). 타일지수와 앳킨슨 지수로 살펴본 광역시・도별 월평균 소득 격차는 두 지수 모두 비슷한 상대적 수치를 나타내었고(그림 2) 서울이 타일 지수 0.260, 앳킨슨 지수 0.072로 가장 높게 나타났으며, 다음으로 제주, 경기도가 높게 나타났다. 월평균 소득이 높은 광역시・도일수록 타일지수가 높게 나타나는 경향을 보였으나 뚜렷하지는 않았다. 울산광역시는 상대적으로 소득이 높으나 타일지수 0.062 앳킨슨 지수 0.026으로 소득 수준이 비슷한 서울시의 소득 불균형 지수의 1/4 수준(타일지수 기준)으로 나타나 상대적으로 균형적인 소득 분포를 나타내었다(그림 2). 반면, 제주특별자치도는 비슷한 소득 수준인 충청북도, 광주광역시, 경상남도, 충청남도의 소득 불균형 수준의 2배 가까운 수치를(타일지수 기준) 나타내었다.

전국 시군구별 월평균 소득 분포는 (그림 3)과 같으며 수도권과 대전시, 세종시 중심의 중부권, 동남 해안권 지역에서 높게 나타났으며 강원권, 호남권, 경남북 내륙권 등에서 낮게 나타났다.
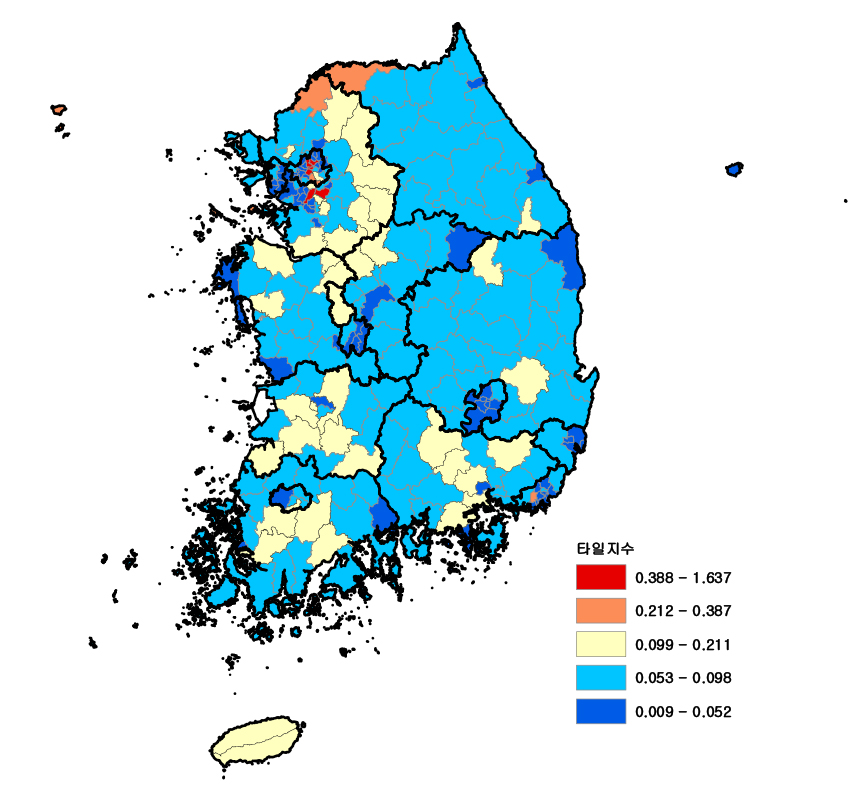
전국 시・군・구 단위의 타일지수를 통한 지역 내 소득 불균형 현황은 (그림 4)에 나타나 있다. 수도권 및 부산광역시 일부 지역에서 높은 수치의 타일 지수 값이 나타나고 있으며 경기도 내 외곽지역과 호남 일부 지역, 경남 내륙지역 등에서 시군구 단위의 평균적인 수치가 나타나고 있으며 그 외 지역에서는 다소 낮은 값이 나타나고 있다.
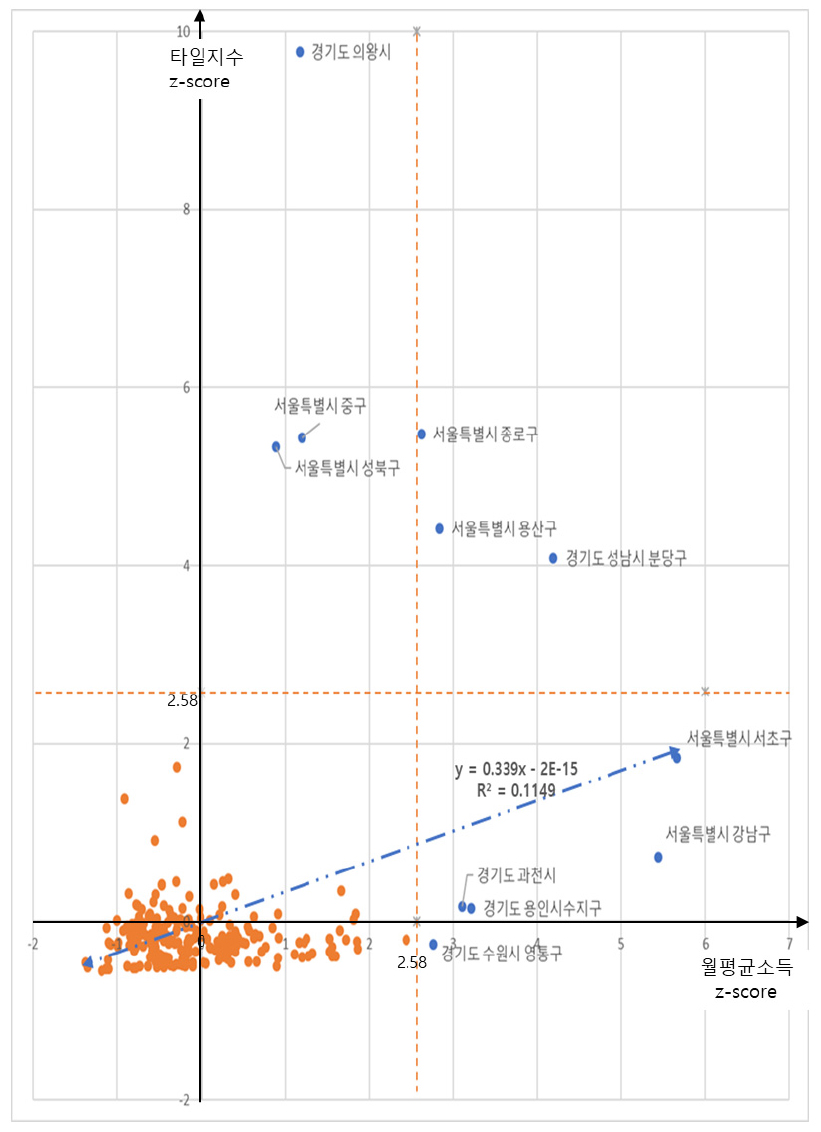
(그림 5)는 전국 시・군・구 단위로 월평균 소득과 타일지수와의 상관관계를 각 항목의 표준화 값(z-score)을 통해 분석한 결과를 도표화한 것이다. 시・군・구의 월평균 소득과 타일지수는 약한 양의 상관관계가 도출되었다. 각 항목별 상위 1% 이상에 해당하는 값(표준화 값 2.58 이상의 값)을 갖는 시군구는 다음과 같다. 타일지수를 기준으로 할 때 경기도 의왕시, 성남시 분당구, 서울특별시 중구, 성북구, 종로구, 용산구 등으로 나타났으며 월평균 소득을 기준으로 할 때 서울특별시 서초구, 강남구, 용산구, 종로구, 경기도 성남시 분당구, 용인시 수지구, 과천시, 수원시 영통구 등이 상위 1%에 해당하는 수치로 나타났다. 주목할만한 사실은 이들 모든 지역이 수도권지역이라는 점과 경기도 수원시 영통구만을 제외하고 모두 이상치(outlier)라 할 수 있는 표준화 값 3 이상인 지역이라는 점이다. 특히, 서울특별시 종로구, 용산구와 경기도 성남시 분당구는 타일지수 값과 월평균 소득 모두 상위 1%에 해당하는 높은 수치가 나타나 소득 수준이 높은 지역임에도 지역 내 소득 불균형 정도는 심각한 수준으로 보인다.
광역시・도 내 시・군・구간 타일지수 격차를 분석한 결과는 (그림 6)과 같이 나타났다. 경기도 내 시・군・구 간 타일지수 격차가 가장 크게 나타났으며 다음으로 서울특별시, 인천광역시 순으로 격차가 크게 나타나 수도권지역에서 큰 격차를 보였다. 이러한 결과는 수도권지역이 상대적으로 높은 소득을 보이는 지역으로 나타났었으며 격자 단위로 본 시・군・구 내 격차도 크게 분석되었다는 사실과 함께 고려한다면 어느 지역에서보다도 수도권지역에서 더욱 소득 계층 간 갈등 관리에 주의를 기울여야 한다는 점을 시사한다.
2. 국내 월평균소득분포의 공간적 특성
국내 월평균소득분포의 전역적인 공간적 특성을 살펴보기 위해 먼저 소득 분포의 공간적 자기상관성(spatial autocorrelation )을 Moran’s I 지수를 사용하여 측정하였다. 공간가중치를 계산하는 방법에 따라 Moran’s I 지수 값 및 그 유의성이 달라질 수 있으므로 이 연구에서는 공간가중치 임계거리를 주변 시군 간 및 시도 간 범위까지의 공간적 영향(spatial effects)을 살펴보기 위하여 20km에서부터 20km씩 증가시켜 80km까지 4개의 거리를 이용하여 Moran’s I 값을 산출하였으며 그 결과는 (표 1)에 나타나 있다. 4개의 임계거리에 따라 격자 단위의 월평균소득 자료를 동 단위로 집계한 자료를 이용하여 Moran’s I 지수 값을 산출한 결과 모든 거리에서 매우 유의미한 양의 공간적 자기상관성을 나타내었으며 20km의 임계거리에서 가장 큰 Moran’s I 값이 도출되었으며 Moran’s I 값에 대한 유의성은 거리에 따라 증가하여 80km에서 가장 큰 값을 나타내었다.
표 1.
거리에 따른 동 단위 월평균 소득에 대한 전역적 Moran’s I
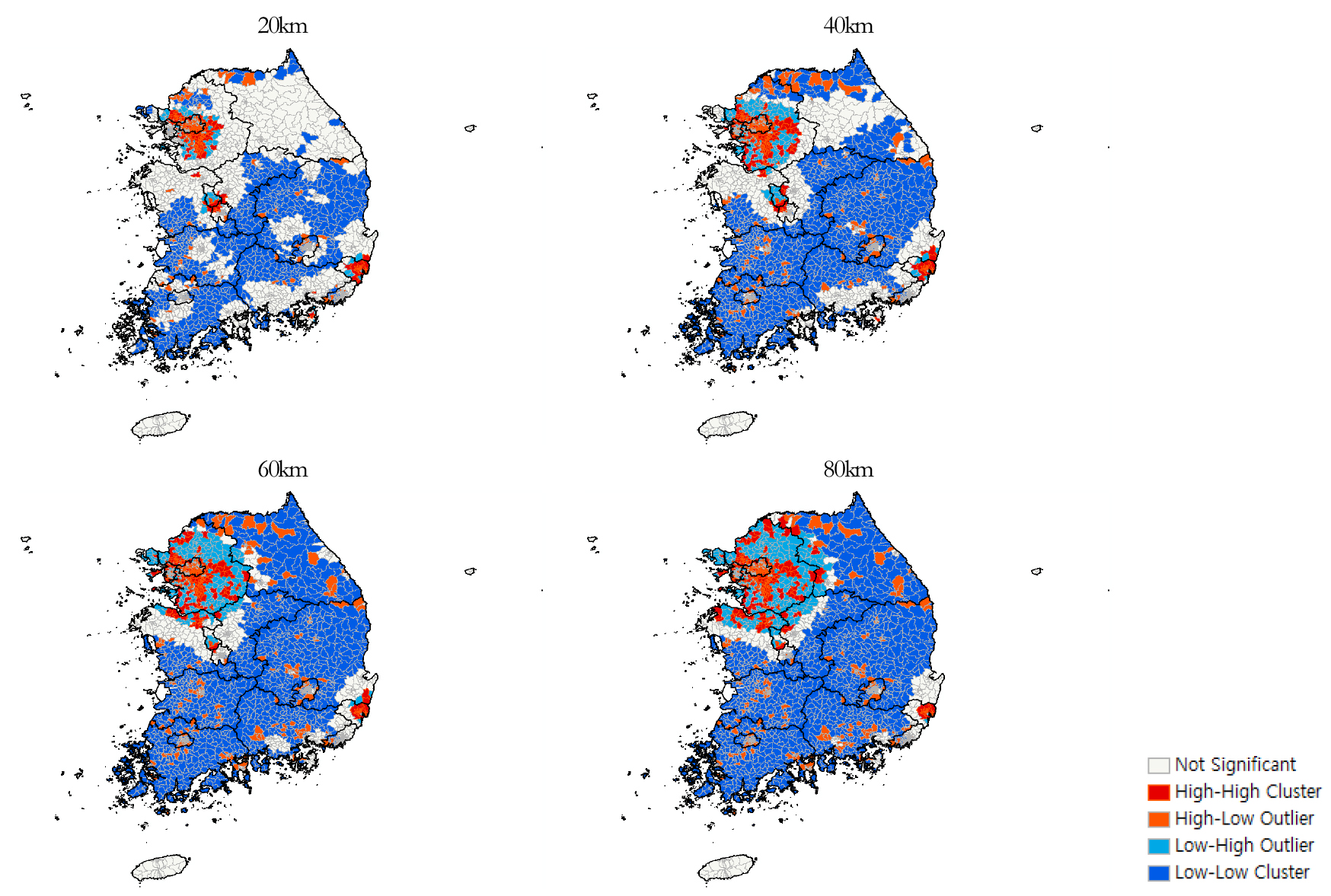
전역적인 공간분포의 특성에서 확인된 공간적 자기상관성의 구체적인 국지적 분포를 확인하기 위해서 대표적인 국지적 공간적 자기상관성 측도인 Local Moran’s I 지수를 이용하여 국지적 공간분포의 특성을 파악하였다. Moran’s I 지수 값 계산에서와 마찬가지로 Local Moran’s I 지수계산에서도 사용되는 공간가중치를 계산하는 방법은 다양하고 각 방법에 따라 다양한 결과가 도출될 수 있으며 그 해석 또한 달라질 수 있으므로 이 연구에서는 다양한 Moran’I 계산 시와 마찬가지로 20km 단위의 4개의 임계거리를 이용한 공간가중치를 이용하여 그 결과를 도출하였다.
다양한 임계거리에 의한 공간가중치 설정에 따른 Local Moran’s I 지수 분석 결과는 (그림 7)에 나타나 있다. Local Moran’s I의 유용성은 공간적 클러스터(spatial clusters) 및 공간적 이상치(spatial outliers)를 파악할 수 있다는 점에 있다(Boberg et al., 2018:425).이 연구 결과에서도 임계거리가 증가할수록 주로 서울과 서울 동남부의 경기도 내 지역에서 해당 지역과 그 주변 지역 모두가 높은 소득 값을 갖는 HH(High-High)지역이 군집해 나타났으며 비수도권 전역에서는 해당 지역과 그 주변 지역이 모두 낮은 소득 값을 갖는 LL(Low-Low) 지역이 군집하는 경향이 두렷이 나타나는 공간적 클러스터를 파악할 수 있었다. 또한 공간적 이상치(spatial outliers)라 할 수 있는 LH(Low-High) 지역이 서울 외곽지역의 경기도 내 및 강원도 서부, 충청남도 북부 및 충청북도 서부지역에서는 군집해 나타나는 경향이 확인할 수 있었다. 주목할만한 사항은 경기도 내에서는 HH 지역과 LH 지역이 뚜렷이 혼재되어 나타난다는 점이며 이는 전 절에서 분석된 경기도 내의 시군구간 타일지수의 격차가 가장 크게 나타난 결과를 공간적으로 확인한 것이라 할 수 있다. 또한, 경기도와 인접한 충남 북부, 충북 북서부, 강원 서부 지역들에서도 HH 지역과 LH 지역이 혼재되어 나타나고 있는 점도 유의 할 만하다.
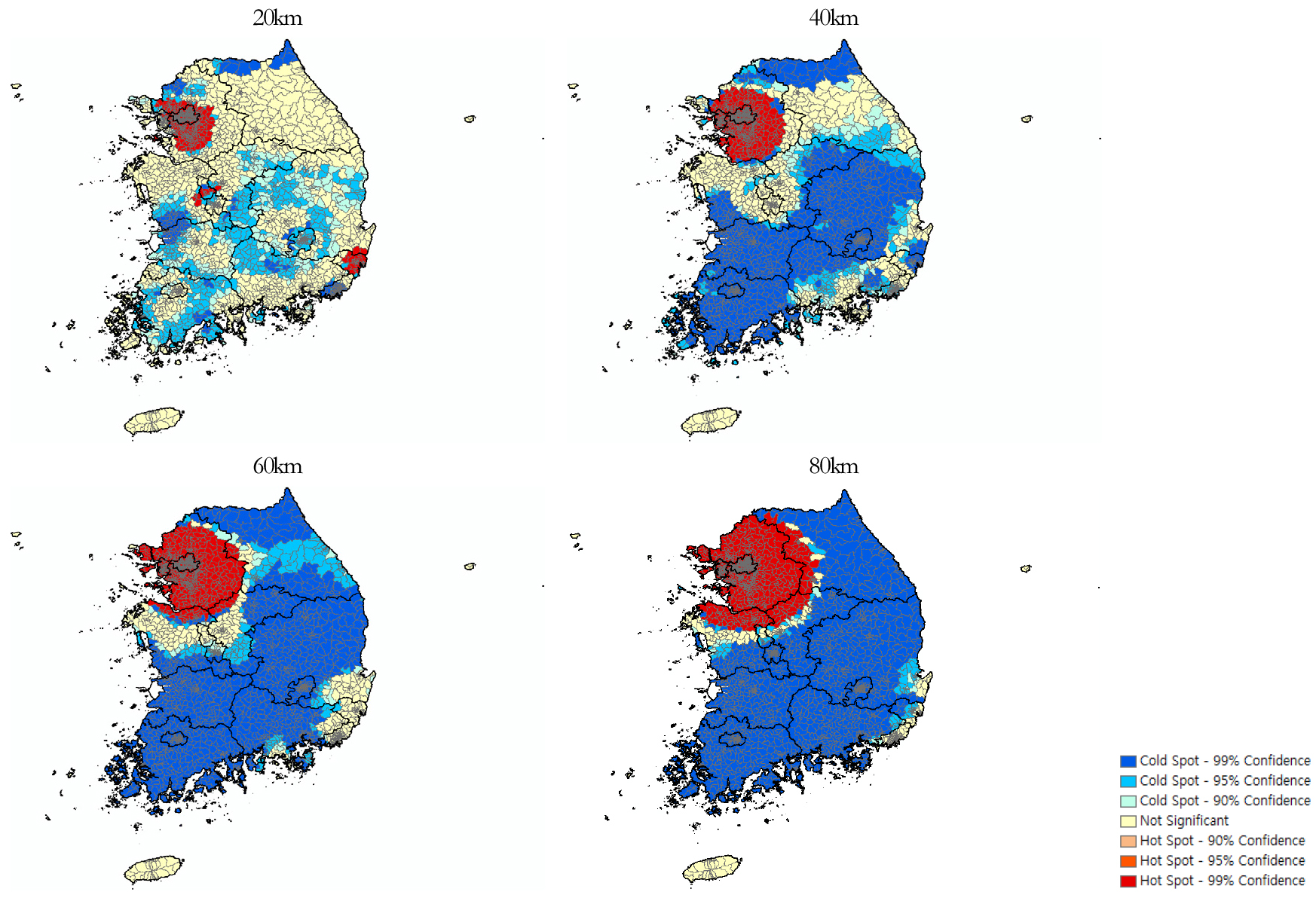
Local Moran’s I 지수는 공간 군집성(spatial clustering)의 정도나 군집 패턴을 파악하는 데 약점이 있을 수 있으므로(이상일 등, 2015) 지수를 이용하여 국내 월평균 소득 분포의 공간적 군집 패턴을 파악하였다. 지수는 높은 값들의 군집(high value clusters:hot spot)과 낮은 값들의 군집(low value clusters:cold spot) 지역을 찾는 데 장점을 갖고 있으므로 (Bagstad et al., 2017), 지수를 활용하여 임계거리에 따른 높은 월평균 소득의 핫스팟(hot spot)지역과 콜드스팟(cold spot)지역을 탐색하였다. 값을 통해 4개의 임계거리(20km, 40km, 60km, 80km) 범위 내에서의 통계적으로 유의미한 공간적 군집성(높은 값:핫스팟, 낮은 값:콜드스팟)을 파악한 결과 (그림 8)과 같이 나타났다. 임계거리가 40km 이상에서부터 높은 소득을 갖는 지역들은 수도권에 낮은 소득을 갖는 지역들은 비수도권 전역에 군집되어 있는 현상이 나타나 수도권과 비수도권의 국내 월평균소득 분포의 공간 불균형이 뚜렷이 나타났다.
IV. 요약 및 결론
이 연구는 격자 단위(100M×100M)의 가계소득 빅데이터(2019.06 기준, 월평균 추정 총소득)를 기반으로 국내 소득 불균형에 대하여 불균형지수들을 이용하여 전국을 대상으로 지역 내 지역 간 불균형도를 측정 평가하였고 공간통계기법을 활용하여 국내 소득 분포의 공간적 불균형의 현황을 파악하고 시각화하여 국내 소득 불균형에 대하여 입체적인 접근을 시도하였다.
타일지수와 앳킨슨 지수를 이용하여 국내 지역 내 불균형도를 측정한 결과 광역시・도 단위에서는 서울특별시가 가장 높게 나타났으며 월평균 소득이 높은 광역시・도일수록 타일지수가 높게 나타나는 경향이 있었으나 뚜렷하진 않았다. 같은 소득 수준이라도 서울특별시가 울산광역시보다 타일지수가 4배 높게 나타났으며 제주특별자치도는 비슷한 소득 수준을 보인 시・도보다 2배 가까이 높게 나타났다. 이는 국내 광역시・도의 경제력 수준을 높이는 것만큼 지역 내 격차 해소를 위한 정책적 노력이 필요하다는 점을 시사한다.
지역 소득 격차를 광역시・도 내 시・군・구간 타일지수 격차로 파악한 결과 경기도 내 시・군・구가 가장 큰 격차를 보였으며 서울특별시, 인천광역시가 그 뒤를 이었다. 격차가 큰 3대 광역시・도가 모두 수도권으로 나타났다. 이와 더불어 소득과 타일지수가 모두 이례적으로 높은 시・군・구가 모두 수도권 지역임을 고려하면 수도권 지역에서 소득 계층 간의 갈등 문제가 심화될 가능성이 높을 수 있어 이에 대한 정책적 대응 방안 마련이 시급하다 볼 수 있다
국내 월평균소득분포의 전역적인 공간적 특성을 격자 단위의 소득 자료를 동 단위로 집계한 자료를 이용하여 Moran’I 자수를 통해 파악한 결과 공간가중치의 임계거리 20Km, 40Km, 60Km, 80km 모두에서 매우 유의미한 공간적 자기상관성이 확인되었다. Local Moran’s I 통해 파악된 국내 월평균소득분포의 국지적인 분포의 특성은 수도권 중심으로 HH(High-High) 지역이 비수도권 중심으로 LL(Low-Low) 지역이 군집 되어 나타났으며 공간적 이상치(spatial outliers))라 할 수 있는 LH(Low-High) 지역이 서울 외곽지역의 경기도 내 및 강원도 서부, 충청남도 북부 및 충청북도 서부지역에서는 군집해 나타나는 경향이 확인할 수 있었다. 경기도 내에서는 HH(High High) 지역과 LH(Low High) 지역이 모두 집적되어 나타나 상대적으로 큰 경기도 내의 지역 내 소득 격차가 공간적으로 확인되었다. 또한 지수를 이용하여 국내 월평균 소득 분포의 공간적 군집 패턴을 파악한 결과 수도권과 비수도권의 국내 월평균소득 분포의 공간 불균형이 뚜렷이 확인되었다.
상기와 같은 국내 소득 소득 분포에 대한 지역 내, 지역 간 불균형 및 전역적, 국지적 공간분포 특성 결과들은 국토의 불균형을 바로 잡아야 할 중앙 정부와 지역의 불균형을 개선해야 할 지방 정부 모두에게 균형발전 정책 수립에 대한 큰 시사점을 제공한다 볼 수 있다. 또한 시계열적인 분석 결과들이 마련된다면 정책 결과에 대한 평가 방안에도 활용될 수 있을 것이다.
이 연구에서는 격자 단위의 소득 빅데이터를 이용하여 광역시・도 내, 광역시・도 내 시군구 간의 소득 격차를 분석하고 격자 자료를 동 단위로 집계한 소득 자료를 통해 전역적, 국지적 소득 분포의 특성을 파악하였다. 이 연구는 피상적인 국내 소득 불균형의 수도권과 비수도권의 격차가 크다는 단일한 결과만을 도출한 것이 아니라 미시적 스케일의 빅데이터 분석을 통해 수도권 지역내의 시군구 안에서의 격차 또한 크다는 결과를 도출하여 국내 소득 불균형에 대한 논의를 권역 단위가 아닌 시군구 단위로 확장 시켰고 수도권과 비수도권의 격차 또한 공간적으로 명확하게 시각적으로 보여줬다는 점에 의의가 있다. 이 같은 결론은 과거의 1970-80년대 경부축 중심의 산업화와 이후 수도권지역으로의 지식산업과 서비스업의 집중으로(구양미, 2021) 대표되는 거점 개발 방식의 국토 개발로 인한 비균형적 국토 개발의 부작용이 현재까지도 이어지고 있으며 또한 거점과 비거점 간의 불균형뿐만 아니라 거점 안에서의 불균형에 대한 문제 해결에도 정책적 노력이 필요하다는 점을 시사한다 볼 수 있다. 이 연구는 그동안 자료의 한계 또는 방법론의 한계로 인한 전국 단위에서의 지역 간 지역 내 소득 불균형에 대한 분석이 어려웠던 점을 극복하여 격자 단위의 빅데이터와 공간통계기법을 이용하여 미시적 스케일로 전국 단위의 분석을 시도하였다는 점에서도 그 의의가 있을 것이다. 그러나 원자료의 소득 데이터가 금융신용거래 분석을 통한 추정 소득 자료이기 때문에 금융신용거래를 활발히 하지 않는 소득 계층의 대표성이 떨어진다는 점은 이 연구가 갖는 한계라 할 수 있다.
