

I. 서론
전지구적인 기온 상승은 대기 중의 수증기 양을 증가시켜 강수 패턴에 변화를 가져오고 홍수 등 재해 발생을 증가시키고 있다(Tabari, 2020). 기후변화와 함께 미국에서는 지난 반세기 동안 꾸준히 홍수가 증가하였고(Global Change Research Program, 2018), 또한 동남아시아는 열대 몬순의 영향으로 항상 홍수 피해가 심해 최근 국제기상기구(World Meteorological Organization, WMO) 주도로 Southeast Asia Flash Flood Guidance System (SeAFFGS)가 출범하기에 이르렀다(WMO, 2022). 우리나라에서도 2020년 기록적인 장마와 집중호우로 홍수와 산사태가 발생하여 14명이 사망하고, 1천여 명의 이재민이 발생한 바 있다(이승수 등, 2020).
위성원격탐사는 광역적인 홍수 감시의 수단으로 활용되고 있는데, 특히 합성개구레이더(Synthetic Aperture Radar, SAR)는 광학센서와 달리 구름을 투과하여 관측하기 때문에 우천 시에도 홍수 탐지가 가능한 장점이 있다(Tay et al., 2020). 일반적으로 지표면은 수표면에 비해 상대적으로 거칠기(roughness)가 크기 때문에 SAR의 후방산란(backscattering)이 더 많이 발생하고, 수표면은 후방산란계수가 낮은 값으로 나타나는데(Martinis et al., 2015), 이러한 후방산란 특성을 이용하여 SAR 영상으로부터 수체를 식별함으로써 홍수 탐지를 수행할 수 있다.
기존의 연구들은 대부분 SAR 후방산란계수에 적절한 임계치를 적용하여 수체를 식별하였으나(Liang and Liu, 2020), 최근 딥러닝 영상인식 기술인 Convolutional Neural Network (CNN)가 원격탐사에 널리 활용되면서, 기존의 임계치 의존적인 기법보다 더 나은 홍수 탐지 성능을 보여주고 있다(Li et al., 2019; Nemni et al., 2020). 실제로 딥러닝 영상인식의 성능에 가장 결정적인 영향을 미치는 것은 학습자료의 양과 질이다. 지금까지 홍수 탐지를 위한 충분한 SAR 영상 학습자료가 구축되지 못하여, 선행연구들에서는 적은 수의 영상으로 딥러닝 홍수 탐지 실험을 해왔으나, 최근 미국 항공우주국(National Aeronautics and Space Administration, NASA)에서 Sentinel-1 SAR 영상으로 구축한 대용량의 홍수 탐지 학습자료를 공개함으로써(Gahlot et al., 2021) 딥러닝 홍수 탐지를 위한 새로운 전기를 맞이하게 되었다.
이에 본 연구에서는 NASA Flood Extent Detection 학습자료를 사용한 홍수 탐지를 수행하기 위해서 딥러닝 모델을 최적화하여 구축하고, 암맹평가를 통해 탐지 성능을 확인하며, 우리나라 홍수 탐지에 대한 적용가능성을 검토하고자 한다. 이 실험은 홍수가 빈번히 발생하는 미국과 동남아시아의 데이터셋을 대상으로 하였지만, 현재 정부에서 구축하고 있는 우리나라 홍수 영상 데이터베이스와 함께 활용될 수 있을 것이다.
II. 자료와 방법
1. 사용 자료
사용된 영상은 Machine Learning Hub (MLHub) 사이트에서 제공하는 NASA Flood Extent Detection 데이터셋으로, Sentinel-1A와 Sentinel-1B 영상으로 구성되었다. Sentinel-1은 European Space Agency (ESA)에서 운영하는 쌍둥이 위성으로, C 밴드(5.405 GHz) SAR를 탑재하고 있으며, 자료획득 방식에 따라 Strip Map (SM), Interferometric Wide Swath (IW), Extra-Wide Swath (EW), Wave (WV) 4가지 모드로 구분된다. 단일 편파(single polarization)과 이중 편파(dual polarization)가 모두 가능하기 때문에, HH, VV, HH+HV, VV+VH의 4가지의 편파 영상을 제공한다. 1A, 1B가 각각 12일의 재방문주기를 가지므로, 두 위성이 교호하여 6일의 시간해상도를 가질 수 있다. MLHub 사이트의 NASA Flood Extent Detection 데이터셋은 미국과 동남아시아에서 2017년부터 2019년까지 발생한 대규모 홍수에 대한 10m 해상도의 Sentinel-1 영상이며, 본 연구에서는 이를 256×256 화소의 영상 724장으로 변환하여 사용하였다(그림 1).

2. 탐지 모델
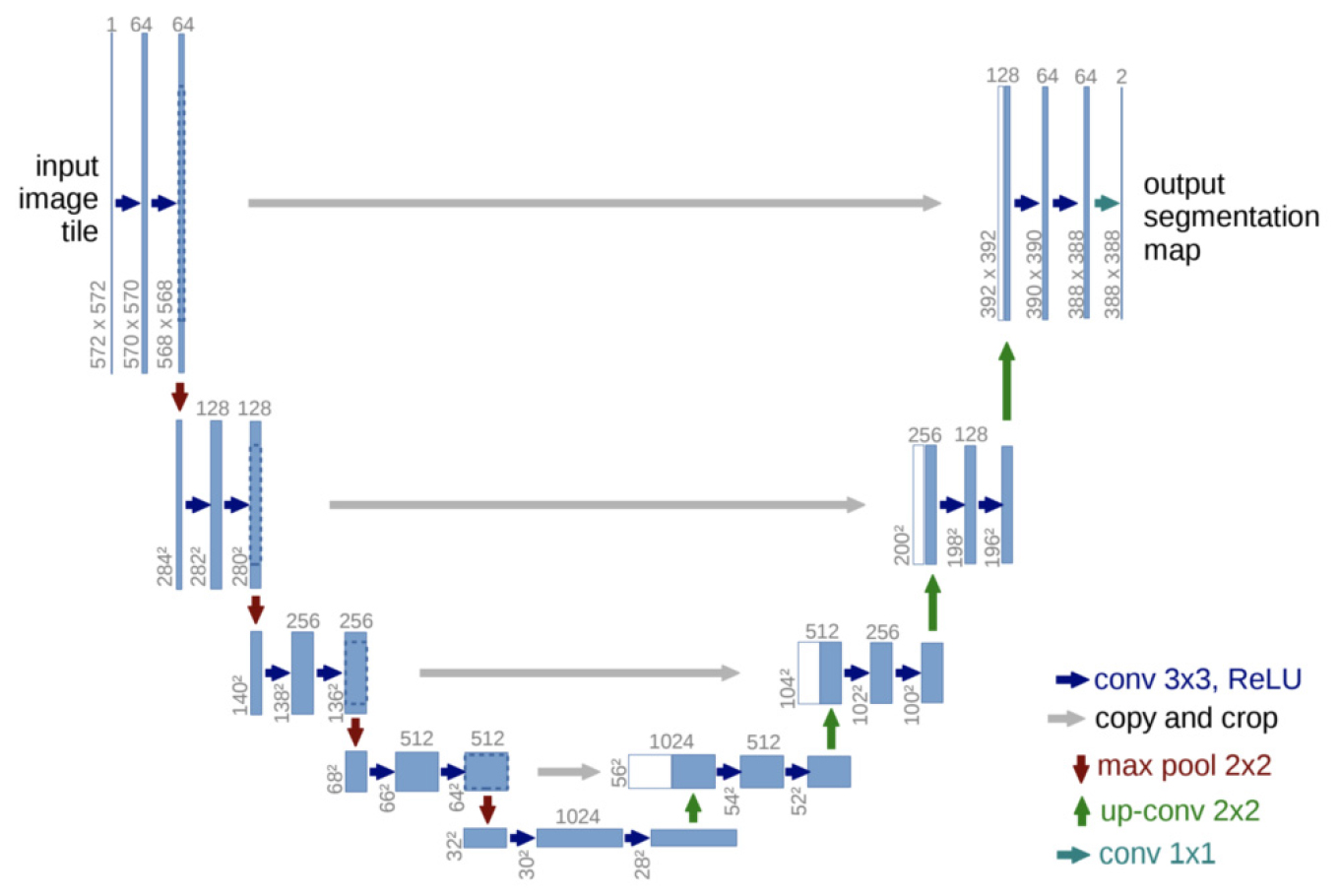
컴퓨팅 파워의 발전과 함께 CNN은 효율적인 활성함수(activation function)와 옵티마이저(optimizer)를 활용한 특징맵(feature map) 생성을 통해 영상인식에 있어 보다 높은 정확도와 생산성을 보이고 있다. CNN은 컨볼루션 레이어(convolution layer)가 이동창 방식으로 영상의 특징을 추출하고 풀링 레이어(pooling layer)가 이를 요약한 특징맵을 만들어 활용하는 방식이다(Huang et al., 2017). Ronneberger et al.(2015)은 기존 CNN의 완전연결층(Fully Connected Layer, FCL) 구조를 수정하여 의미론적 분할(semantic segmentation)이 가능한 U-Net 모델을 개발하였다. U-Net은 좌측의 인코딩 경로(encoding path)와 우측의 디코딩 경로(decoding path)가 이어져 U자 형태를 이룬다(그림 2). 인코딩 경로에서 다운샘플링(down-sampling) 시에는 일반적인 CNN처럼 컨볼루션과 풀링을 반복하면서 특징맵을 추출한다. 디코딩 경로에서 업샘플링(up-sampling) 시에는 기존 CNN과 달리 스킵커넥션(skip connection)을 수행하는데, 이는 다운샘플링 과정에서 만들어진 특징맵을 해당 업샘플링 구간에 전달하여 병합 사용하는 메커니즘이다. U-Net 모델은 화소군의 로컬리티(locality)를 공간적 맥락에 부합하도록 구성하여 의미론적 분할의 정교함을 개선하였다.
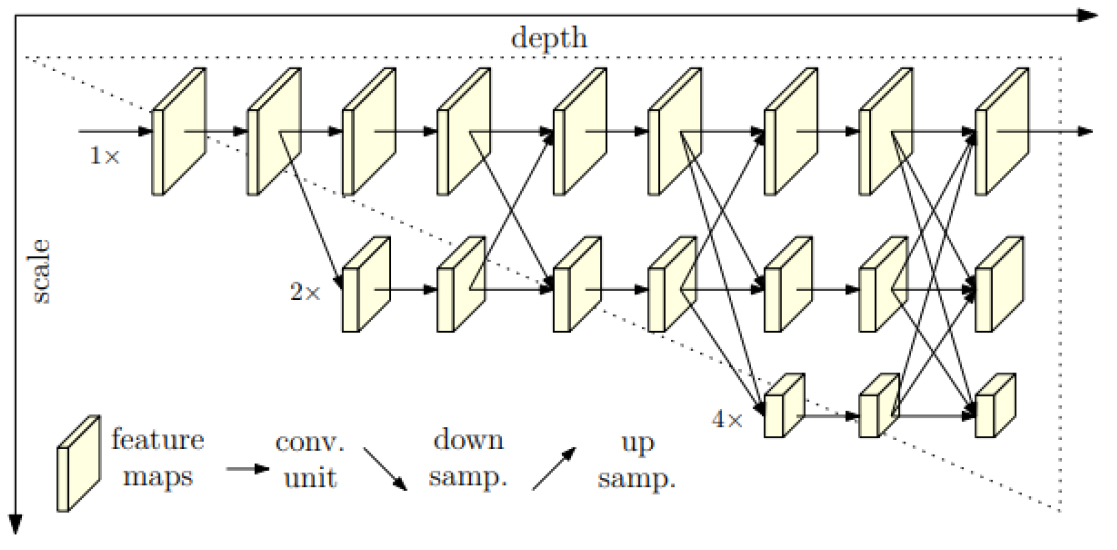
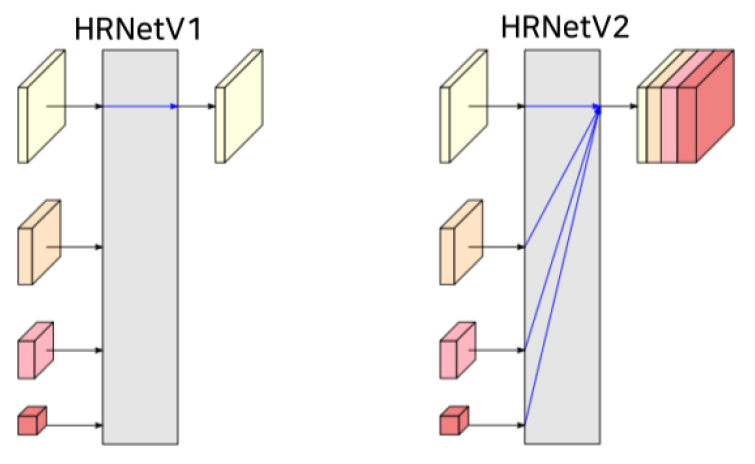
CNN은 일반적으로 다운샘플링 과정에서 공간해상도를 저하시키고 분광정보를 상세화시키면서 특징맵을 생성한다. 그러나 High Resolution Network (HRNet)은 고해상도와 저해상도 특징맵을 결합시키면서 서브네트워크를 쌓아가는 멀티스케일 융합(multi-scale fusion)을 반복하는 구조이다(그림 3)(Sun et al., 2019). U-Net은 저해상도 특징맵을 다시 고해상도로 복원시키지만, HRNet은 고해상도 특징맵을 유지하면서 다중 해상도 특징맵을 계속적으로 융합해 나가기 때문에, 보다 더 효과적인 학습 및 정확도 향상을 가져올 수 있다. 본 연구에서는 다중 해상도 특징맵을 모두 더해서 고해상도 의미론적 분할을 수행하는 HRNetV2를 사용하였다(그림 4) (Wang et al., 2019). 실험 장비는 i9-12900K, RTX 3090 Ti이며, 언어와 라이브러리는 Python 3.9, Tensorflow 2.9, Pytorch 1.8을 사용하였다.
3. 평가 방법
레이블 영상과 예측 영상은 이진분류로 되어있으며, 수체가 1, 비수체가 0의 값을 가진다. 수체라고 예측된 화소가 정답이면 True Positive (TP), 비수체라고 예측된 화소가 정답이면 True Negative (TN), 수체라고 예측된 화소가 오답이면 False Positive (FP), 비수체라고 예측된 화소가 오답이면 False Negative (FN)로 표현한다. 예측 영상과 레이블 영상을 비교하여 TP, TN, FP, FN로 이루어진 혼동행렬(confusion matrix)을 생성하고, 정확도(accuracy), 정밀도(precision), 재현율(recall), F1점수, 평균 교집합 대 합집합 비율(Mean Intersection over Union, mIOU)를 계산하였다. 정확도는 예측 영상의 모든 화소에 대해 레이블 영상과 동일하게 분류된 화소의 비율을 의미한다. 정밀도는 예측 영상에 수체라고 표현된 화소 중에서 정답 화소의 비율로 나타내고, 재현율은 레이블 영상에 수체라고 표현된 화소 중에 예측 영상에서 정답으로 분류된 비율이다. FP가 많으면 정밀도가 나빠지는데, 이는 과탐지(overestimation) 경향을 의미하고, FN가 많으면 재현율이 나빠지는데, 이는 미탐지(underestimation) 경향을 의미한다. F1점수는 정밀도와 재현율의 조화평균(harmonic mean)으로 계산한다. Intersection over Union (IOU)는 어떤 클래스에 대해서 레이블 영상과 예측 영상의 교집합 영역과 합집합 영역의 면적비로 구하며, 수체 클래스 IOU와 비수체 클래스 IOU를 평균한 것이 mIOU가 된다.
III. 결과 및 토의
Sentinel-1 SAR 영상을 이용한 홍수탐지 실험을 위하여, 724장의 영상은 8:1:1의 비율로 셔플링(shuffling)하여 훈련 580장, 검증 72장, 시험 72장으로 구분하였으며, 훈련, 검증 데이터셋으로 모델을 구축하고 시험 데이터셋으로 암맹평가를 수행하였다. U-Net과 HRNetV2 모델의 설정에 있어서, 반복학습 회수(epoch)는 100으로 하였고, 수체와 비수체 클래스 분할을 위한 손실함수(loss function)은 이진교차엔트로피(Binary Cross-Entropy, BCE)를 사용하였다. U-Net 모델은 Adaptive Moment Estimation (ADAM) 옵티마이저(optimizer)를 사용하였고 0.0001의 일정한 학습률(learning rate)로 훈련시켰다. HRNetV2 모델의 경우, Stochastic Gradient Descent (SGD) 옵티마이저에 대해 학습률 0.02, 가중치조락(weight decay) 0.0001로 설정하여 학습을 수행하였다(표 1). 이러한 하이퍼파라미터(hyperparameter) 설정은 여러 차례의 반복 실험을 통해 도출된 경험적 적정치를 부여한 것이다. U-Net과 HRNetV2 탐지 결과에 대해 예측 영상과 레이블 영상을 비교하여 그림 5의 혼동행렬을 생성하였고 정확도, 정밀도, 재현율, F1점수, mIOU를 계산하여 성능평가를 수행하였다. 표 2와 같이, 두 모델 모두 mIOU 0.9 이상의 높은 영상분할 성능을 보였으며, 이 실험에서는 U-Net이 HRNetV2보다 근소하게 높게 정확도를 나타냈다. 이는 하이퍼라파미터 최적화의 차이일 것으로 추측되며, 향후 데이터베이스의 추가 구축과 함께 U-Net과 HRNetV2 모델에 대하여 Bayesian Optimization (BO) 등을 활용한 하이퍼라파미터 재최적화 실험이 부가적으로 필요할 것이다. 그림 6, 7, 8, 9는 암맹평가에 사용된 72장의 영상 중에서 임의로 4세트를 선별한 것으로, RGB 합성은 R 밴드에 VV, G 밴드에 VH, B밴드에 VV와 VH 평균을 할당한 것이다. RGB 합성 영상이 레이블과 유사하게 보이는 것은 VV, VH 후방산란계수가 수체 추출을 위한 충분한 정보를 가지고 있기 때문이다. U-Net과 HRNetV2 모델의 탐지 결과는 대동소이하지만, 세세한 부분에서는 과탐지와 오탐지가 일부 나타났는데, 이는 전이학습(transfer learning)이나 미세조정(fine tuning) 등을 통해 해결 가능할 것이다.
표 1.
Hyperparameters for U-Net and HRNetV2
| U-Net | HRNetV2 | |
| Optimizer | Adam | SGD |
| Learning rate | 0.0001 | 0.02 |
| Epoch | 100 | 100 |
| Batch size | 20 | 20 |
| Beta 1 | 0.9 | 0.9 |
| Weight decay | - | 0.0001 |
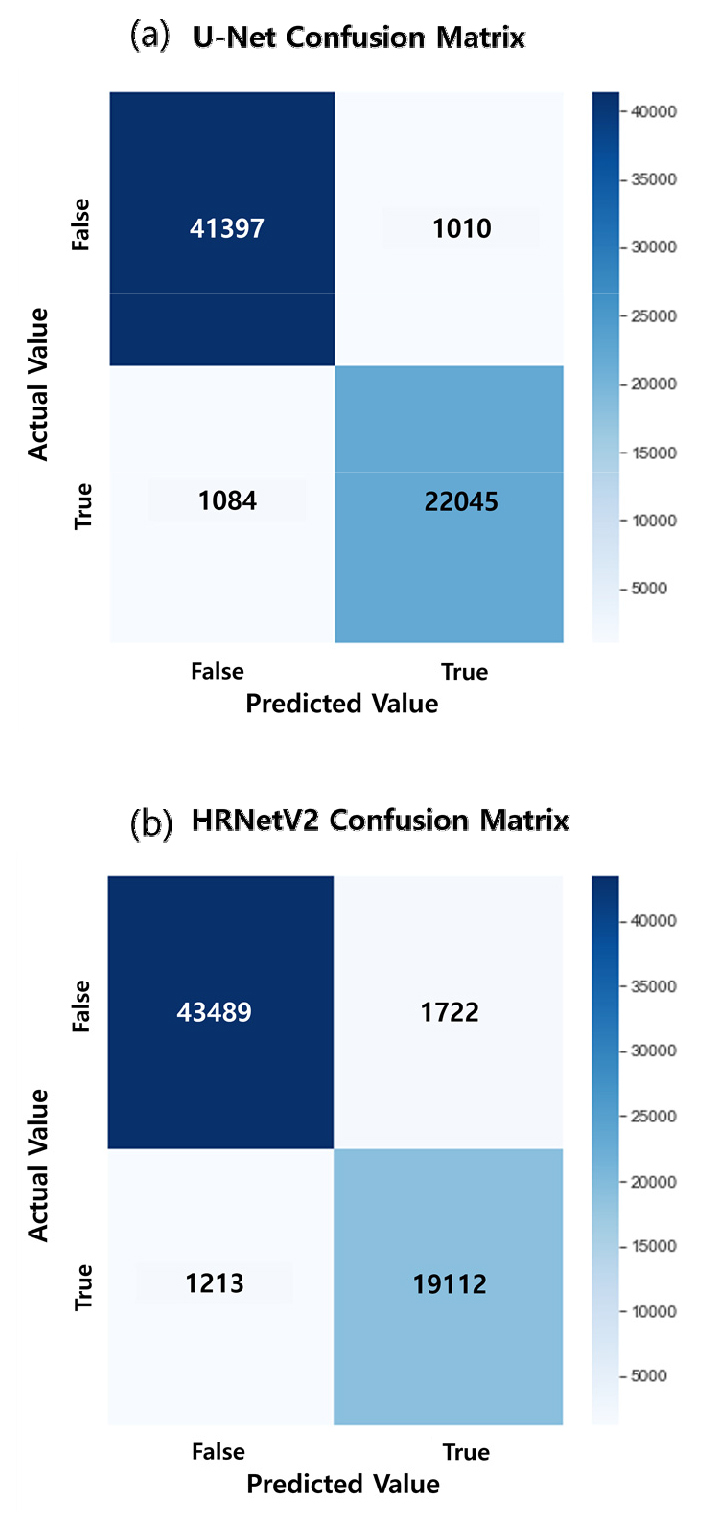
표 2.
Prediction results of U-Net and HRNetV2
| Accuracy | Precision | Recall | F1-Score | mIOU | |
| U-Net | 0.968 | 0.956 | 0.953 | 0.955 | 0.933 |
| HRNetV2 | 0.955 | 0.917 | 0.940 | 0.929 | 0.902 |

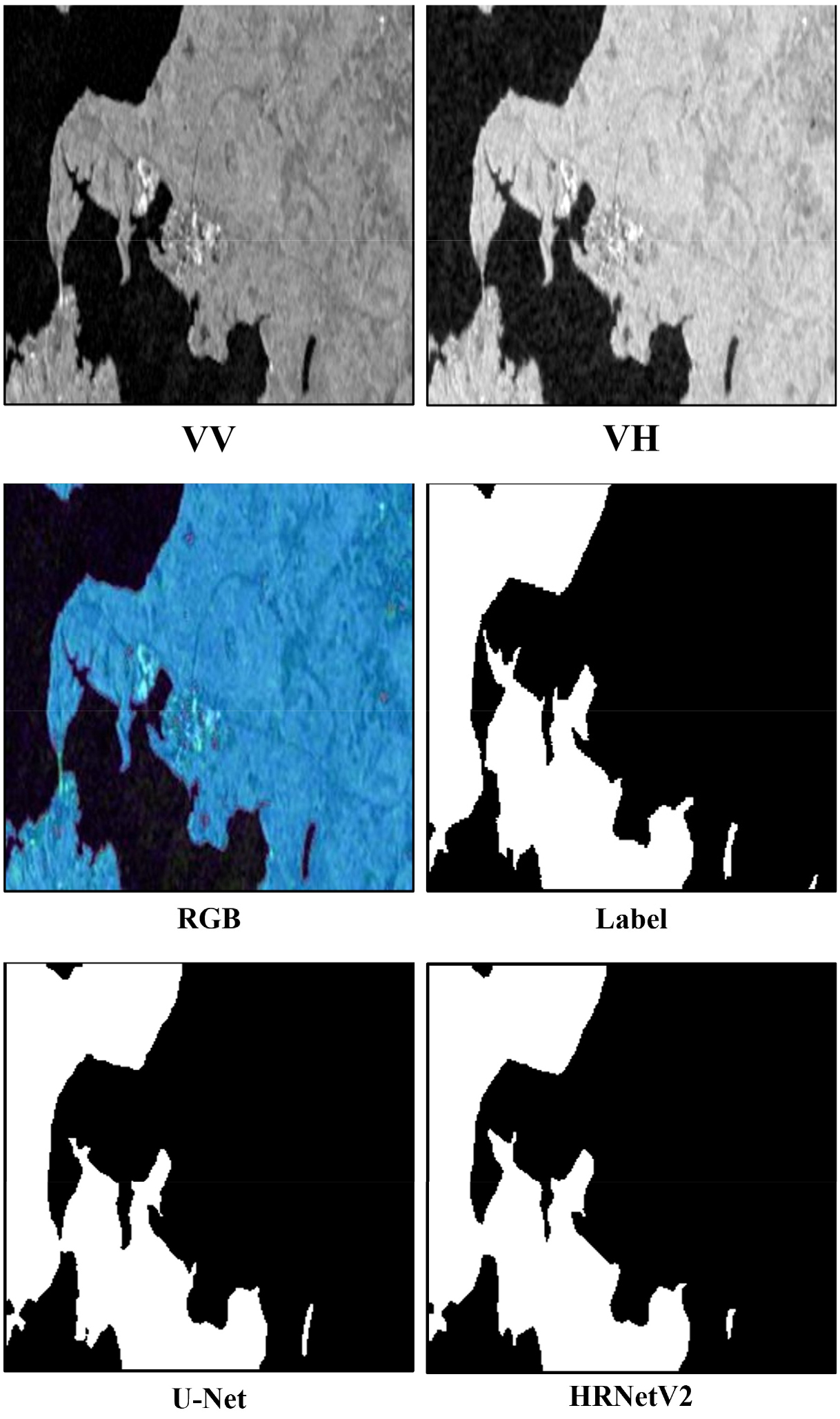
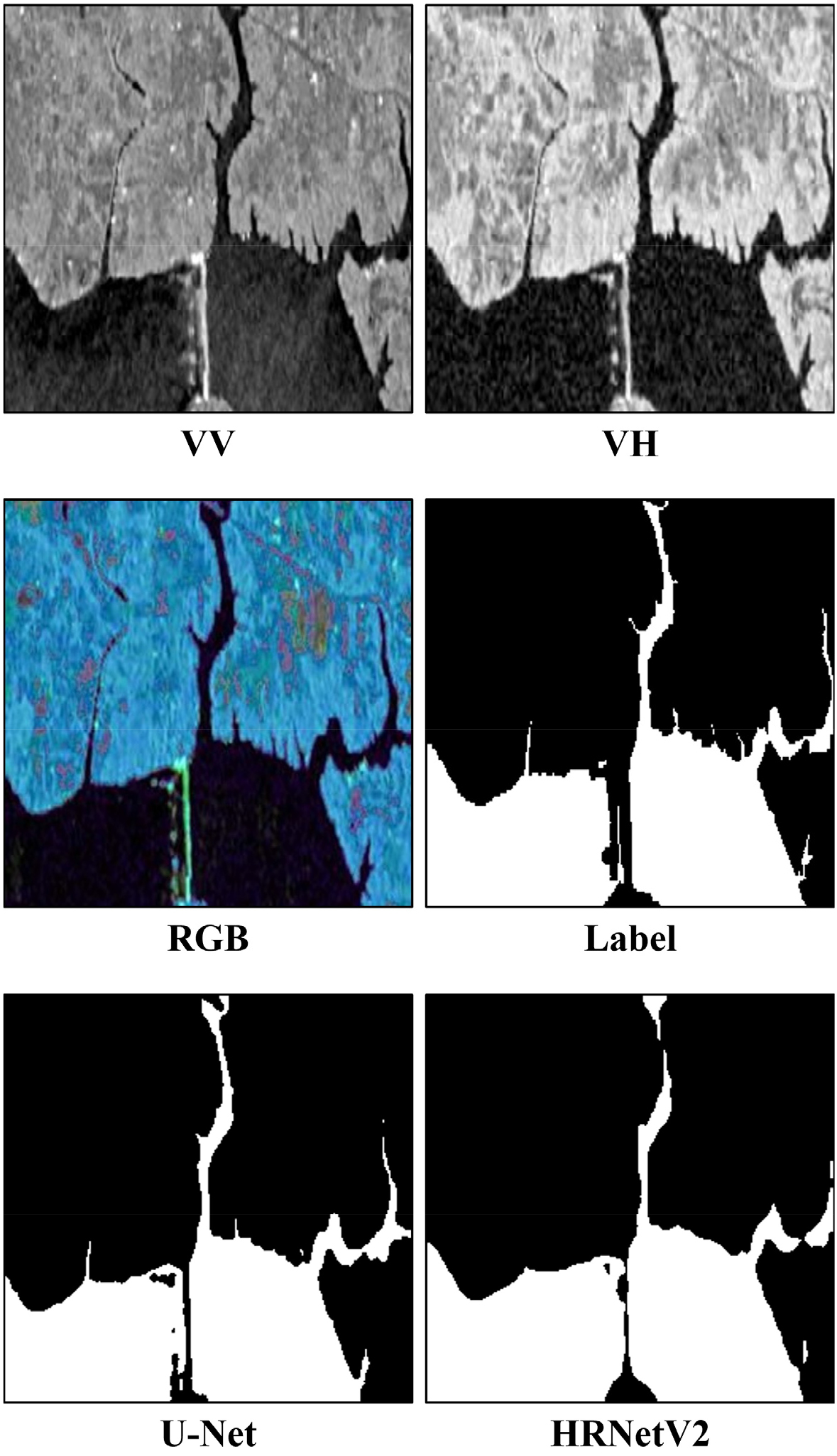
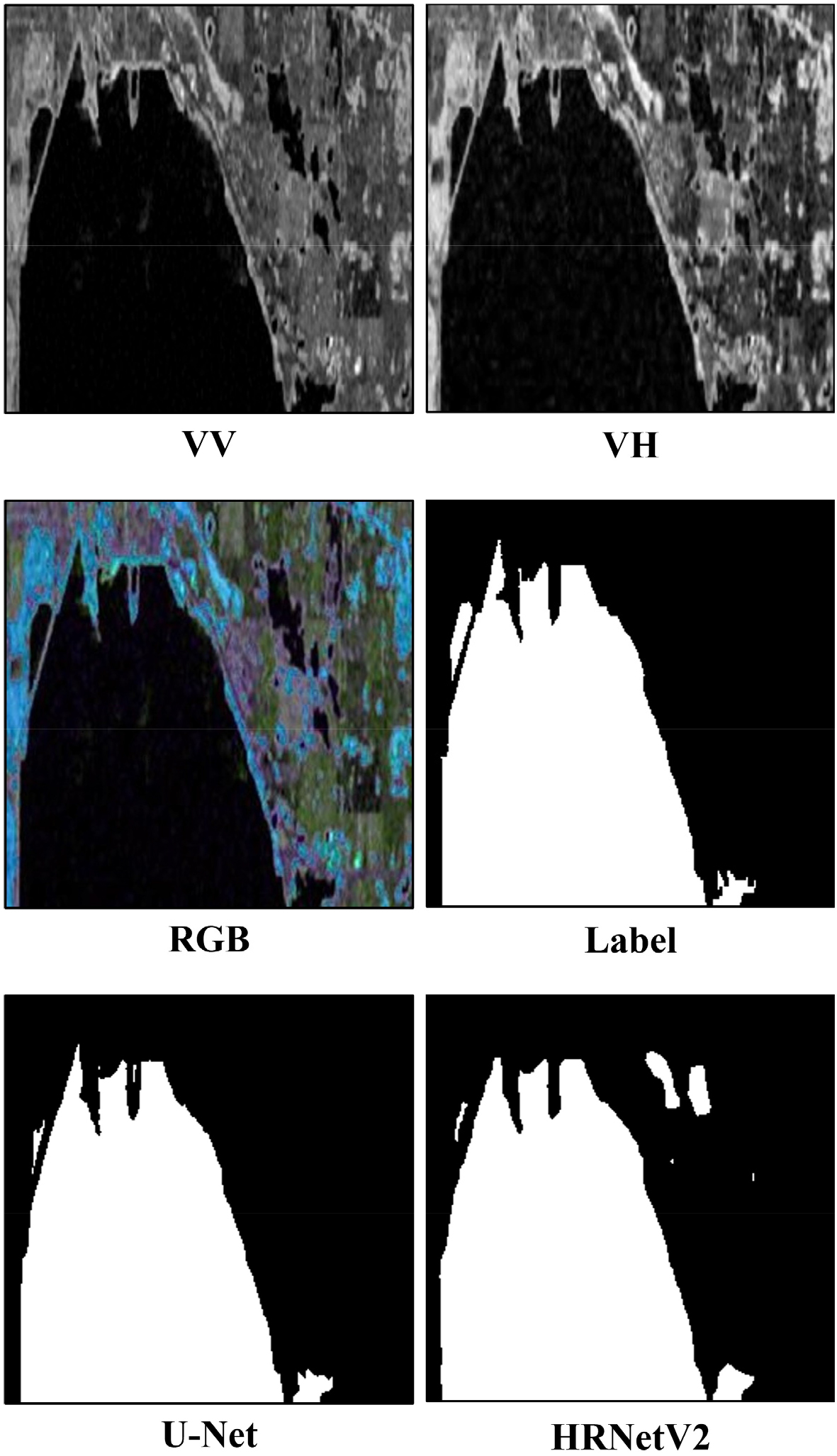
SAR 영상에 딥러닝 기법을 적용한 선행 연구들에서는 주로 U-Net 모델을 사용하는 사례가 많았으며, Sentinel-1 SAR 영상을 이용한 수체 탐지 선행 연구(Jeon et al., 2021)에서는 대규모 강의 범람 탐지를 위해 토지피복도(land cover map)를 보조자료로 사용하였고, F1점수 0.871, mIOU 0.771을 기록하였다. 또한 이도이 등(2022)은 U-Net을 이용한 Sentinel-1 영상의 수계 탐지를 수행하여, F1점수 0.897, mIOU 0.894의 성능을 보였다. 이러한 선행 연구들에 비해 본 연구의 결과가 정량적으로 다소 앞서기는 하지만 사용 데이터가 다르기 때문에 일반화 하기는 어려우며, 보다 객관적인 평가를 위해서는 추가적인 모델 사용 및 최적화, 그리고 대용량 자료에 대한 성능평가 실험이 수반되어야 할 것이다. SAR 영상 VV 및 VH 편파의 후방산란계수만을 입력자료로 사용할 경우, 수체 주변에 후방산란이 적은 지형지물의 존재로 인해 오탐지 및 미탐지가 발생하기도 하였다. 또한 수체의 면적이 좁거나 얕은 곳은 10m 해상도 영상으로는 탐지하기 힘들기 때문에, 영상자료증대(image data augmentation) 기법을 통해 학습영상 수를 증가시키거나, 초해상화(Super Resolution, SR) 기법을 적용하여 고해상도 영상으로 변환 후 학습시키는 방법도 시도해 볼 수 있을 것이다. SAR 영상에서 수체와 비슷한 후방산란계수를 가지는 그림자 효과를 억제하고 수체의 위치에 대한 추가적인 정보를 줄 수 있는 Digital Elevation Model (DEM)을 보조자료로 활용함으로써 탐지 정확도를 보다 더 개선할 수 있을 것으로 사료된다.
IV. 결론
최근의 SAR 기반 홍수탐지는 딥러닝 영상인식을 적용하고 있지만, 대용량의 학습자료를 사용하여 훈련, 검증 및 시험평가를 수행한 사례는 찾아보기 힘들다. 본 연구에서는 NASA Flood Extent Detection 대용량 학습자료를 사용하고 U-Net 모델을 최적화하여 Sentinel-1 영상으로부터 홍수탐지를 수행하였다. 예측 영상과 레이블 영상을 비교하여 혼동행렬을 작성하고 성능평가를 수행한 결과, 정밀도 0.956, 재현율 0.953, mIOU 0.933의 상당히 높은 정확도 통계량을 나타냈다. 다만, 규모가 작은 범람 영역에 대한 정확도 향상이 필요한데, 이는 향후 연구에서 DEM 등의 보조자료 사용과 최신(State-of-the-Art, SOTA) 모델의 활용 및 초해상화(Super Resolution)의 적용 등을 통해 개선될 수 있을 것이다. 본 연구에서는 홍수가 빈발하는 미국과 동남아시아 데이터셋을 사용하였지만, 현재 우리나라 정부에서 구축 중인 인공지능 학습용 홍수 영상 데이터베이스가 갖추어진다면, 본 연구에서 제안된 방법은 일부 수정을 통해 우리나라 홍수 감시에 적용될 수 있을 것으로 사료된다.
