

I. 서론
II. 연구 방법과 재료
1. 가상 종 분포 시뮬레이션
2. 편향된 출현 자료
3. 종 분포 모형
4. 모형 검증 및 해석
III. 연구 결과
1. 예측 성능 감소 강도
2. 예측 성능 감소 합의 지역
3. 해석 성능 평가
IV. 토의
V. 결론
I. 서론
생물 종 분포 모형(Species distribution model)은 생물지리학과 생태학에서 생물 종의 공간적 분포를 예측하고 그 분포 원리를 해석하는데 유용한 도구로 자리 잡았다(Elith and Leathwick, 2009). 생물 종 분포 모형은 생물이 접하는 환경 특성과 공간 분포를 결합하는 일련의 상관 모형을 주로 일컬으며 회귀 분석의 특수한 형태다. 이때 모형의 독립 변수와 종속 변수는 생물의 공간 분포를 반영하는 공간 좌표를 환경 변수와 연결 지어 구성된다. 공간 좌표는 생물 종의 환경 선호를 반영하는 출현 자료와 환경 비선호를 암시하는 비출현 자료, 그리고 생물 종에 주어진 환경 분포를 모사하는 배경 자료로 구성될 수 있다.
이 중에서도 출현 자료는 실제 연구 대상 생물 종이 나타난 위치를 기록한 공간 좌표이자, 종 분포 모형의 적합에 필수적인 자료이며 출현 자료가 어떻게 수집되었는지에 따라 종 분포 모형 결과는 상이하게 달라질 수 있다. 특히 출현 자료가 종이 접하는 환경 구배(Environmental gradient)에 따라 균일하게 수집되지 못한 경우는 편향된 출현 자료(Biased presences)라 불리며 모형의 신뢰성을 하락시키는 주요 원인이 된다(Phillips et al., 2009). 출현 자료의 편향은 크게 3가지로 구분될 수 있다. 서식처가 공간적으로 상이함에도 특정 서식처에서만 수집되거나 조사자가 접근하기 쉬운 곳에서만 주로 수집되는 등의 공간 편향, 생활사 주기에 따라 서식처가 상이함에도 특정 계절이나 시기에만 수집되는 시간적 편향, 하위분류 계통에 따라 서식처가 상이함에도 특정 분류군에서만 집중적으로 수집되는 분류학적 편향으로 구분될 수 있다. 이 중에서 최근 자주 다뤄지는 편향은 출현 자료의 공간 편향으로 “월리스형(型) 지식 공백(Wallacean shortfall)”이라고 불리는 생태학적 데이터의 공간적 불균형에 해당한다(Hortal et al., 2015).
이를 해결하기 위해 여러 방법이 제안되었으나 한계점 또한 존재한다. 대상 그룹 배경 선택(Target group background selection; TGBS), 공간 필터링(Thinning, Spatial filtering) 같은 방법은 불균등한 출현-배경-비출현 자료의 비중을 보정하는 접근이며, 이를 적용하더라도 데이터가 부재하는 지역에 대한 외삽 성능의 개선은 제한적일 수 있다(Phillips et al., 2009, Veloz, 2009). 공간적 다층(Spatially nested) 방법(Adde et al., 2023; Guisan et al., 2025)은 반응 함수를 통계적 방법을 통해 개선하려는 시도이며 그 개선의 맥락은 지역과 종, 시간에 따라 상이할 수 있다. 선행 연구에서 제안된 여러 편향 처리 방법을 적용하더라도 특정 환경 구배에 대한 정보는 여전히 놓칠 수 있으며 이는 흔히 생태적 지위 절단(Niche truncation)이라고 불리는 문제를 유발한다. 이는 즉, 생물 종의 생태학적 지위를 추정하기 위한 정보가 부분적으로만 수집되어 전체적인 지위 추정이 불가능해지는 것을 의미한다.
지위 절단이 발생할 경우, 실제 종의 지위를 온전히 포착하지 못하므로 신뢰성 있는 모형 결과는 수집된 데이터 구배 내의 내삽으로 제한받게 된다. 외삽의 경우, 모형 적합에 사용되지 않은 환경 구배에 예측이 적용되므로 모형의 예측 성능이 크게 떨어질 수 있다. 이러한 예측 성능 하락은 궁극적으로 데이터를 개선하여 지위 절단을 개선하기 전까지는 인식하는 것마저 어렵다. 이는 모형의 평가 또한 연구자가 보유한 편향된 출현 자료에 의존하기 때문이다. 출현 자료의 편향을 사전에 살피기 위해 교차 검증을 통한 모형 예측 성능의 민감도를 살필 것이 요구되지만(Roberts et al., 2017), 지위 절단 발생 여부를 진단하는 명확한 기준은 아직 알려지지 않았다. 교차검증을 시도하더라도 지위 절단의 판별은 여전히 모호하며, 잘못된 예측을 통해 부정확한 서식처 적합도 추정에 이를 수 있다. 더 큰 문제점은 출현 자료 편향이 최근 많이 연구되는 기후 변화와 이에 따른 생물 종의 서식 범위 이동(Range shift)과 맞물려 모형을 통한 추론에 더욱 치명적일 수 있다는 것이다.
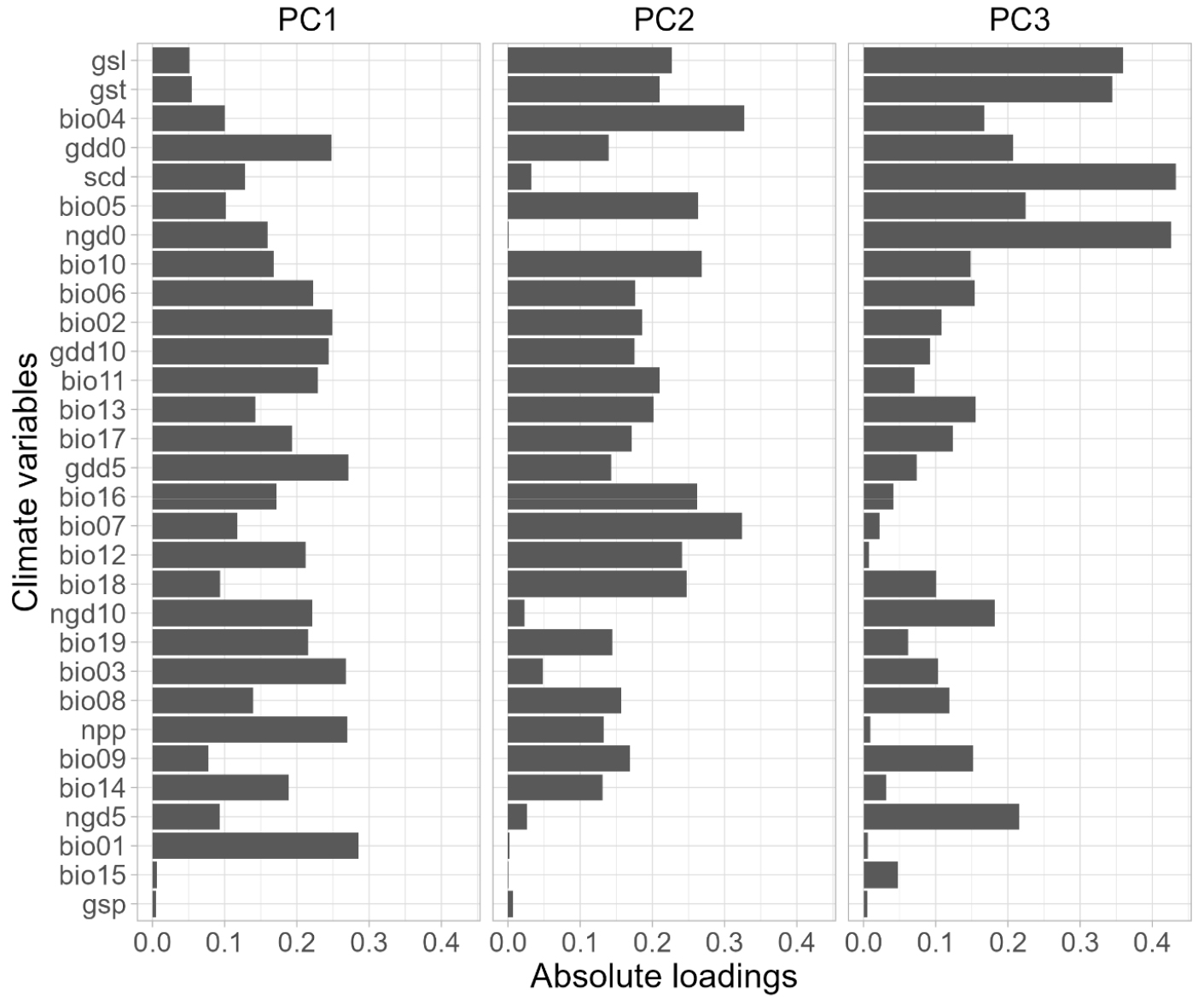
공간 편향과 기후 변화 문제는 한반도와 같이 위도 구배를 따라 기후가 변동하고, 모든 위도와 고도 및 지역에 걸쳐 데이터를 수집할 수 없는 지역에서 더욱 불확실성을 키운다(그림 1). 한반도 또한 전 지구적 변화에 따라 기후 변화가 나타날 것이라 예상되며(박미나・최영은, 2020; 이자원, 2010), 그 양상은 그림 1B-D와 같이 위도 구배를 따라 기후 특성이 변할 것이라 예측된다(Brun et al., 2022). 기후 변화 추정치는 Climatologies at High resolution for the Earth's Land Surface Areas BIOCLIM+(Brun et al., 2022)의 생물 기후 변수 중, 한반도의 기후 특성을 제시하는 30종 생물 기후를 활용했다. 기후 변화 추정치는 MRI-ESM 2.0 기반 SSP- 585 시나리오의 2071-2100년과 현 기후(1981-2010년) 사이의 차이로 산정하고 이를 주성분 분석(Principal component analysis)을 통해 시각화하였다. 한반도 일대 30개 생물 기후의 차이를 주성분 분석한 결과, 상위 주성분(Principal component; PC) 3개에서 위도 및 해양과의 거리 및 지형 특성에 따른 구배가 나타났다. PC1은 위도에 따른 기온 변화를 반영하며 주로 기온과 관련된 생물 기후 변수들에서 높은 적재값이 나타났다. 반면, PC2는 기후의 계절적 변동성을, PC3는 적설과 생장 기간을 반영하는 변수를 반영했다(그림 2). 이는 미래의 기후 변화 양상이 고도, 해양과의 인접성, 위도 등의 지리적 특성과 강한 상관 관계를 지니며 출현 자료의 수집 또한 지리적으로 균등하게 수집되어야 함을 의미한다.
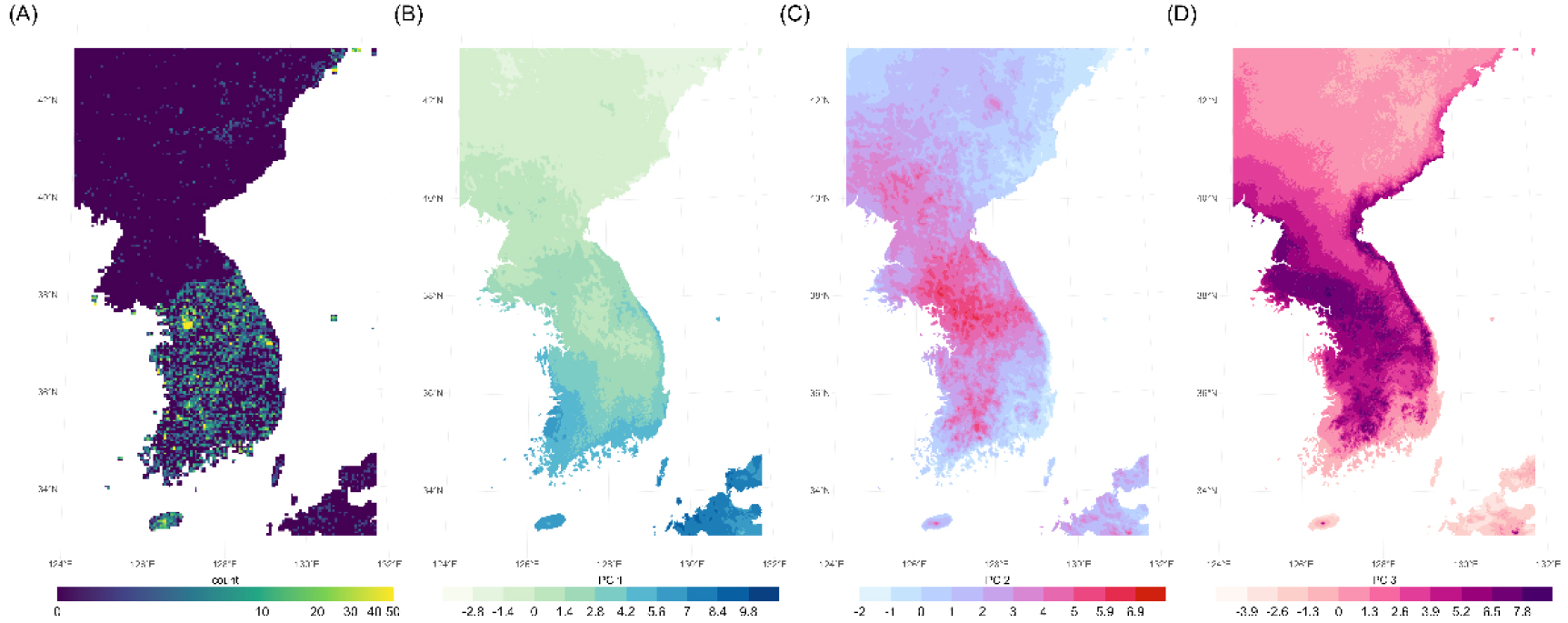
하지만, 북한을 비롯한 한반도 북부 데이터가 제한적이므로 필연적으로 대한민국 내 분포하는 생물 종에 대한 종 분포 모형은 생태적 지위 절단의 위험성을 내포하고 있다(그림 1A). 그림 1A는 대한민국 주요 산림 구성 수종 34개 종을 사례로 5km 픽셀 내 포함된 세계생물다양성정보기구(Global Biodiversity Information Facility; GBIF)좌표의 개수를 표시한 것이다.1) 대한민국 산림 주요 분포 수종은 북한과 유사하거나 위도 구배의 분포를 지닐 것으로 기대되지만 남한 이북 지역에서 공개된 데이터는 극히 제한적이다(그림 1A). 이는 중국에서도 마찬가지이며 한국과 유사한 데이터 밀도는 러시아의 블라디보스톡 인근과 일본 일부 지역에 한정된다. 이러한 공간 편향은 GBIF를 사용한 종 분포 모형의 추정이 남한과 일본 및 러시아 일부 지역에서만 신뢰성 있게 적용될 수 있음을 반영한다.
기후 변화로 인한 생물 종의 서식 범위 이동을 추적하는 연구는 많이 진행되었지만(공우석, 2005; 윤종학 등, 2011) 국내 분포 종의 출현 편향 특성을 다룬 연구는 부재했으며 이것이 모형의 결과, 즉 예측과 해석에 미칠 수 있는 영향은 더욱 알려져 있지 않았다. 특히 국내 분포하는 생물 종의 상당수가 기후 변화로 인해 북상할 것으로 예상되지만, 편향된 데이터에서 얼마나 신뢰성 있는 서식 범위 이동을 추정할 수 있는지는 학계의 지식 격차로 남아있다.
기후 변화는 연구자들이 지역 및 시기마다 다양한 시나리오를 통해 그 변화의 강도를 보다 정밀하게 추정 중에 있으며 데이터 편향의 주요 발생 지역 또한 공개 데이터가 늘어남에 따라 점점 더 명확해지고 있다(그림 1). 본 연구는 출현 자료의 편향이 기후변화의 맥락에서 종 분포 모형의 결과에 어떻게 영향을 미칠 수 있는지 실험하고 구체적인 모형의 불확실성을 제시하고자 한다. 이는 출현자료가 편향되었더라도 신뢰할 수 있는 지역과 그 맥락을 밝힘으로써 국내에서의 종 분포 모형의 적용 가능성과 한계를 보다 상세히 밝히기 위함이다. 출현 자료의 편향을 다룬 선행 연구의 한계점은 특정 분류군에 한정된 조사로 그 연구 결과를 타 분류군에도 확장하여 일반화하기가 어려울 수 있다는 점이다(Beck et al., 2014; Bystriakova et al., 2012). 이를 보완하여 재현 가능하면서도 특정 분류군에 한정되지 않은, 보다 일반화된 결론을 도출하기 위해 본 연구에서는 가상 종 분포 시뮬레이션을 활용했다. 종 분포 모형을 통한 추론은 구체적으로 예측(e.g. 기후 변화로 인한 종의 분포 범위 축소를 더 정확하게 예측)과 해석(e.g. 종의 분포 범위 변화에 영향을 미치는 환경 인자의 특징)으로 구분될 수 있으며 본 연구에서는 출현 자료의 공간 편향이 이들에 미치는 영향을 정량적으로 제시하는 것을 목표로 한다.
II. 연구 방법과 재료
1. 가상 종 분포 시뮬레이션
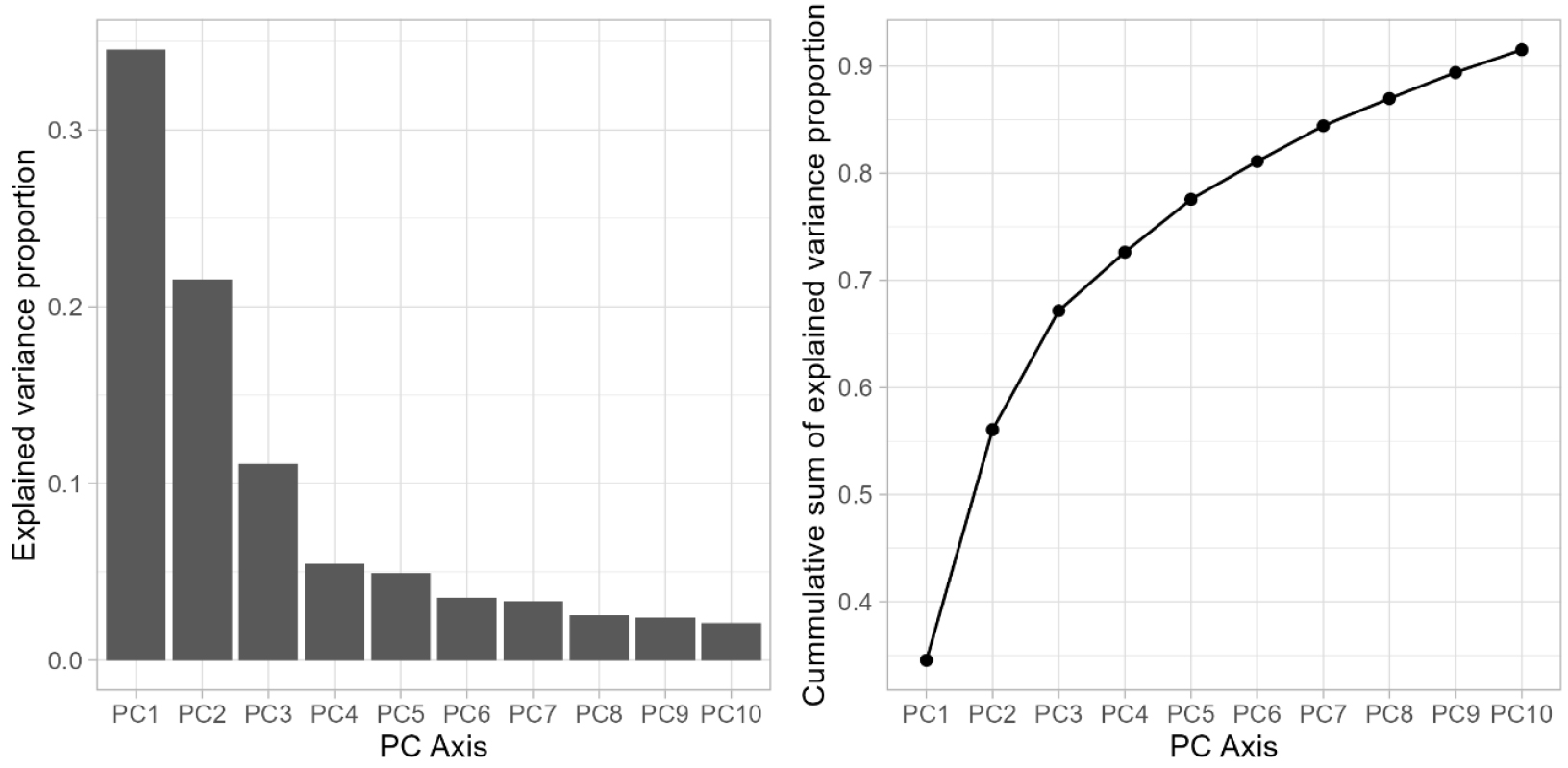
가상 종 분포 시뮬레이션은 생물 종이 어떻게 환경에 반응하는지를 정의하는 환경 반응 함수(Environmental response function)를 연구자가 임의로 또는 조작적으로 구성하고 기후, 지형, 경관 등 환경 변수에 투영하여 가상의 서식처 적합도 및 출현 확률 등을 시뮬레이션 하는 방법이다. 본 연구에서는 실제 한반도와 그 인근 지역의 기후 데이터에 의해 분포가 결정되는 가상의 생물 종 100종을 무작위 환경 반응 함수를 가지도록 시뮬레이션 하였다. 환경 반응 함수는 gaussian, linear, logistic, quadratic 중 무작위로 선택되며 0부터 1 사이의 서식처 적합도로 반응하도록 가상 종을 설정했다. 가상 종에게 주어진 기후는 5가지 생물 기후 변수(Bio3, Bio7, Bio12, gsl, ngd5)로 선정했다(표 1). 이는 해당 변수들이 한반도 내 기후 변화를 낮은 다중공선성을 유지하면서도 높은 분산 설명력으로 반영할 수 있기 때문이다. 이를 확인하기 위해 사회 경제 경로 시나리오(Shared Socio-Economic Pathways) 상 고배출 시나리오(SSP5-8.5), 일본 기상연구소(Meteorological Research Institute; MRI) 지구 시스템 모델 ESM2.0 기반 30종의 생물 기후 변수(Brun et al., 2022)를 주성분 분석에 적용했다. 현재(1981-2010년)와 미래(2071-2100년) 시기 사이 차이를 기후 변화로 간주했으며, 각 주성분(Principal component; PC) 마다 배타적으로 주성분 기여도가 높았던 5가지 생물 기후 변수를 가상 종 분포 시뮬레이션에 사용했다. PC5까지 약 77%의 누적 분산이 설명되었으며 PC1과 2에서 약 56%의 분산 기여가 확인되어(그림 3), 5개의 변수로도 충분히 한반도 인근의 기후 변화를 설명할 수 있음을 보였다. 또한 각 PC에서 배타적인 변수를 시뮬레이션과 종 분포 모형에 이용함으로써 다중공선성을 피하고 보다 높은 해석 정확도를 갖추도록 하였다.
표 1.
가상 종 분포 시뮬레이션에 이용된 기후 변수
| 생물 기후 축약명 | 생물 기후 국문명 |
| Bio3 | 등온성 |
| Bio7 | 연교차 |
| Bio12 | 연 강수량 |
| gsl | 성장 계절의 기간 |
| ngd5 | 일평균기온 5도 이상인 날의 수 |
최종적인 서식처 적합도는 각 환경 반응 함수에서 얻어진 환경 적합도의 합을 통해 산출했다. 이후, 각각의 최종 서식처 적합도에서 무작위로 500개의 출현자료를 추출하고 이를 종 분포 모형 적합에 이용하였다. 출현 자료의 추출은 시뮬레이션된 서식처 적합도에서 선형적 확률 변환에 따라 추출되도록 설정하였다. 즉, 서식처 적합도가 높은 격자에서 출현 자료가 추출될 확률이 높도록 설정했으며 시뮬레이션된 서식처 적합도는 0부터 1 사이 값을 지니도록 정규화한 이후 모형의 예측 잔차 산출에 활용하였다.
2. 편향된 출현 자료
서식처 적합도 전체 지역에 걸쳐 균등하게 수집된 출현 자료와 함께, 공간 편향을 발생시킨 출현 자료를 준비하였다. 편향 지역은 대한민국과 가깝고 많은 종의 분포가 겹치면서도 기후 변화에 따라 종의 서식 범위 이동이 예상되는 북한 지역으로 설정하였다. 북한을 제외한 지역에서 출현 자료를 500개씩 수집하여 동일하게 종 분포 모형의 적합에 이용해 실험군을, 북한을 포함한 동북아시아 지역에서 편향 없이 동일한 수의 출현자료를 수집하여 대조군으로 사용했다.
3. 종 분포 모형
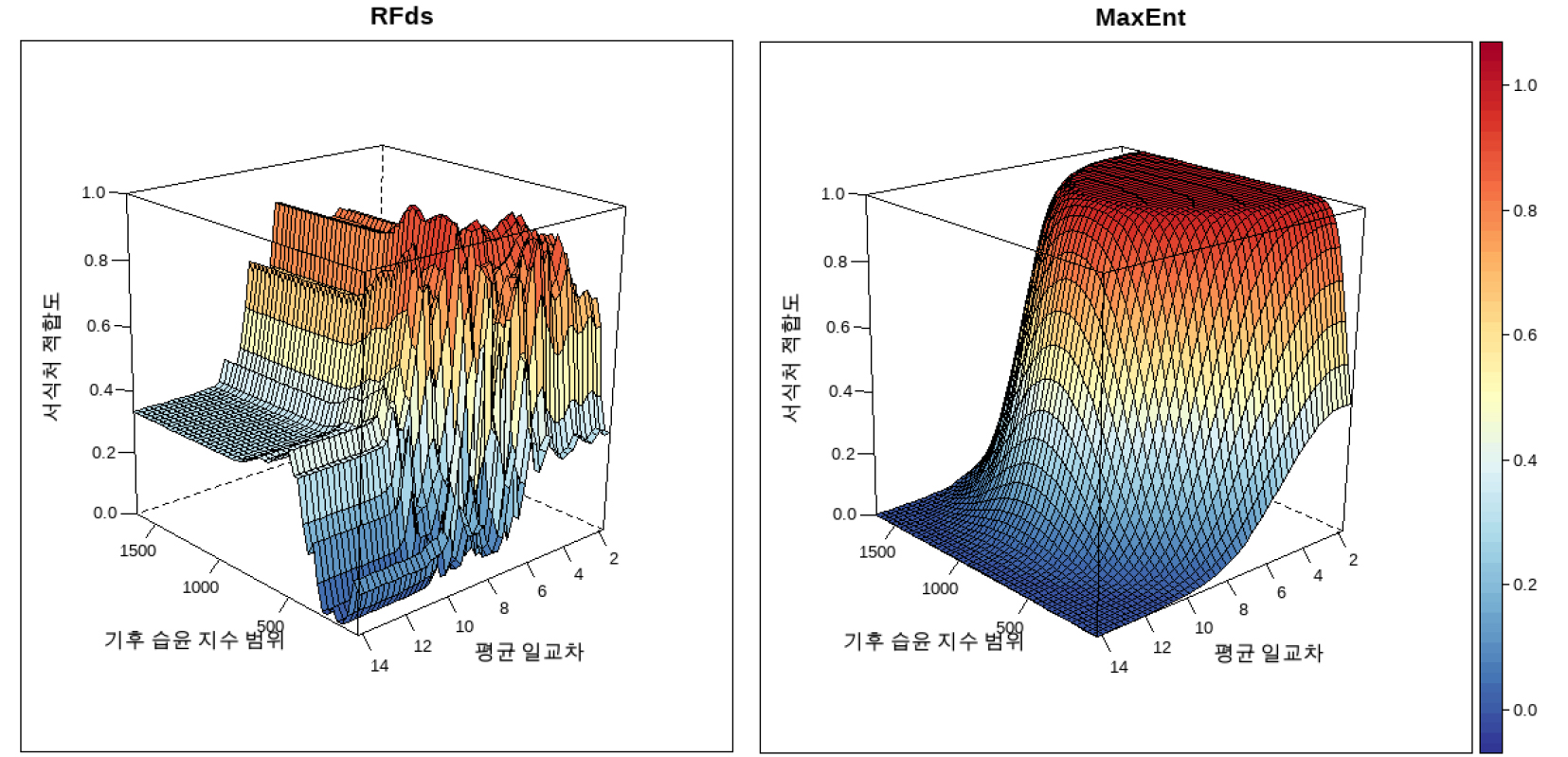
종 분포 모형은 출현 자료와 배경 자료를 활용하는 최대 엔트로피(Maximum Entropy; MaxEnt, Phillips et al., 2004) 알고리즘과 다운 샘플링 랜덤 포레스트(Random Forest Down Sampled; RFds, Valavi, 2021) 알고리즘을 사용하여 적합하였다. 현실적인 조사 환경에서는 신뢰할 수 있는 비출현 자료를 확보하기 어렵기 때문에 출현-배경자료 기반 알고리즘이 자주 사용되며, 본 연구 또한 출현-배경자료 기반 알고리즘을 중심으로 분석되었다. RFds는 복잡한 반응 함수를 쉽게 포착할 수 있도록 최대 1000개의 트리를, 반대로 MaxEnt 모형은 어느 정도의 유연성을 지니지만 과적합을 피하기 위해 모형의 하이퍼파라미터인 Feature class를 Linear, Quadratic, Product로 제한하여 각 알고리즘 마다 무작위 반응 함수의 복잡도에 유연하게 대처할 수 있도록 설정하였다. RFds 모형은 MaxEnt 모형에 비해 하이퍼파라미터 설정을 통해 보다 비선형적인 환경 반응 함수를 포착할 수 있으며, 더 유연한 알고리즘일 뿐만 아니라 데이터의 분포 특성에 민감한 경향을 보인다(그림 4). 이는 보다 복잡한 기후 선호도를 지닌 종을 포착할 수 있다는 장점인 동시에 불완전한 정보를 지닌 각각의 데이터 포인트에 지나치게 의존할 수 있다는 단점으로 작용할 수 있다. 본 연구에서는 각 알고리즘 모두 10,000개의 무작위 배경자료를 사용하였으며 배경 자료의 편향은 본 연구의 대상이 아니므로 고려하지 않았다.
4. 모형 검증 및 해석
모형의 오차는 과대 추정과 과소 추정으로 구분될 수 있으나 본 연구에서는 이를 구분하지 않고 편향 모형과 비편향 모형 간의 절대 오차 차이 를 계산, 편향으로 인해 모형의 절대 오차가 얼마나 차이 나는지 확인하였다. 본 연구에서는 종 i = 1, … , L , 모형 m ∈ {MX , RFds}, 조건 c ∈ { 0(bias), 1(unbias)} 로 표시하여 출현 자료 편향이 예측에 미치는 영향을 정량화하였다. 시뮬레이션 결과를 통해 실제 참 값 과 모형의 예측 값 사이 차이인 모형 별 오차를 계산할 수 있으며 절대 값 을 다음과 같이 취했다.
이후 편향 모형과 비편향 모형 사이의 절대 오차 차이 를 계산해 편향으로 인한 예측력 저하를 수치화했다.
이러한 오차 차이는 지역에 따라 상이할 수 있으므로 절대 오차 차이를 가상 종 전체에 걸쳐 평균을 취한 뒤 격자에 대해 지도화하였다.
이렇게 생성된 절대 오차 차이의 공간적 분포는 북한 지역 출현 자료 편향이 모형 잔차를 심화시키는 곳과 그렇지 않은 곳을 구분하는데 유용하게 사용될 수 있다. 또한 시뮬레이션된 가상 종 중 모형 예측 성능 하락이 공통적으로 나타나는 곳과 그렇지 않은 곳을 악화된 종의 비율로 해석하여 다음과 같은 식을 통해 제시하였다.
모형의 해석은 SHAP(SHapley Additive exPlanations)을 사용하여 편향된 출현 자료를 사용함에도 실제 시뮬레이션된 반응 함수를 모사할 수 있는지 확인하였다( Lundberg and Lee, 2017).
III. 연구 결과
1. 예측 성능 감소 강도
모형의 오차는 예측 지역에 따라 상이하게 나타났으며 특히 북한 및 고산, 아고산 지역에서 강하게 나타났다(그림 5). 지도에 포함된 각 격자의 색은 편향이 있는 출현 자료로 학습한 모형이 비편향 모형에 비해 얼마나 더 많은 예측 오차를 보였는지를 나타낸다. 보라색에 가까울수록 두 모형의 예측은 거의 같거나 차이가 없고, 노란색으로 갈수록 편향 모형에서 예측 성능이 많이 떨어진다고 해석된다. 비편향 모형 대비 편향 모형에서 전역적인 모형 예측 성능 하락이 나타났으며 MaxEnt 모형은 평균적인 예측 성능 감소가 최대 약 0.04(백분율 표기 시 4%), RFds 모형은 약 0.2(백분율 표기 시 20%) 발생했다. 오차의 방향은 가상 종 마다 상이했으며, 편향 여부에 따라 과대 추정이던 모형 오차가 과소 추정으로 나타나는 등의 역전 현상은 소수의 격자에서만 나타났다.
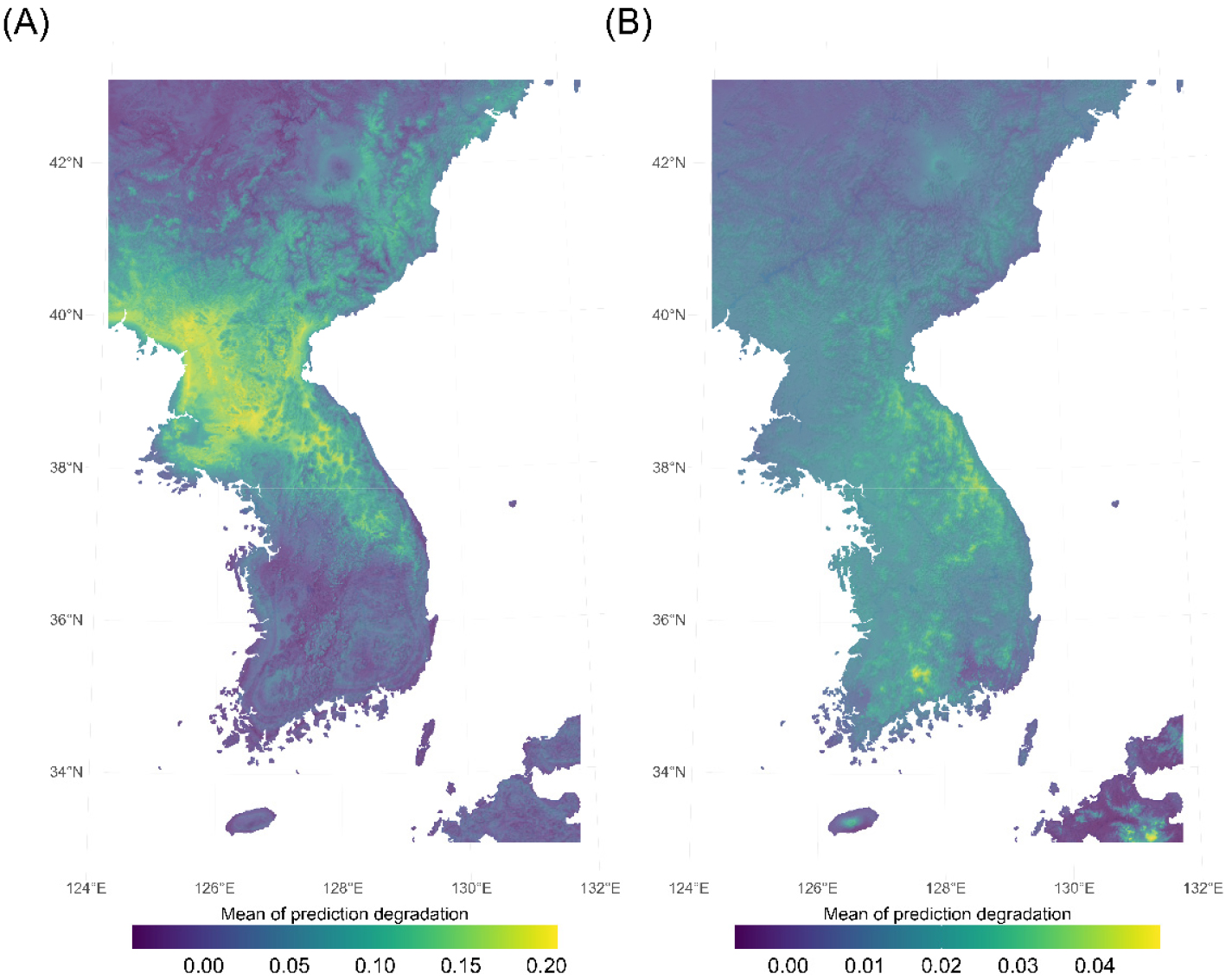
모형 오차는 RFds 모형에서는 편향 처리된 북한을 중심으로 높게 나타났으며 MaxEnt 모형에서는 일본 산간지역과 대한민국의 아고산 지역을 중심으로 나타났다. RFds 모형은 서울 이북에 해당하는 북위 38-40도 사이, 특히 북한 서해안 평야에서 휴전선 일대, 그리고 남쪽으로 이어지는 백두대간 남부 산지 주변에서 높은 오차를 보였다. 해당 영역의 평균 오차는 대략 0.15에서 0.2에 이르며 편향 모형의 예측이 비편향 모형보다 현저하게 나빠진 구역이다. 예측 오차는 북한뿐만 아니라, 남한에서도 높게 나타났다. 남한의 동해안 산지에서도 0.1 이상의 중간 수준 오차가 이어지며, 지형과 기후가 급격히 변하는 산악 지역을 따라 띠 모양으로 성능 저하가 나타난다. 반대로 남해안과 서해안 남부, 제주도 주변 및 한반도 최북단 고산지대는 낮은 오차를 보여 이 지역에서는 편향이 있는 자료를 사용하더라도 비편향 모형과 예측이 거의 유사하게 유지된다. 이를 통해 RFds 모형은 편향에 매우 민감했으며 남부 해안과 일부 북부 고산지대에서는 상대적으로 견고한 예측 패턴을 보였다.
MaxEnt 모형은 RFds 모형과 달리 한반도 대부분이 0.02 미만의 오차를 보여 성능 저하가 상당히 적음을 확인할 수 있었다. 이는 편향 자료를 사용하더라도 MaxEnt 모형에서 성능 저하가 전반적으로 적게 나타났음을 의미한다. 상대적으로 오차가 더 큰 영역(절대 평균 오차 약 0.03-0.04)은 남한 중남부의 내륙 산지, 특히 지리산과 소백산, 백두대간 일부에서 부분적으로 나타난다. 서해안과 남해안 및 한라산 일대에서도 국지적으로 오차가 발생하지만 RFds 모형에서 나타나는 넓은 영역의 오차 영역은 형성되지 않았다. 이를 통해 MaxEnt 모형에서는 편향이 있는 출현 자료를 사용하더라도 비편향 모형과의 차이가 적었음을 보여준다. 이를 통해 비록 북한에 한정된 국지적 편향이라도 그 영향은 편향 지역, 즉 북한에 한정되지 않고 이와 유사한 기후대 전역에 걸쳐 나타날 수 있음을 확인했다.
2. 예측 성능 감소 합의 지역
예측 성능 하락의 일반성을 확인하기 위해 100개의 가상 종에게서 예측 성능 하락이 나타나는 비율을 격자 단위로 측정하였다. 각 격자의 색은 해당 위치에서 편향 모형의 예측 성능이 비편향 모형보다 감소한 종이 전체 가상 종 100종 중에서 차지하는 비율을 의미한다(그림 6). 보라색에서 노란색으로 갈수록, 더 많은 종이 해당 위치에서 편향의 영향을 받아 예측 성능이 하락했다는 뜻이다. 분석 결과, 북한과 대한민국 모두 공통적으로 높은 비율의 종들에게서 예측 성능 감소가 나타났다. RFds 모형에서는 지역에 따라 최대 85%, MaxEnt 모형에서는 최대 70%의 가상 종들에게서 공통적인 예측 성능 감소가 확인되었고 가장 적은 지역이더라도 약 30%의 종들이 예측 성능 하락을 보였다. 이는 국지적 출현 자료 편향에 의한 예측 성능 감소는 그 강도는 상이할지라도, 특정 분류군에 제한되지 않고 공통적으로 나타날 수 있는 현상임을 암시한다. 알고리즘에 따른 차이는 그림 6을 통해 확인할 수 있는데, 같은 편향 구조가 주어지더라도 RFds 모형은 MaxEnt 모형에 비해 종 전체에 걸친 예측 성능 저하가 더 강하게, 그리고 더 공간적으로 집중되었다.
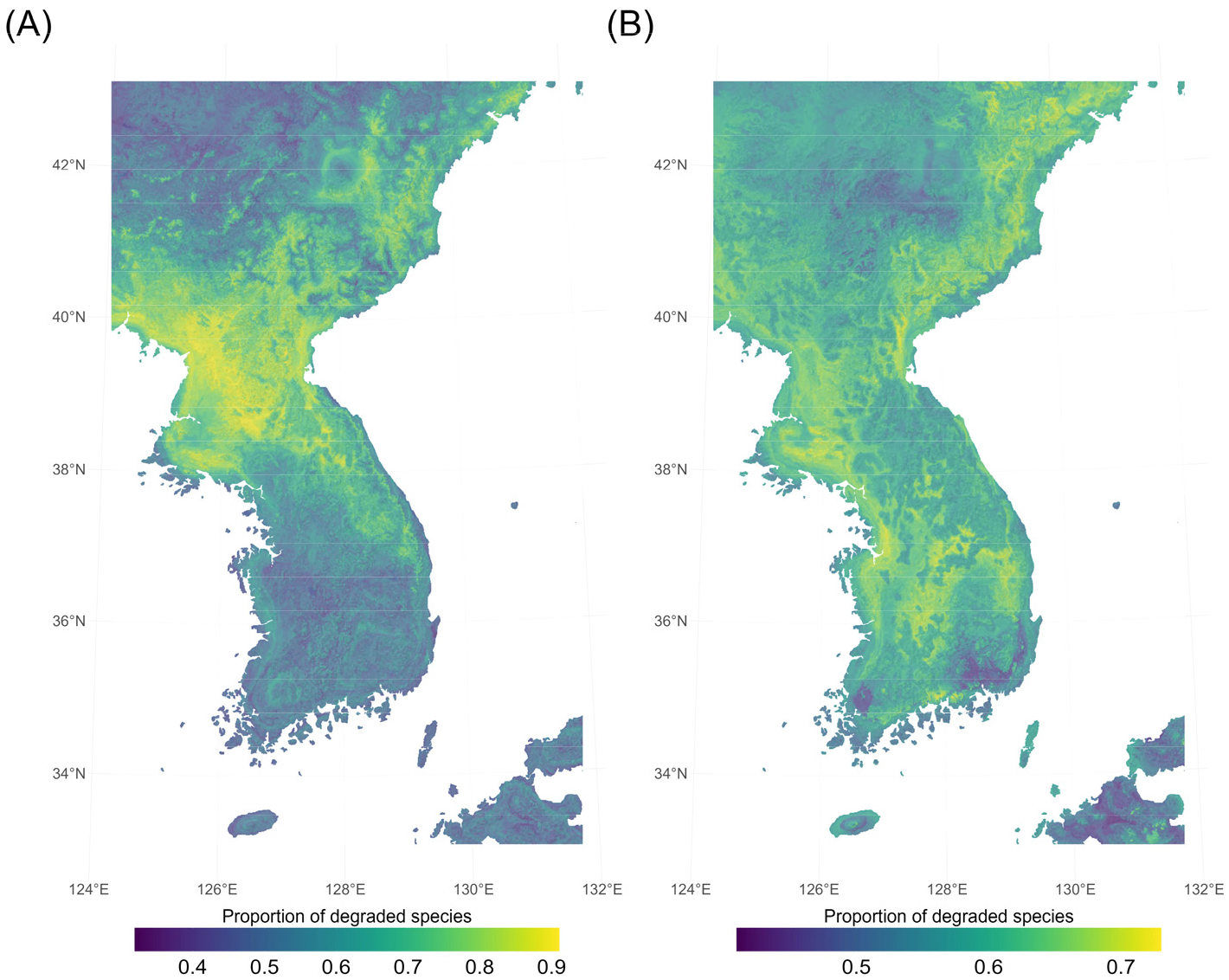
RFds 모형은 예측 성능 하락 강도가 높고 지역 편향이 반영되었던 북한 저지대에서 많은 종들의 예측 성능이 감소하였다. 특히 북한 서해안 평야와 휴전선 일대, 그 남쪽으로 이어지는 내륙 산지 주변에서 일관된 예측력 저하가 확인되었다(그림 6A). 예측 성능 저하의 일반성은 남한에서도 확장되어 태백, 소백산맥을 따라 60-80%의 가상 종들의 예측 성능 감소가 확인되었다. 이와 반대로 남한의 남해안과 서해안, 제주도 및 한반도 최북단의 일부 고산지역은 성능 저하가 40-50% 수준에 머물러 편향 모형이라 하더라도 약 절반 정도의 종에서는 비편향 모형과 유사한 수준의 예측력이 확인되었다.
MaxEnt 모형은 RFds 모형보다 보다 광범위한 지역에서 많은 종들의 예측 성능이 감소가 나타났다. 이는 예측 성능 감소가 적은 모형이더라도, 그 공간적 영향은 넓게 나타날 수 있음을 의미한다(그림 5B, 그림 6B). 성능 저하의 비율은 RFds 모형에서 40-90%로 나타났지만 MaxEnt 모형은 50%에서 70% 사이로 나타났다. MaxEnt 모형은 극단적으로 예측 성능 저하가 많이 발생하는 지역은 RFds 모형에 비해 적은 편이다. 특히, MaxEnt 모형에서는 기후 변화로 인한 서식 범위 이동의 주요 통로가 될 수 있는 서해안 인근 일대, 북한의 원산과 함흥을 포함하는 동해안 일대에서 70%에 달하는 종들의 예측 성능 하락이 나타났다.
3. 해석 성능 평가
출현 자료의 공간 편향에도 불구하고 모형의 해석이 정확하게 구현될 수 있는지는 선행 연구에서 흔히 다뤄지지 않은 주제다. 이를 보완하기 위해, 본 연구에서는 모형의 해석 성능을 SHAP을 사용해 평가하였다. 그림 7은 각 기후 구배에 따라, 모형이 가상 종의 서식처 적합도를 어떻게 해석하는 지를 가상 종의 반응 함수(파랑), 비편향 모형(초록), 편향 모형(빨강)으로 구분하여 비교한 것이다. X축은 모형의 기후 변수의 실제 값을 정규화 없이 표기하였으며 Y축은 모형 국소 해석 결과인 0부터 1사이 Shapley 값으로 정규화하여 표현하였다. SHAP의 국소 해석은 모형에 적용된 배경 자료 전체에 걸쳐 적용하였으며 일반 가산 모형(Generalized Additive Model)을 사용해 추세를 시각화했다. 모형의 해석 성능이 높을 수록 실제 주어진 반응 함수(파랑)와 각각의 국소 해석이 유사하게 나타날 것이며 추세 또한 유사하게 모사할 것으로 기대할 수 있다.
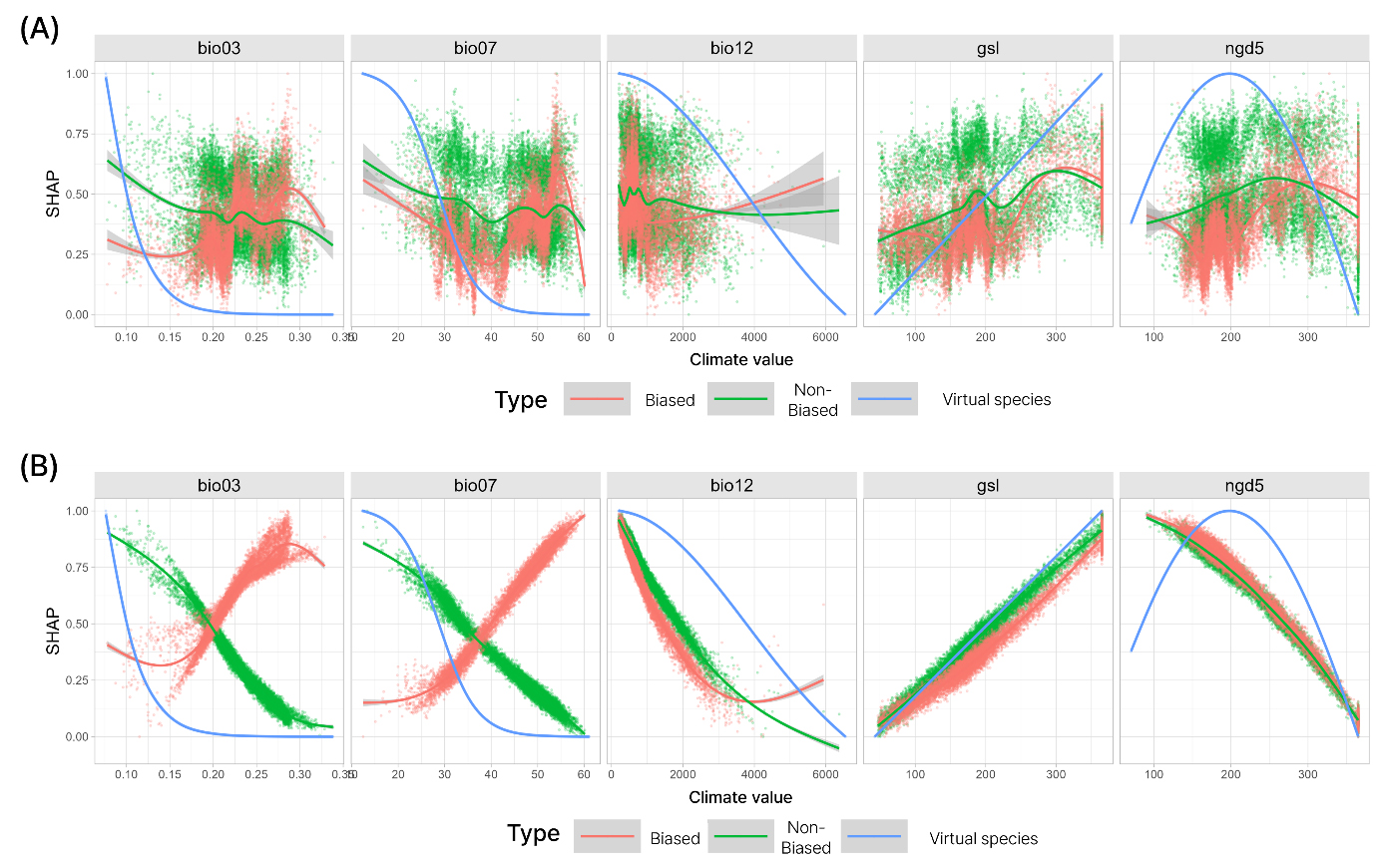
해석 성능은 출현 자료의 공간 편향이 존재할 때 전역적으로 낮아지는 걸로 나타났으며 이러한 현상은 두 모형 알고리즘 모두에게서 공통적으로 나타났다. 가상 종 시뮬레이션의 무작위 반응 함수는 상대적으로 단순하게 설정했기 때문에 MaxEnt 모형의 Feature class로도 충분히 반응 함수를 포착할 수 있었다. 그림 7A에서 나타나듯, 출현 자료의 공간 편향은 모형의 반응 함수 해석에 부정적 영향을 미치며 그 예로 Bio03, Bio07의 경우 전혀 상반된 반응 함수를 추정했다. 이는 모형 연구 결과의 해석을 현실과 반대로 추론할 수 있는 경우를 제시하며 Bio12와 gsl의 경우 상반되지 않더라도 편향이 해석 정확도에 부정적인 영향을 미칠 수 있음을 확인했다.
Bio03(등온성 지수)은 반응 함수의 경우 등온성이 높아질수록 부정적인 서식처 기여가 나타나는, 즉 부의 상관 관계를 지닌 가상 종을 시뮬레이션되었다(그림 7). 하지만, 편향이 있는 출현 자료로 적합된 MaxEnt 모형은 이를 정의 상관 관계로 해석하였다. 이처럼 실제와는 전혀 다른 해석이 Bio07(연교차) 변수에서도 확인되었다. Bio03 과 마찬가지로, 연교차가 높을수록 서식처 적합도에 음의 기여가 나타나도록 추정되어야 하나 오히려 연교차가 높을수록 서식처 적합도에 양의 기여를 하는 것으로 나타났다. 모형 해석의 방향은 유사하더라도 그 정확도가 저하되는 경우 또한 확인할 수 있었다. Bio12(연강수량)의 경우, 편향 모형과 비편향 모형 모두 그 경향을 잘 해석해내었다. 하지만, 편향 모형은 비편향 모형에 비해 보다 더 가파른 반응 함수를 보였으며, 실제와 유사한 해석을 보인다고 판별하기는 어려웠다. 이처럼 출현 자료의 편향은 모형의 해석을 정반대로 나타내거나 정확성이 떨어지는 등 모형 해석에 큰 영향을 주는 것으로 확인되었다.
반면, RFds 모형은 반응 함수 포착이 불가능한 것으로 나타났다. 거의 모든 변수에서 모형 해석의 복잡성이 크게 나타났으며 많은 환경 구배에 걸쳐 서로 유사한 Shapley 값이 나타나 해석이 어려웠다. 이러한 경향은 비편향 모형에서도 동일했으며 직접적인 비교는 불가능하였다. 각 국소 해석의 분산이 크게 나타났으며 반응 함수 모사의 민감도가 무척 높게 나타났기 때문이다. 즉, RFds 모형은 편향이 부재하여도 단순한 환경 반응 함수를 재현하기 어려웠으며 편향이 추가될 경우 그 왜곡이 더욱 심화되는 것으로 확인되었다. RFds 모형은 불균형 데이터 처리를 위한 다운 샘플링 과정에서, 정보 손실이 발생하여 미세한 환경 반응 구배를 포착하는 해상도가 낮아졌을 가능성이 있다. 모형의 하이퍼파라미터 수정 또는 복잡한 가상 종 시뮬레이션을 통해 RFds 모형에서도 충분히 반응 함수의 재현을 시도할 수 있지만 본 연구의 대상이 아님으로 추가적인 분석을 진행하지는 않았다.
IV. 토의
연구 결과, 출현 자료의 공간 편향은 지위 절단을 강화시켜 종 분포 모형의 예측 성능과 해석 성능에 모두 부정적인 영향을 끼쳤다. 예측 성능 하락의 측면에서는 가상 종과 기후 변수 및 알고리즘에 따라 그 강도가 상이했다. 하지만 예측 성능 하락은 시뮬레이션 조건 또는 지역과 상관없이 일반적이었다. 모형 해석 성능의 측면에서는 기후 반응 함수를 반대로 모사하거나, 유사하게 모사하더라도 부정확한 경향이 확인되었다. MaxEnt 모형은 평균적으로 RFds 모형보다 높은 예측 성능을 나타냈으며 해석 성능 시험에서도 동일하게 나타났다. 이를 통해 일반적으로 예측 성능이 높은 모형은 해석 성능 또한 높다고 추정할 수 있으며, MaxEnt 모형에서 나타난 아고산 지역의 예측 성능 하락은 곧 해당 지역에서의 해석 성능 하락으로 이어질 것이라 추론할 수 있다.
출현 자료의 공간 편향은 해당 지리 공간과 환경 공간 모두에서 예측 성능 하락이 관측되었다(그림 5). 북한 지역에 대한 출현 자료가 편향되자, RFds 모형에서는 북한 지역에서 예측 성능 하락이 강하게 나타났다. MaxEnt 모형에서는 남한의 아고산 지역에서 예측 성능 하락이 나타났다. 즉, 모형 알고리즘의 구조에 따라 지리 공간(Geographical space) 또는 환경 공간(Environmental space) 모두에서 부정확한 예측이 발생할 수 있음을 확인하였다. 이를 통해 출현 자료의 공간 편향이 단순히 지리 공간 상 예측 외삽을 제한할 뿐만 아니라, 환경 공간 상의 예측 외삽 또한 제한할 수 있음을 보였다. 일반적으로 지위 절단은 모형의 공간적 예측 성능에 주로 영향을 미치는 것으로 알려져 있지만(Veloz, 2009) 본 연구는 유사한 환경 공간에서도 예측 성능 하락이 나타날 수 있음을 보였다.
선행 연구들은 예측 성능 하락을 출현, 비출현 자료에 기반한 평가 지표로 제시하였다(Fourcade et al., 2014). 하지만, 본 연구에서는 가상 종을 통해 절대 오차를 제시하여 실제 예측 성능 하락을 살폈다. 이는 연구자가 모델링 연구를 진행할 때, 출현 자료에 포함된 공간 편향을 인식하기가 어려울 뿐만 아니라 이를 인지하더라도 적극적인 대응 방안이 부재하기 때문이다. 상관 모형 기반의 종 분포 모형의 검증에는 주로 출현, 비출현, 배경 자료를 활용한 지수를 사용한다. 하지만 만약 검증에 사용되는 출현 자료에 이미 공간 편향이 포함되었다면, 그 자료에서 산출된 지수는 신뢰하기 어렵다(Phillips et al., 2009). 이는 모형의 전이 가능성(Transferability)에 대한 주제와 맞닿아 있으며 Area Under Cover(AUC) 등의 검증 지표가 편향이 포함된 상태에서는 높게 나타나더라도 실제 종의 분포 예측은 실패할 수 있기 때문이다(Fourcade et al., 2014).
출현 자료의 공간 편향으로 인해 발생한 지위 절단 문제를 해결하기 위해 여러 기법들 제안되어 왔다(Chevalier, et al., 2022; Adde et al., 2023; Boria et al., 2014; Kramer-Schadt et al., 2013). 그럼에도 불구하고, 실제로 데이터가 부재해 발생하는 지위 절단 문제는 여전히 해소되지 못하고 있다. 현실적인 한계로 인해 데이터 부재를 극복하지 못한다면, 구체적인 모형의 신뢰 구간을 파악하고 오차 발생의 위치와 환경 조건을 이해하는 것이 보다 현실적인 접근법이 될 수 있다. 특정 지역에 한정된 연구나 특수한 응용 목적에서는 이러한 공간 편향이 문제되지 않을 수 있기 때문이다. 본 연구에서 제시된 분석 결과는 북한 지역에서 발생한 출현 자료의 공간 편향으로 인해 북한 뿐만 아니라 대한민국 내 서식처 적합도 예측 성능이 저하되며 이는 다양한 가상 종에 걸쳐 일반적임을 보였다. 하지만 최대 엔트로피 모형을 사용한 경우와 남한 내 일부 지역에서는 예측 성능 저하가 매우 낮게 나타났다. 즉, 해당 지역에 대한 연구 및 응용의 맥락에서는 공간 편향이 문제시되지 않을 수 있음을 제시했다. 본 연구는 북한 지역의 출현 자료 편향이 종 분포 모형의 예측과 해석에 심각한 결함을 야기할 수 있는 지역과 상대적으로 양호한 지역 및 그 맥락을 제시하였으며, 공간 편향이 기후 변화 연구에서 보다 심도 있게 고려되어야 함을 밝힌다. 향후 모형 연구에서는 보다 다양한 모형 알고리즘에서 유사한 현상이 재현되는지 살피고, 추가적인 지위 절단 해결 방법을 개발할 필요가 있다. 특히 본 연구에서 확인된 바와 같이, 모형의 예측 및 해석 성능은 알고리즘에 따라 상이할 수 있으며, 예측 성능이 뛰어난 모형이 대체로 해석 성능도 우수하게 나타나는 경향이 있음에 주목할 필요가 있다. 예를 들어, 예측 성능이 뛰어난 모형의 서식처 추정을 통해 더 나은 배경, 임의 비출현 자료 배치 방법을 고안하는 방법 등 모형 간 연계를 통한 보정 방안도 모색할 수 있을 것이다.
본 연구 결과는 기후 변화 시나리오에 따른 생물 종 분포 변화 연구에 편향 없는 고품질 출현 자료가 필수적임을 재확인하였다. 생물 종의 기후 지위를 온전히 반영하는 출현 자료가 부재한다면 예측력 저하가 불가피하며, 이에 기반한 미래 분포 예측 또한 크게 왜곡될 수 있다. 다시 말해, 출현 자료의 공간 편향은 종 출현-환경 변수 사이 상관 관계에 기반한 종 분포 모형의 활용성을 근본적으로 약화시키며, 이는 곧 모형 결과에 기초한 보전, 적응 전략의 공간 계획 수립에도 직접적인 제약을 가한다. 출현 자료의 공간 편향 문제가 해소되지 않는다면, 종 분포 모형은 국제적인 생물 다양성 보전 정책과 목표 이행을 지원하는 도구로 충분히 활용되기 어렵다. 예를 들어, 쿤밍-몬트리올 글로벌 생물다양성 프레임워크의 2030년 실천 목표(Global Biodiversity Framework 2030 Action Targets) 중 하나는 “전 지구 육상・해양에 대한 생물다양성 통합 공간계획 수립”과 “생물다양성이 높은 중요 지역의 손실을 30년까지 제로화”하는 것이다. 이러한 목표의 이행 과정에서 종 분포 모형은 중요한 과학적 근거를 제공할 잠재력을 지니지만, 그에 앞서 출현 자료의 공간 편향이 충분히 진단되지 않는다면, 모형 결과를 바탕으로 한 정책 수립과 우선순위 설정은 필연적으로 왜곡될 수 있다.
현재 국내외 자연 보전 관련 기관들은 기후변화 생물지표종의 분포 현황을 모니터링하고, 미래 분포 변화 예측 및 외래종 확산 가능성에 종 분포 모형을 폭넓게 활용하고 있다. 하지만 국내에서 수행된 선행 연구들 가운데 상당수는 모형 적합에 활용된 출현 자료의 공간 편향을 체계적으로 진단하지 않거나, 이에 대한 교차 검증 결과를 충분히 제시하지 않은 채 모형의 예측 및 해석 결과에만 초점을 맞히는 경향이 있다. 본 연구는 이러한 상황에서 출현 자료의 공간 편향이 적절히 처리되지 않을 경우, 미래기후 하에서의 분포 예측이 실패할 수 있을 뿐 아니라, 생물 종의 선호 환경 해석이 실제와 정반대로 도출될 수 있음을 실증적으로 보였다. 따라서 향후 연구자들은 모형 적합 과정에서 출현 자료의 공간 편향을 사전에 진단하고, 이 편향이 모형의 예측 및 해석에 미치는 영향을 정량적으로 연구 결과에 포함시킬 필요가 있다. 이러한 정보가 정책입안자와 의사결정자들에게 함께 제공될 때, 종 분포 모형의 결과에 대한 신뢰성이 높아지고 과학적인 보전 정책 수립 및 모형 기반 의사결정이 보다 투명하고 책임 있게 이루어지는 관행이 정착될 것으로 기대된다.
V. 결론
본 연구에서는 출현 자료의 공간 편향이 종 분포 모형의 예측 및 해석 성능에 미치는 영향을 파악하고자 기후 변화 시나리오 하에서 동북아시아 일대에 북한 지역의 출현 자료 공백이 모형 결과에 미치는 영향을 정량적으로 분석하였다. 분석 결과, 북한 지역의 출현 데이터 공백은 모형의 예측과 해석 성능에 부정적인 영향을 미쳤으며 광범위하고 일반적인 현상이었다. 모형의 예측 및 해석 성능 하락은 단순히 특정 공간에 제한되는 것이 아닌, 모형의 환경 공간 내에서도 확인할 수 있었으며 교차 검증의 방법을 통해 데이터 내 존재하는 이질성을 보다 자세하게 분석할 필요가 있음을 제시한다.
