

I. 서론
II.시계열 예측 모형
III. 분석 자료와 방법
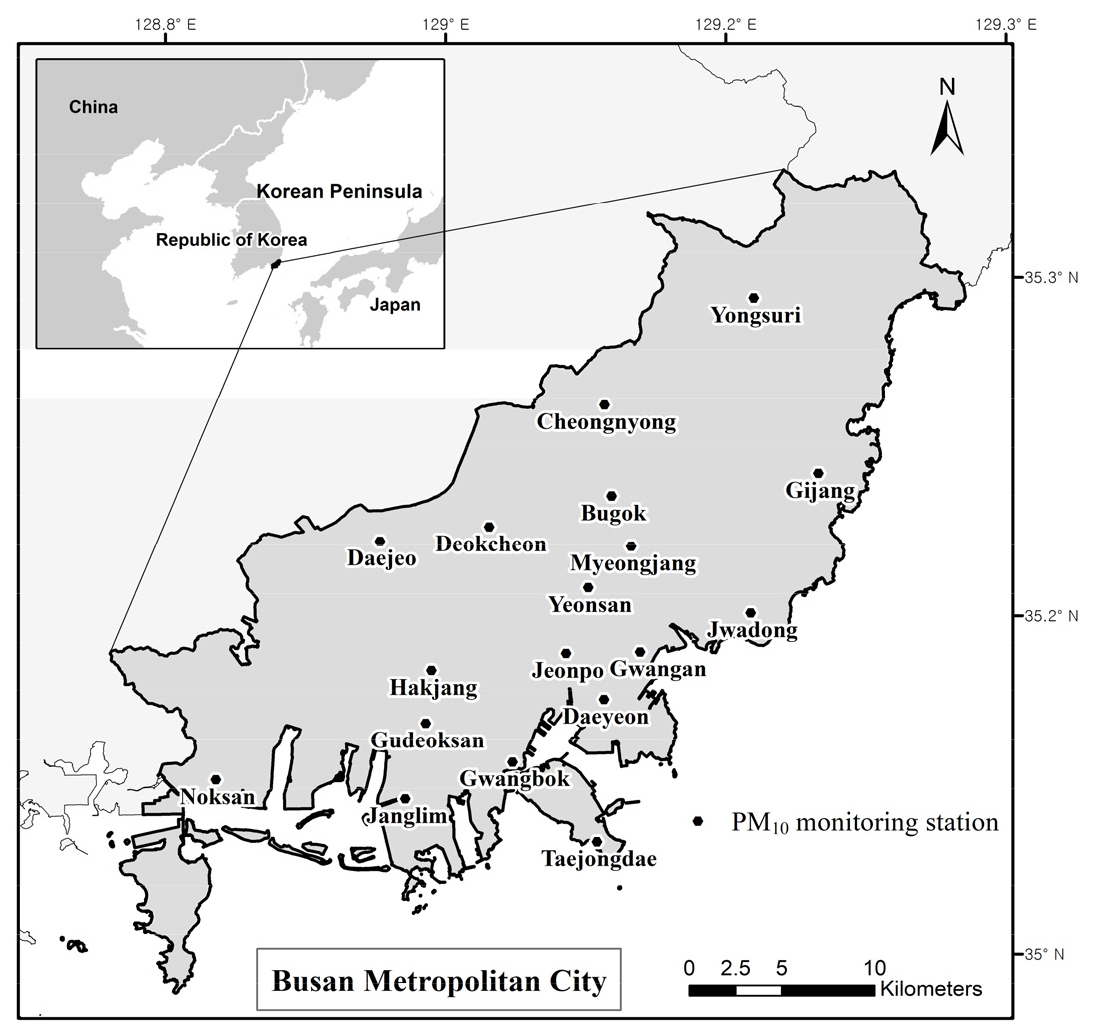
1. 연구 지역
2. 분석 자료 및 방법
IV. 연구 결과 및 논의
1. 군집별 대기 중 미세먼지 농도 변화
2. Prophet 모형의 예측 성능 평가
3. Prophet 모형 매개변수(parameter)의 영향
V. 요약 및 결론
I. 서론
대기 중에 부유하는 직경 10μm 이하의 물질을 PM10(particulate matter 10)이라 한다. PM10은 통상 미세먼지로 불리는 대표적인 대기 오염물질로서 자연환경적 요인과 인위적 요인에 의한 영향을 받으며, 그 시공간적인 농도 변화는 계절적 특성을 나타낸다. 대기 중 미세먼지 농도는 국내뿐만 아니라 국외 공해물질의 이동에 의해 민감하게 변화하기 때문에 이로 인한 문제는 단순한 사회적 관심의 수준을 넘어, 국민의 일상생활, 공중보건, 산업활동 전반에 악영향을 주는 국가적 의제가 되었다. 우리나라 대도시의 대기 중 미세먼지 농도는 세계보건기구 환경기준치를 크게 상회하고 있으며 호흡기 및 심혈관 질병과 깊은 연관을 가지고 있어서 가장 시급하게 개선해야 할 일상적인 도시환경 문제로 인식되고 있다(Dockery and Pope, 1994; Kwon et al., 2002; 전병일, 2010; 정종철, 2014). 우리나라 미세먼지 농도는 봄과 겨울철을 중심으로 크게 증가하는 특징을 나타내지만, 대기 공해물질의 장거리 이동과 황사현상의 계절적인 확장으로 인해 미세먼지 문제에 대한 효과적 대응이 쉽지 않다(Chung and Yoon, 1996; Lee and Hills, 2003; 박선엽, 2014). 특히, 중국발 공해물질 등 우리나라 대기질에 미치는 외부적 요인의 영향은 아직 명확하게 알려져 있지 않고 산업시설 배출물과 차량배출 공해물질 축적과 같은 국지적 발생원을 둔 미세먼지의 비중도 적지 않은 것으로 추정되고 있으므로, 대기 중 미세먼지 농도 변화의 원인을 파악하거나 그 변화 양상을 추정하고 예측하는 것은 매우 복잡하고 어려운 일이다. 우리나라 대기질 정보는 2000년대 초반부터 제한적으로 공개되기 시작했으나 국민적 관심과 요구에 따라 지금은 전국적 대기측정망을 통한 관측 자료를 기반으로 일상적으로 예보되어야 할 주요 사안으로 자리 잡았다.1)
지리적으로 한반도 동남부 해안에 위치한 부산광역시는 외부적 요인과 주요 발전 시설과 같은 내부적 요인으로부터의 영향이 상대적으로 적지만, 선박과 차량 배출물질로 인하여 평균적인 미세먼지 농도는 국내 대도시 중에서 매우 높은 편이어서 지속적이고 적극적인 관리가 필요하다(전병일, 2010; Park, 2018; 김대래 등, 2021). 부산광역시 전체로 보면, 대기 중 미세먼지 평균농도는 계절적으로 봄철과 겨울철을 중심으로 높게 관측되지만 관측지점에 따라 평균농도 수준과 계절별 농도 순위는 서로 차이를 보인다(Park, 2017a; Park, 2017b). 더욱이, 1980년대 이후 진행된 도시역의 확장으로 인하여 산림과 농경지 면적이 크게 감소하고, 공단지역, 주거지, 상업지역 등 토지이용의 다양성으로 인해 도시 내부 미세먼지 농도는 관측지점 간에 유의미한 차별성을 나타낸다(박선엽・탁한명, 2013; 김미경, 2017; 전병일, 2018; 김대래 등, 2021; 박선엽, 2021). 대기 중 미세먼지 농도는 보다 단기적인 스케일, 즉 시간대별 및 요일별로도 일정한 주기성이나 차이가 나타날 뿐만 아니라 주말, 휴일, 또는 명절 연휴와 같은 이벤트 효과 등이 대기질에 대한 추가적 영향 요인으로 작용할 수 있다. 이뿐만 아니라 최근에는 인간활동을 제약하는 감염병 확산이 대기질을 시공간적으로 변화시키는 중요한 영향 요인으로 등장하였다(성현곤, 2016; 박선엽, 2020; 유철규, 2020). 예를 들어, 2019년에 발생한 코로나바이러스감염증 2019(코로나19)가 우리나라에 본격적으로 확산되던 2020년에는 교통수단별 수송량이 감소하였고, 중앙정부 차원의 감염병 통제 정책으로 인해 국민의 이동량이나 도로통행량도 감소하였다(장동익 등, 2020). 이러한 이례적이고 불규칙적인 인자는 인간 활동의 영향이 직접적으로 반영되는 토지이용 특성과 결합하여 일반적인 대기질의 계절적 주기성이나 변화 패턴을 국지적으로 변화시키기 때문에 대기 모니터링 및 예측 업무는 꾸준히 보완 및 평가되어야 한다.
일기예보와 같이 단기적인 시간 범위에서 기상 조건 변화에 따른 대기질 예측 결과를 공지하는 것도 중요하지만, 보다 장기적이고 안정적인 대기질 전망을 위해서는 연속적으로 관측된 자료에 기초하여 미래의 변화 경향을 예측하는 작업도 필요하다. 일정 시간 간격으로 수집된 시계열 자료의 양이 축적되면 개별 자료가 갖게 되는 반복적 특성을 파악할 수 있게 되고, 그러한 시계열적 특성이 미래에도 발생할 것으로 예상될 경우, 해당 현상의 정량적인 미래 예측이 가능해진다(Hyndman and Athanasopoulos, 2021). 예를 들면, 백화점의 분기별 매출량, 주요 기업의 주가, 월평균 강수량과 기온, 월별 항공수요, 인체의 심장 박동 등 생활 주변의 다양한 현상들은 각기 고유한 시계열적 특성을 포함하고 있다. 미세먼지 농도 역시 일정한 시간 간격을 두고 반복적으로 관측되는 대표적인 시계열 자료로서 일정한 스케일에서 주기성을 갖고 있기 때문에 장기 관측 자료를 기반으로 한 시계열 분석과 예측을 적용하기에 적합한 대상이다. 즉, 시계열 자료는 일정한 방향으로 진행하는 ‘경향성(trend)’, 일정 시간 간격으로 반복되는 ‘계절성(seasonality)’, 불규칙적인 잡음 요인에 해당하는 ‘무작위적 신호(randomness)’ 등의 주요 성분의 합으로 이해 할 수 있으며, 이들 개별 성분 또는 요인들은 시계열 모형을 이용하여 분해함으로써 그 변화 특성을 파악해 낼 수 있다(Wild and Seber, 2000; 박찬성 역, 2021). 시계열 예측을 위해 개발된 많은 모형 중 본 연구는 2017년 Facebook이 공개한 Prophet2) 모형의 예측 성능을 평가하고자 한다. Prophet은 기본적으로 시계열 예측을 curve-fitting 과정으로 전제하고, 입력되는 시계열 자료를 가장 적절히 표현할 수 있는 함수식을 계산하거나 추정하는 과정을 따른다. Prophet은 일반적으로 여타 예측 모델들이 요구하는 자료의 정상성(stationarity)3)을 확보할 필요가 없고, 결측치가 있어도 처리 가능하며, 이례치에 대한 대응도 유연한 강점을 가지고 있을 뿐만 아니라 관측 자료의 변화 추세나 시계열적 주기성과 연관된 매개변수 조건의 영향력을 파악할 수 있다(나종화, 2020; Rafferty, 2021). 본 연구는 Facebook에서 개발한 시계열 분석 모형인 Prophet을 이용하여 부산광역시 대기 중 미세먼지 농도의 주기적 특징을 분석하고 시계열적 예측 성능에 미치는 주요 매개변수의 영향을 평가하고자 한다.
II.시계열 예측 모형
시계열 자료의 예측과 관련된 가장 간단하며 고전적인 방식은 이동평균법(moving average)이다. ‘평활법(smoothing technique)’이라고도 불리는 이동평균법은 일정 수준의 분산을 갖는 관측값 사이를 가로지르는 추세선를 찾고자 할 때 사용된다. 이 방법은 시간적 순서에 따라 배열된 각 관측값에 대해 해당 관측 시기 전후에 분포한 일정 개수의 자료값을 평균함으로써 무작위적 신호를 제거하고 자료의 시계열적 추세선을 산출하는 원리를 따른다. 시계열 예측을 위해서는 이미 관측된 자료값에 대해 ‘윈도우 크기’라고 불리는 일정 시간 단위만큼 과거로 거슬러 올라간 범위에서 평균값을 계산하기 때문에 이동평균법은 윈도우 크기가 커질수록 산출되는 결과가 시간적으로 지연되는 단점을 갖게 된다. 대기질과 같은 시계열 자료는 시간적으로 독립적이지 않고 시계열적으로 서로 가까운 자료일수록 상호관련성이 크기 때문에 일정 시점의 이동평균값을 산출할 때, 해당 관측시기에 가까운 관측값에 더 많은 가중치를 부여하는 방법, 즉 지수평활모델(exponential smoothing model)로 발전하였다. 이동평균법을 발전시켜 개발된 기법은 ‘자기회귀누적이동평균법(Autoregressive Integrated Moving Average, 또는 ARIMA)’으로 불리며 시계열 예측 분야에서 가장 일반적으로 사용된 모델이다.4) 이 방법은 분석 대상 시계열 자료를 가장 잘 설명하는 모델을 찾고, 그에 따라 미래 시점에 대한 예측을 수행하는 것을 목표로 삼는다(나종화, 2020). ARIMA는 이미 관측된 자료를 기초로 한다는 점에서 이동평균법과 유사하지만, 관측된 원 자료(raw data)보다는 ‘차분(differencing)’으로 불리는 관측값 간의 차이를 활용한다는 특징을 갖는다. ‘차분’은 ARIMA를 이용한 시계열 자료 분석에 필요한 입력 자료의 ‘정상성’ 조건을 만족시키기 위해 요구되는 자료 처리 과정이다. 즉, ARIMA 모델을 적용하기 위해서는 입력되는 시계열 자료의 평균과 분산이 시간의 흐름에 따라 일정해야 한다. 일정한 추세나 계절적 특성이 나타나는 시계열 자료는 흔히 ‘차분’을 통해 자료의 ‘정상성’이 확보되도록 변환된다. 일정한 시간 간격에 따라 수집된 시계열 자료에서, 시점 t에서의 y값 yt와 시점 t-1에서의 y값 yt-1을 차분 ∇yt = yt - yt-1로 정의한다. 차분의 차수는 차분을 반복 수행한 횟수를 의미하며 차분 기호의 윗첨자로 표시한다. 예를 들어, ∇2yt = yt - 2yt-1 + yt-2와 같이 표현하며, 이는 일차 차분된 시계열에 대해 차분을 재차 수행한 것이다. 통상, ‘ARIMA(p, d, q)’ 형태로 표현되는 ARIMA 모형은 그 예측 과정에 적용되는 세 가지 계수에 의해 특징 지워진다. ARIMA 모형에 사용되는 계수 p는 지연 차수(the number of lag observations)를, d는 차분하는 횟수를, q는 이동평균에 쓰이는 윈도우 크기를 각각 가리킨다. ARIMA 모델은 여러 특징적인 시계열 자료의 예측 성능을 개선하기 위해서 다양한 형식으로 진화했으며 전반적으로는 매우 우수한 예측 결과를 보이지만 모델의 복잡한 구조와 최적화를 위해 요구되는 숙련도는 근본적인 단점으로 작용한다.
Prophet은 기존의 시계열 예측 모형들에 흔히 내재하고 있는 두 가지 난점을 해결하기 위해 Facebook이 개발한 시계열 모형이다. Facebook이 제기한 첫 번째 난점은, 시계열 예측의 자동화를 위해 필요한 자료 처리에 관한 조건을 만족시키기 어렵다는 점이다. 다른 한 가지는, 안정성 높은 모델 적용을 위해서는 자료 분석가의 과학적 이해도와 전문 역량이 필수적으로 요구된다는 점이다. 오픈 소스 기반으로 개발된 Prophet은 2017년에 일반 대중에게 공개되었으며, 기존의 시계열 예측 모형에 비해 몇 가지 장점을 갖는다. 우선, Prophet에 사용되는 자료의 시계열적 간격이 일정해야 할 필요가 없기 때문에 불연속적인 자료의 사용이 가능하다. 둘째, 앞서 논의한 ARIMA 모형의 적용에 필요한 자료의 ‘정상성’ 확보를 위해 ‘차분’ 과정이 필요 없다. 셋째, 시계열 자료 확보 과정에서 흔히 나타나는 문제 중 하나인 ‘결측치’나 ‘이상치’ 처리에 매우 유연하기 때문에, 결측치를 대치하기 위한 보간 또는 이상치 처리 과정이 필요 없다. 넷째, 일반적인 시계열 추세와 반복적 계절성뿐만 아니라 시계열 예측에 영향을 주는 주말, 휴일, 연휴, 특별 이벤트 등의 특징적인 시간 요인을 함께 고려하여 예측력을 높인다. 다섯째, 시계열 자료에 대한 통계적 지식이나 시계열 모형의 수학적 지식 없이도 Python이나 R 프로그래밍의 기초적 이해를 기초로 시계열 분석 과정을 구현해 낼 수 있다.
Prophet은 기본적으로 가법 모형(additive model)에 기반해 있다. 즉, 전체 Prophet은 시계열 자료(y(t))를 4개의 주요 모델 요소들로 구조화된 형식으로 표현한다(Harvey and Peters, 1990; Taylor and Letham, 2018; 나종화, 2020; Hyndman and Athanasopoulos, 2021):
식 1에서 g(t)는 자료의 시계열적 추세(trend), s(t)는 계절성(seasonality), h(t)는 휴일 효과(holiday effect), ϵt는 모형으로 설명되지 않는 오차항을 각각 나타낸다. 시계열적 추세는 모형에 의해 적합화되는 비주기적 변화로서 구간별 직선(piecewise-linear trend) 또는 로지스틱 변화 곡선(logistic growth curve)으로 나타난다. 계절적 요소는 푸리에 급수를 사용하여 일별, 주간별, 연중 변화 사이클과 같은 다양한 주기적 변화를 나타낸다. 휴일 효과는 추가적으로 부여되는 더미 변인(dummy variable)으로서, 분석자는 정기적이거나 비규칙적인 주말, 휴일, 연휴와 같은 요인을 예측 모형에 선택적으로 적용할 수 있다.
III. 분석 자료와 방법
1. 연구 지역
부산광역시는 우리나라 동남권 중심도시이며 인구 약 340만 명 규모를 가진 수도권 이외 최대 도시이다(김대래 등, 2021; 그림 1). 도시의 서부는 전통적인 농업지역과 공업지역의 비중이 높고 비교적 평탄한 지형적 특징을 갖는 반면, 북부와 동부는 산지 면적이 높다. 중부 지역은 전반적으로 상업활동이 중심을 이루고 있으며, 중앙부 저지대와 낙동강변을 따라 도시 주요 교통망이 분포해 있다. 경관 구조로 볼 때, 지난 60년간 도시의 빠른 확장으로 부산광역시의 면적은 2배 이상으로 증가하였고 산림과 농경지 면적은 크게 감소하는 등 토지이용의 광범위한 변화로 인하여 도시 내 대기질 변화는 시공간적 차별성을 나타내고 있다(이금숙, 2008; 박선엽・탁한명, 2013; Park, 2017a; Park, 2017b; 김대래 등, 2021; 박선엽, 2021). 부산광역시의 연평균기온은 15.0℃로 온화한 편이며, 6~8월 동안의 강수량이 연강수량(1576.7mm)의 절반 가량을 차지하고 있어 하계 강수집중도가 높다(기상청, 2021). 미세먼지 평균농도의 공간적 분포는 대체로 서고동저의 패턴으로 나타나는데, 계절적으로 볼 때 동서 간 농도 차이는 봄철에 비해 겨울철에 더 크게 발생하는 추세이다(박선엽, 2021; 박선엽, 2022).
2. 분석 자료 및 방법
1) 대기 중 PM10 농도 자료
본 연구는 도시 대기질 관측소 중에서 최근 16년간(2006~2021)의 관측 자료가 90% 이상 연속적으로 확보된 18개 지점의 미세먼지 농도 자료를 분석 대상으로 하였다(그림 1). 시간대별 농도 자료는 기상청 기상자료개발포털(https://data.kma.go.kr/)과 한국환경공단에서 운영하는 에어코리아(http://airkorea.or.kr/) 사이트를 통해 수집하였다. 시간대별 관측값 중 누락치가 있는 경우, 전체 24시간 자료 중 75%(18시간) 이상 관측된 경우에 한하여 일평균 자료를 생성하였으며, 매월 20일 이상의 일평균 자료가 확보된 경우에 한하여 월평균 자료를 산출하였다. 일반적으로 미세먼지 농도 수준이 이례적으로 상승하는 황사일 자료는 월평균농도 수준을 높이고, 황사 현상은 강도와 빈도 측면에서 불규칙적인 속성을 나타내기 때문에 분석을 수행함에 있어 황사일을 제외한 월평균농도 자료를 별도로 산출하여 Prophet 모형에 적용하고 원 자료 기반의 분석 결과와 비교하였다.
2) 분석 방법
(1) Prophet 예측 모형
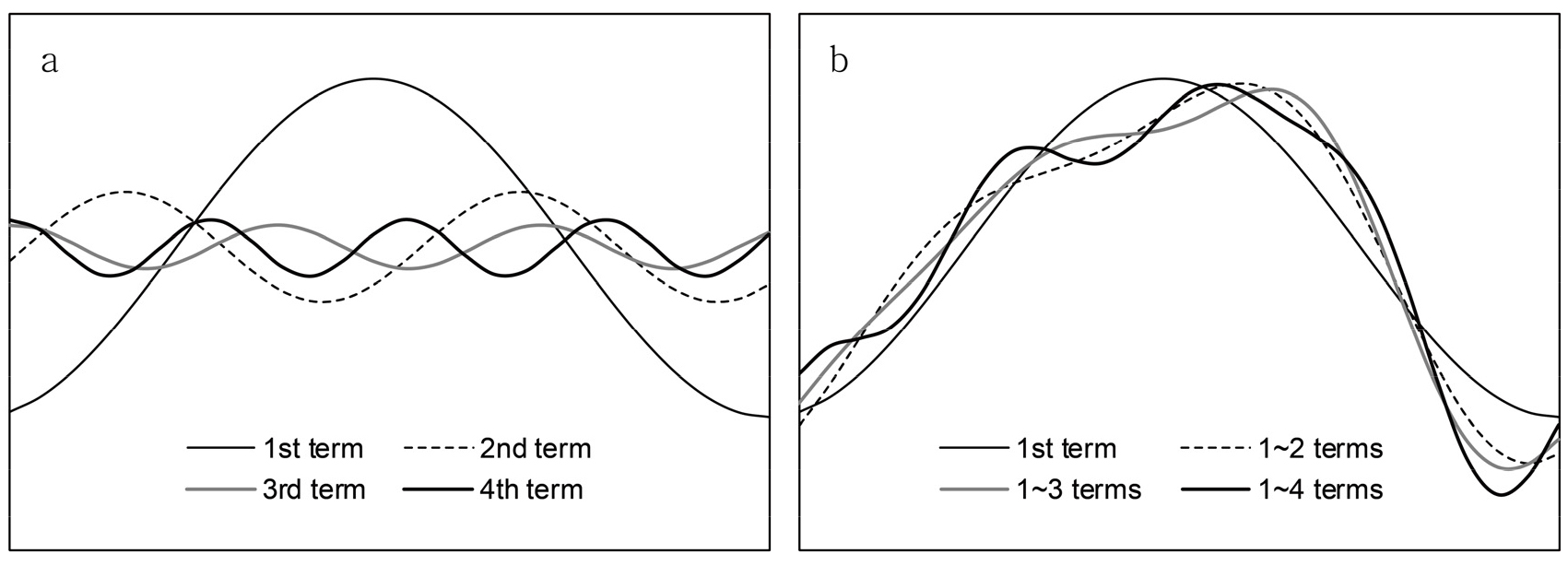
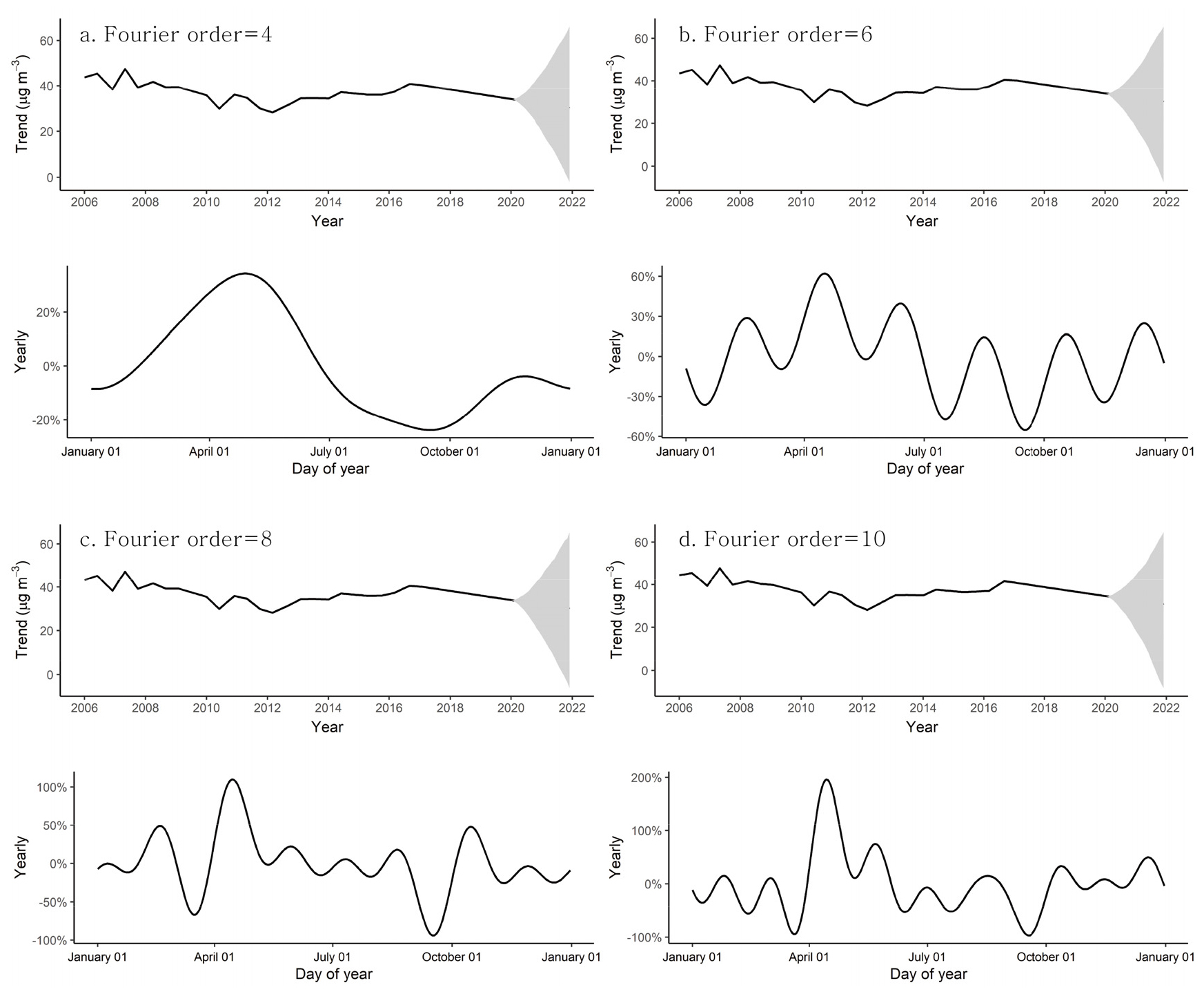
Prophet 모형은 오픈 소스 기반의 소프트웨어로, 프로그래밍 언어인 R 또는 Python을 통해 구동될 수 있다. 본 연구에서는 R을 사용하여 미세먼지 농도 시계열 자료를 처리, 분석 및 시각화하였다. R 프로그래밍은 사용자들의 필요와 용도에 따라 개발된 코드의 집합, 즉 ‘패키지(package)’ 형태로 운용된다는 특징을 갖고 있으며, 사용자들은 특정 용도와 목적을 위해 개발된 패키지를 온라인으로 다운로드하여 개별 패키지별로 내재화된 함수 도구들을 자신들의 필요에 따라 활용할 수 있다.5) Prophet 모형은 예측의 적합도를 높이기 위해 몇 가지 매개변수(parameter)를 선택적으로 조정할 수 있는 기능을 제공한다(Rafferty, 2021). 본 연구에서는 모형 적합도 개선을 위해 모두 4가지의 매개변수 조정을 수행하였다. 첫 번째 변수로는 자료의 시계열적 변화 패턴을 규정하는 계절성 모드(seasonality mode)이다. 이는 계절적으로 반복되는 대기 중 미세먼지 농도의 연간 등락 폭이 일정 수준으로 유지되는지 혹은 변화 폭이 증가 또는 감소하는지 여부와 관련된 것이다. 두 번째는 미세먼지 농도 자료의 연간 변화를 제한된 수의 파형 곡선, 즉 푸리에 급수(Fourier series or terms)의 합으로 모델링할 때 적용하는 급수의 한도(Fourier order)와 관련된다. 시계열적으로 민감하게 상승과 하강을 반복하는 입력 자료의 시계열적 특성을 몇 개의 파형 곡선의 합으로 구현할 것인지에 따라 예측 모형의 결과는 과소적합(underfit)되거나 과대적합(overfit)되기 때문에 최적의 적합도를 산출하기 위해 이에 대한 평가가 필요하다. 푸리에 분석은 대기 및 기후 자료와 같이 연속적이며 반복적인 시계열 신호를 정형화된 주요 파형 곡선으로 환원해 내는 데에 유용한 수학적 기법이다. 푸리에 분석을 통해 생성되는 주요 파형은 각기 서로 다른 파장과 진폭을 갖는데, 생성 가능한 모든 파형을 합산하면 원 자료로 복원된다(그림 2). 원 자료 내에 존재하는 지배적인 주기성은 일반적으로 제한된 수의 파형으로 표현되기 때문에, 푸리에 분석은 일정 자료 속에 담겨 있는 복잡한 시계열 변화의 특징을 몇 개의 대표적인 주기 곡선으로 단순화하는 데에 널리 사용된다(Jakubauskas et al., 2001; Moody and Johnson, 2001; Park, 2003; Park, 2010; 박선엽, 2013).
세 번째는 자료 속에 나타나는 계절성 특징에 대한 선험적 지식을 기초로 예측값의 상승 또는 하강 폭을 제한하여 변동 폭을 감소시키는 계절성 제한 변수(seasonality prior scale)이다. 네 번째는 시계열 자료에서 흔히 나타나는 급변점 또는 변곡점 처리(changepoint prior scale)에 관한 변수이다. Prophet 모형은 자료의 변화 특징으로부터 기울기의 변화를 감지하여 자동적으로 변곡점을 탐지하고 이를 전체적인 변화 경향 곡선 산출에 반영한다. Prophet은 예측 모형의 과소 적합이나 과대 적합이 발생하지 않도록 자료상의 변곡점에 관한 통제력 수준을 조정하는 기능을 포함하고 있다.
(2) 예측 모형의 검증
예측 모형이 산출한 결과의 평가를 위해 두 가지 방법을 적용하였다. 첫 번째는 추정치와 관측치를 상호 비교한 결과로 Pearson 상관계수(correlation coefficient)와 오차제곱근(root mean square error or RMSE)이다. 이것은 코로나19가 본격적으로 확산되기 직전인 2019년까지의 미세먼지 농도 자료를 사용한 결과이며, 코로나19 영향이 반영된 2020~2021년 자료에 대해서는 2006~2019년 자료 기반의 예측 결과와 관측값을 상호 비교하였다. 두 번째로는 명령 함수 cross_validation()을 적용하여 교차검증(cross-validation)을 수행하였다. 교차검증법은 전체 시계열 자료 중 일부를 예측 모형 생성과 예측 결과의 검증을 위해 각각 사용하게 되는데, 예측과 검증 과정에 사용되는 자료 범위 중 시간적으로 후순위에 위치한 자료 일부를 검증 자료로 적용한다. 일반적으로, 교차검증을 수행하기 위해서는 예측 모형 생성을 위해 사용되는 초기 자료의 시간 범위가 설정되고, 그 이후로 일정 기간에 해당하는 검증 시간 범위가 설정된다. 검증에 사용되는 자료의 시작 시기(cutoff)는 반복되는 검증 횟수 증가에 따라 일정 간격을 두고 최근으로 이동해가며 설정되어 각 검증 사이클별로 결과가 산출되기 때문에, 이러한 교차검증 방식을 forward-chaining cross-validation이라고 부른다(Rafferty, 2021). 본 연구에서는 모두 4개의 자료 세트를 사용하여 교차검증을 실시하였다. 2017년 1월과 7월, 2018년 1월과 7월 등 6개월 간격으로 모두 4개 시점을 검증 시작 시기로 하고 각각에 대한 검증 기간은 1년으로 설정하였다. 예측 모형 구축을 위한 초기 모델링 기간은 2년으로 하여, 전체 4개의 검증 결과를 합산 평균하였다. 시계열 예측정확도 지수로는 평균절대비오차(mean absolute percent error, or MAPE), 즉 관측값에 대한 관측값()과 예측값() 간 편차의 합을 샘플 개수(n)로 나누어 평균한 값을 적용하였다(식 2):
(3) 군집분석(cluster analysis)
부산광역시 전역에 걸쳐 모두 18개 미세먼지 관측소를 대상으로 자료 수집이 이루어졌으나, 예측 모형의 적용을 위해서 개별 관측지점들을 제한된 수의 군집으로 구분하였다. 본 연구에서는 관측 지점별 대기 중 미세먼지 농도의 시계열적 변화 패턴에 따라 전체 관측 지점을 제한된 수의 유형으로 구분하기 위하여 군집분석을 수행하였다. 군집분석은 자료를 구성하는 다수의 개별 관측값들을 속성에 따라 한정된 수의 집단 또는 군집으로 분류하여 자료의 등질성과 이질성을 효과적으로 요약하고 자료의 특성과 패턴을 간명하게 나타내는 기법이다. 자료를 군집화하기 위해 필요한 개체들 간의 차별성이나 유사성은 다양한 방식의 통계적 정량화를 이용하여 상호간 근접도(proximity)를 통해 나타낼 수 있는데, 개체 간의 동질성이나 이질성에 근거하여 자료를 군집화할 때 광범위하게 적용되는 기법은 계층적 군집화이다(Gordon, 1987; Everitt et al., 2011). 본 연구에서는 자료의 군집화를 위해 보편적으로 쓰이는 Ward법을 적용하였다. Ward법은 군집화 과정에서 2개 집단이 결합하여 하나의 군집을 이루어 전체 집단 수가 감소할 때, 합쳐지는 두 집단의 가능한 조합 중 집단 내 오차제곱합(the error sum of squares, or ESS)의 증가분이 최소가 되어 동질성이 극대화되는 쪽으로 군집화를 진행하는 원리에 기반한다(Ward, 1963; Blashfield, 1980; Duflou and Maenhaut, 1990; Baxter, 1994).6) 본 연구에서는 주간 농도 변화 패턴을 시간 단위로 평균한 자료를 기초로 군집분석한 결과를 Prophet 예측 모형에 적용하였다.
IV. 연구 결과 및 논의
1. 군집별 대기 중 미세먼지 농도 변화
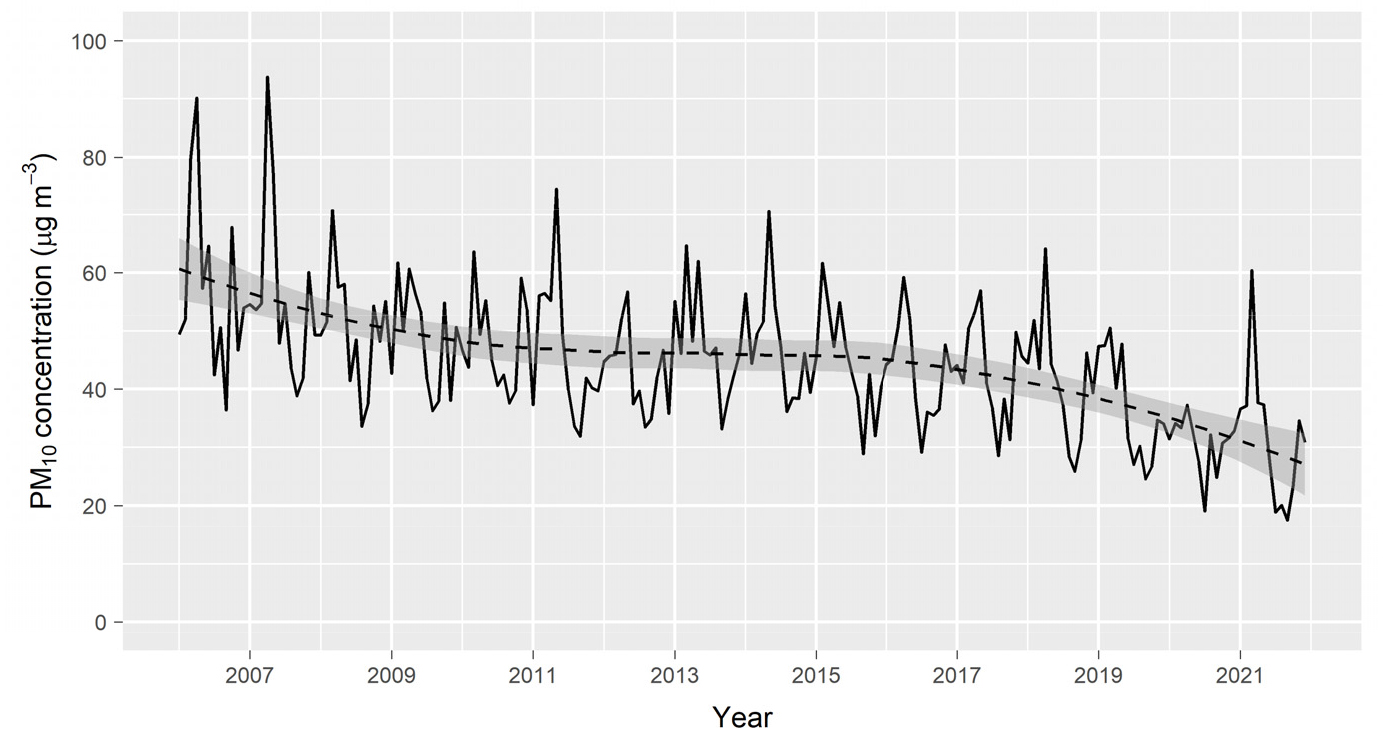
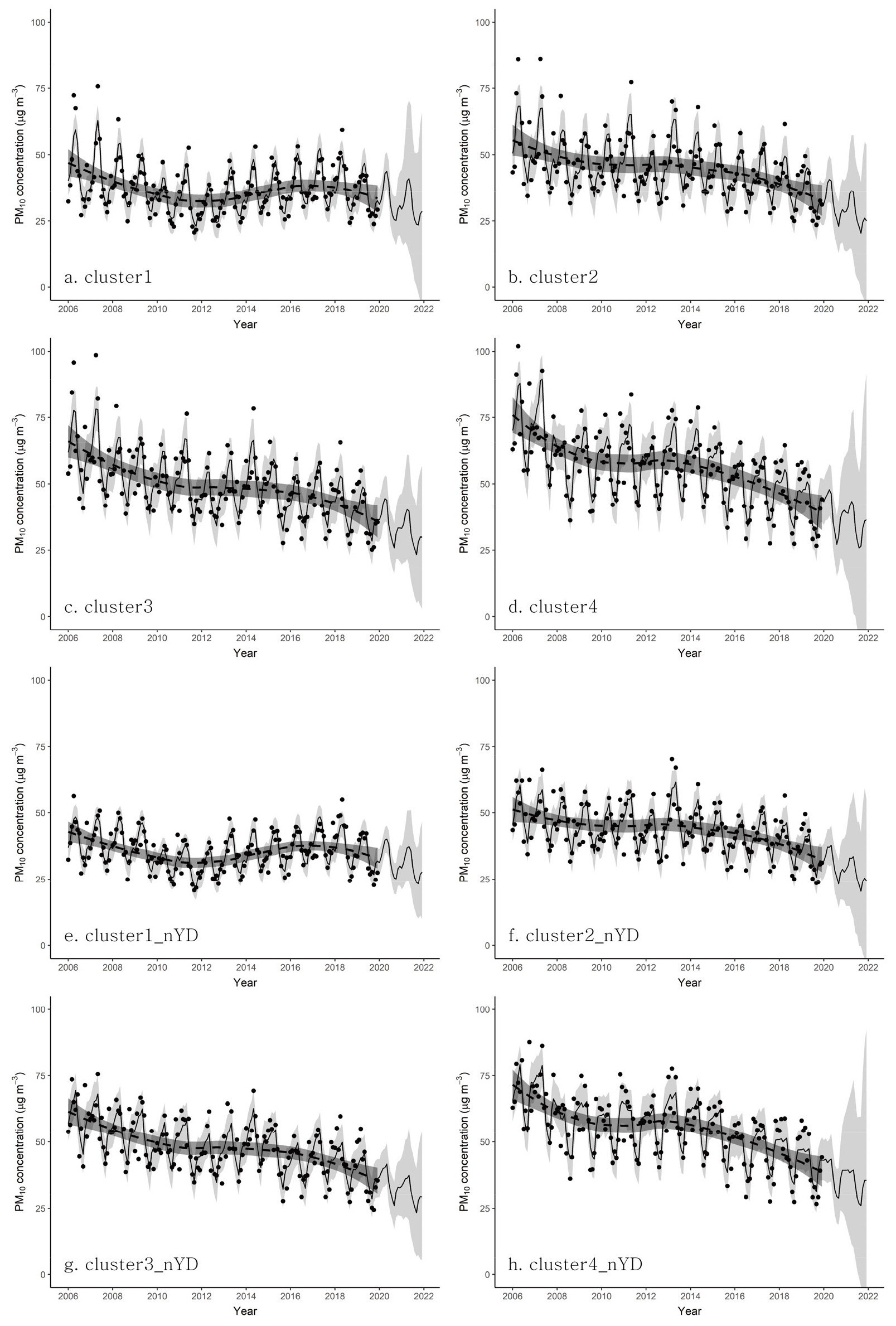
부산광역시 미세먼지 평균농도는 정책적 노력에 힘입어 지난 16년 동안 꾸준히 감소하는 추세를 보이고 있다.7) 도시 전체 평균농도로 보면, 대체로 2006년 이후 2012년까지 감소세를 보였고, 2014년경까지 농도 수준이 유지되다가 2015년부터 다시 대기질 개선이 이어지고 있다(그림 3). 전반적인 평균농도 감소 추세 속에서도 개별 관측 지점 간 농도 차이는 비교적 큰 편이며(34.0~56.0㎍m-3), 최근 조사에 의하면 일부 산악 지역과 주거지역에서는 뚜렷한 농도 변화가 나타나지 않았다. 계절적 미세먼지 농도 변화를 다룬 최근의 분석에 따르면, 봄철과 겨울철의 관측 지점별 농도 순위는 서로 차이를 보이지 않았고, 농도 수준이 높은 지점일수록 미세먼지와 초미세먼지 월평균농도 간의 상관도는 높아지는 경향을 보였다. 이러한 분석 결과로 볼 때, 최근 나타나는 부산광역시 대기질 개선에 미치는 외부적 요인의 영향은 크지 않은 것으로 추정된다. 또, 코로나19의 확산으로 인해 2020년부터 중국에서 시행된 강력한 주민이동통제로 인하여 광범위한 지역에서 일시적인 대기질 개선이 관측되었으나 초미세먼지 농도의 전반적인 수준은 여전히 높은 편으로 보고되었고, 일부 지역에서는 오히려 대기질 악화가 발생하기도 한 점은 우리나라 (초)미세먼지 농도 변화에 미치는 외부적 영향이 제한적임을 시사한다(박선엽, 2020; Bauwens et al., 2020; Chen et al., 2020; He et al., 2020; Le et al., 2020; Shi and Brasseur, 2020; 박선엽, 2021).
관측 지점별 미세먼지 농도의 시계열적 변화, 특히 평균농도 수준과 요일별 농도 변화 패턴을 입력 자료로 군집분석을 수행한 결과, 분석 대상 18개 관측 지점은 모두 4개의 군집으로 구분되었다. 도출된 4개의 군집은 평균농도 수준이 높아짐에 따라 군집1~4로 구분하였다(표 1, 그림 4). 군집1은 산악지역과 주거지로 구성된 집단이며, 미세먼지 평균농도는 가장 낮게 조사되었다. 군집2는 주거지, 상업 및 공업지역이 혼재된 혼합지역으로 분류되며, 군집3은 전통적인 상업지역이 주를 이루는 집단으로 분류되었다. 군집4는 연구지역 중 미세먼지 평균농도가 가장 높은 그룹이며, 전형적인 공업지역이 주를 이루는 집단이다(박선엽, 2021).
표 1.
군집별 미세먼지 농도 및 주요 토지이용
| 군집 1 | 군집 2 | 군집 3 | 군집 4 | |
|
평균농도 (㎍m-3) | 36.25±0.26 | 43.96±0.28 | 47.16±0.29 | 53.61±0.28 |
| 관측 지점 | 구덕산, 광안동, 기장읍, 좌동 |
부곡동, 용수리, 연산동, 대연동, 태종대 |
명장동, 청룡동, 전포동, 덕천동, 광복동 |
장림동, 학장동, 녹산동, 대저동 |
| 주요 토지이용8) |
산림(36.0%), 주거지(24.3%) |
주거지(22.6%), 산림(18.6%), 혼합지역(10.0%) |
주거지(24.9%), 산림(22.6%), 상업지역(10.2%) |
공업지역(46.0%), 농업지역(17.9%) |
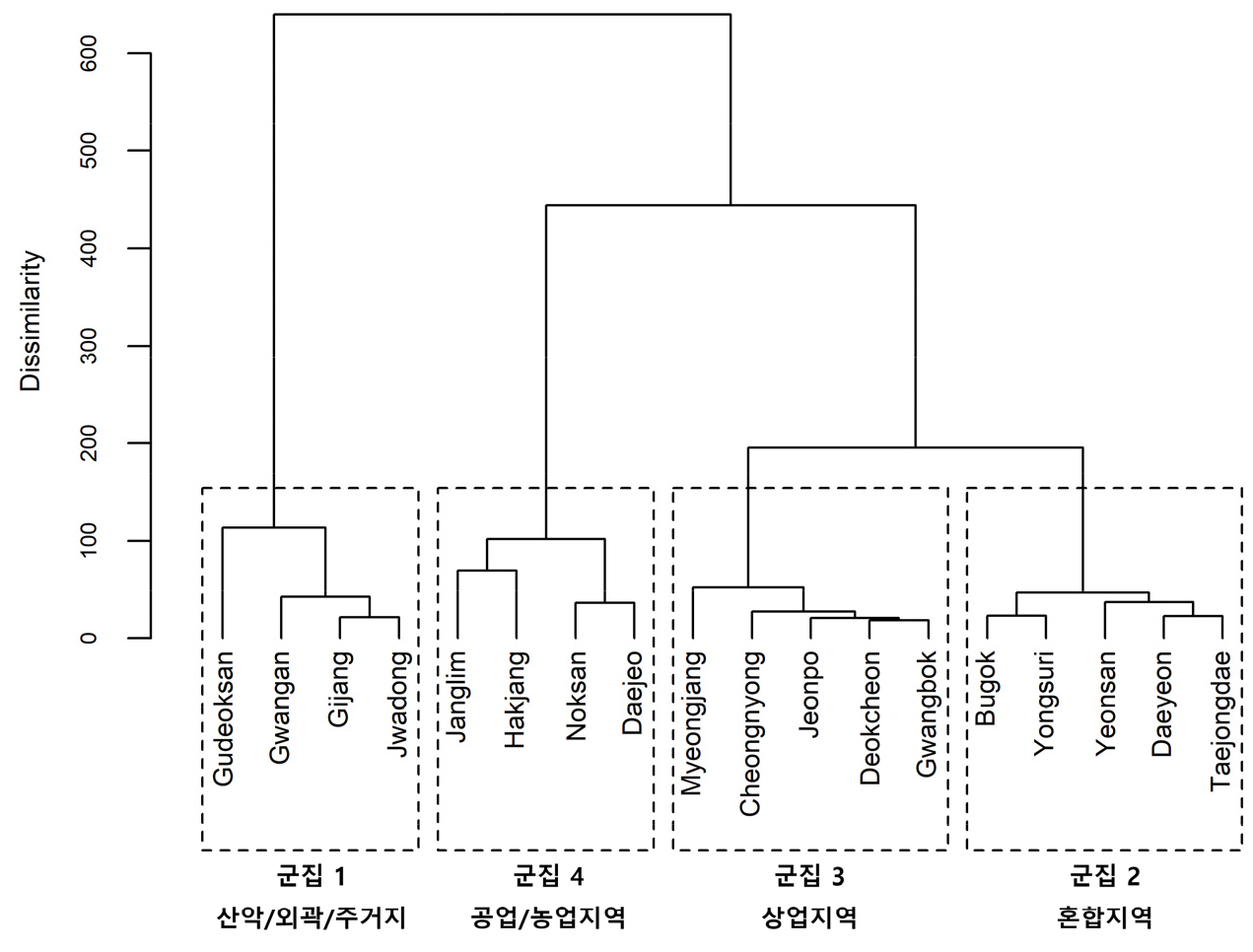
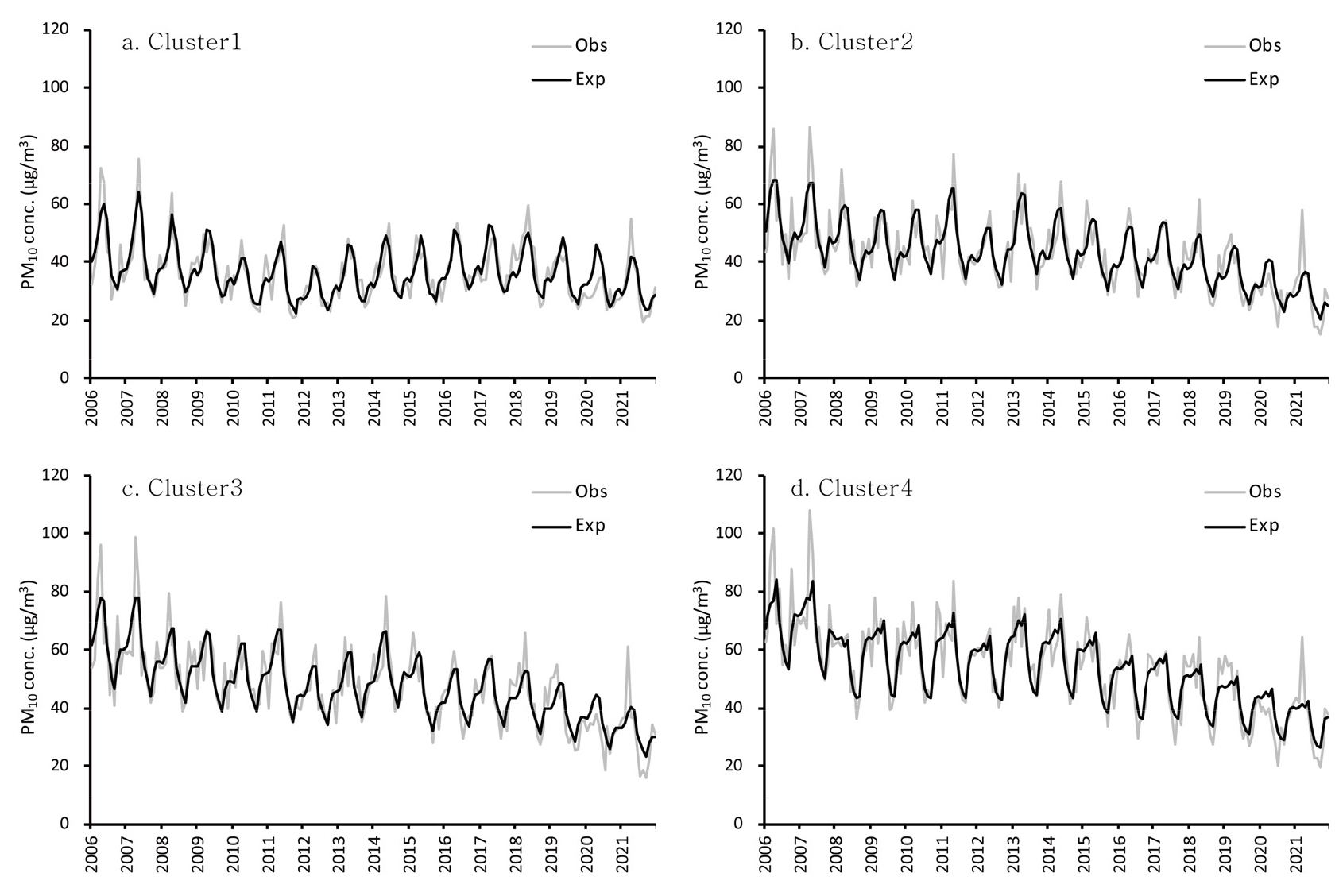
그림 5는 군집별 미세먼지 농도 변화를 나타낸 것인데, 예측 모형을 통해 도출된 결과는 크게 3가지로 요약할 수 있다. 첫째, 평균농도 수준이 가장 낮은 군집1의 시계열 변화 패턴은 연구 기간 중 농도 감소와 상승 경향이 반복되는 양상을 보인 반면, 나머지 군집에서는 전체적으로 농도 감소 경향이 지속되었다. 2006년 43.0㎍m-3로 시작한 평균농도는 2012년까지 감소세를 보이다가 2013년부터 2018년까지 연구 기간 초기 수준까지 증가하였다. 2019년부터는 감소 경향으로 전환되었는데, 코로나바이러스감염증 2019(코로나19)의 확산이 본격적으로 진행된 2020년에는 농도 수준(28.9㎍m-3)이 이례적으로 낮아졌다.9) 둘째, 미세먼지 농도 수준이 높은 군집일수록 미세먼지 농도의 시계열적 감소 경향은 점차 강하게 나타났다. 이러한 결과는, 연구 기간 초기에 비해 후기로 오면서 농도 감소 경향이 상대적으로 뚜렷하게 나타난다는 조사 결과로 미루어 볼 때, 최근에 들어 미세먼지 농도 수준이 높은 지역의 대기질 개선이 상대적으로 빠르게 일어나고 있는 것으로 판단된다. 셋째, 미세먼지 농도가 일시적으로 상승하는 황사일을 제외한 자료를 적용한 경우에도 미세먼지 농도의 군집별 시계열 변화는 큰 차이 없이 유사한 결과를 보여주었다. 대기 중 미세먼지 농도의 관측값과 예측값 곡선을 비교한 그림 6을 자세히 보면, 황사일을 포함한 고농도 발생시점을 중심으로 예측값은 관측값과 비교할 때 대체로 과소추정하는 경향을 나타냈는데, 코로나19의 직접적 영향이 반영된 2020년에는 예측값 곡선에 비해 실제 미세먼지 농도는 이례적으로 낮게 관측되었다.
2. Prophet 모형의 예측 성능 평가
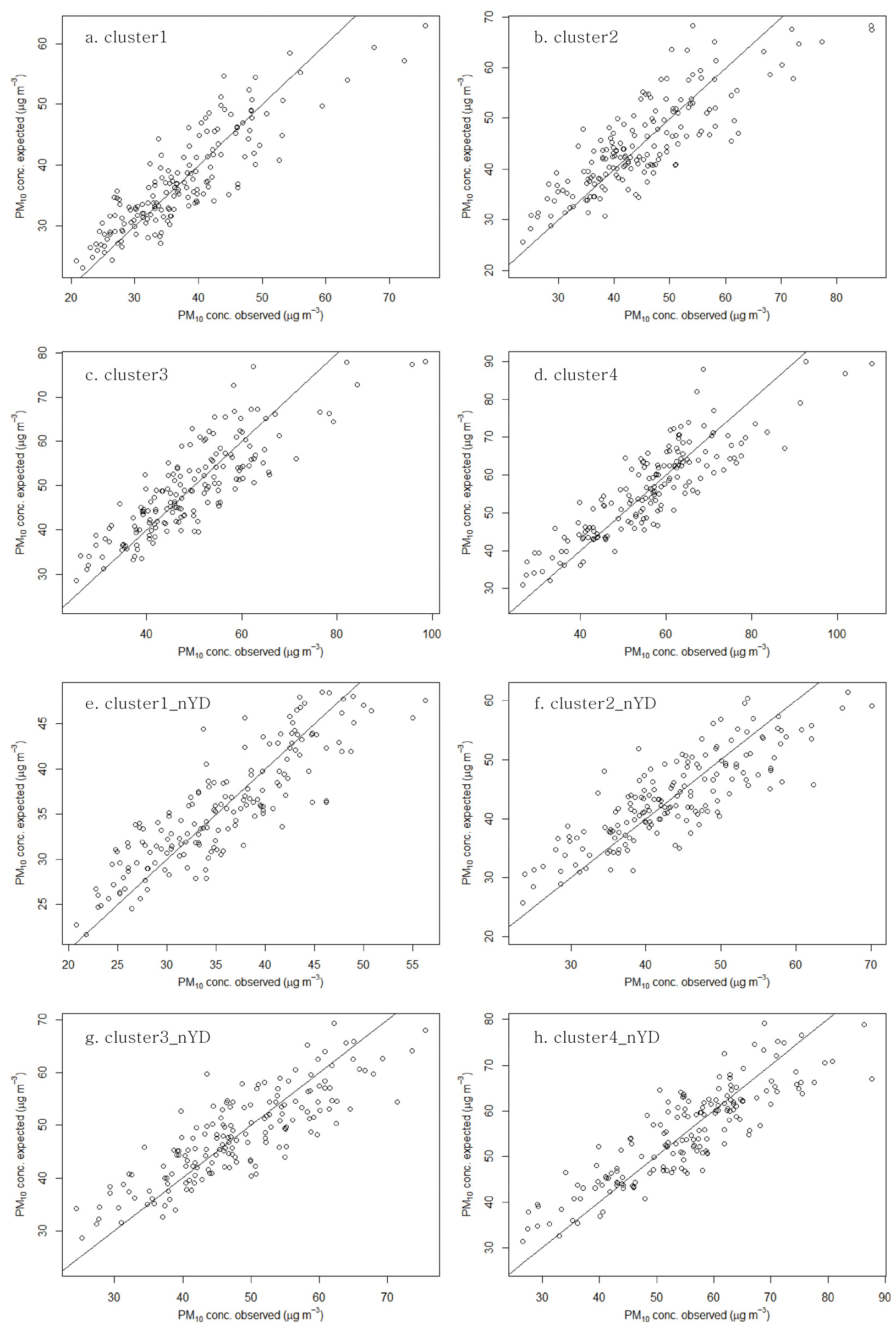
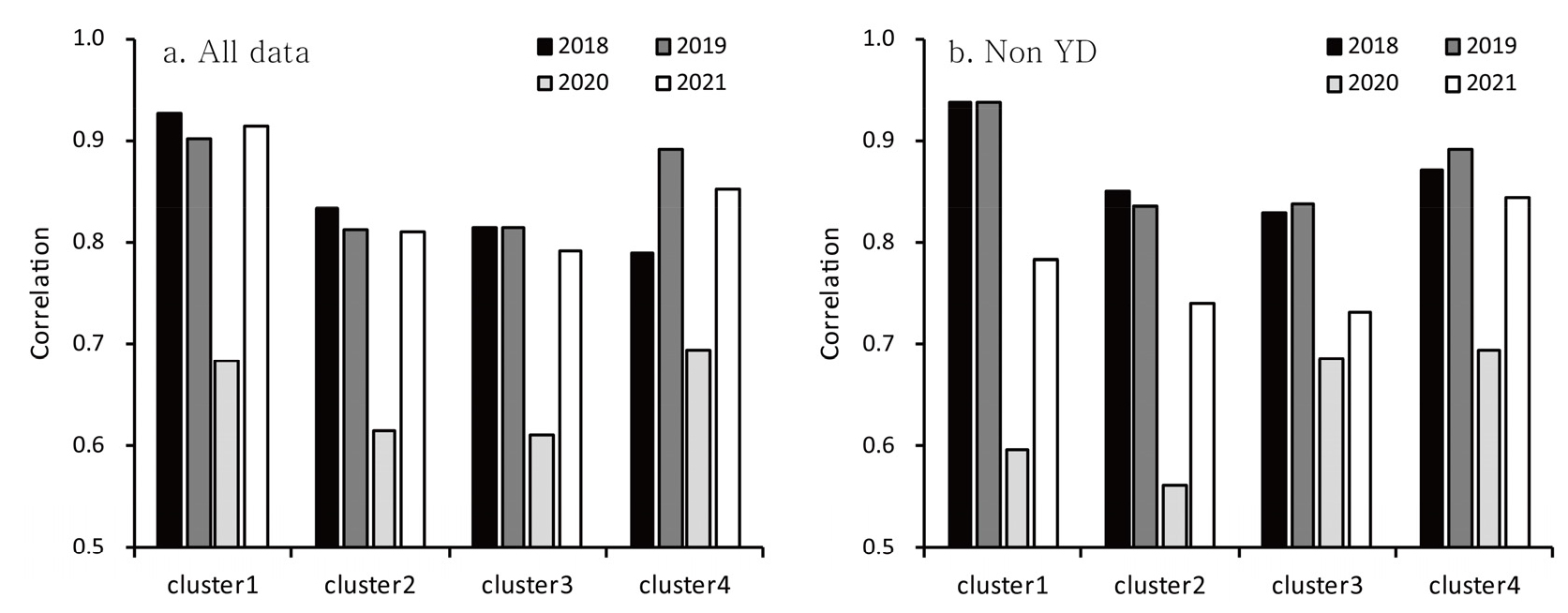
연구 기간 전체에 걸쳐 산출된 Prophet 모형의 예측값과 관측값 간 Pearson 상관계수는 군집별로 0.853~0.885 범위로 조사되었다. 그러나 연도별로 구분하여 산출한 상관계수는 시계열적으로 변동 폭이 적지 않게 나타났다. 코로나19의 영향이 있었던 2020년을 제외한 상관계수 범위를 군집별로 살펴보면, 군집1은 0.687~0.936, 군집2는 0.669~0.890, 군집3은 0.637~0.865, 군집4는 0.533~0.913으로 각각 나타났다. 상대적으로 관측값에 대한 예측값의 부합도가 떨어지는 시기는 군집별로 상이하게 나타났을 뿐만 아니라(군집1-2017년, 군집2-2009년, 군집3-2013년, 군집4-2006년), 관측값과 예측값 간 상관계수의 시계열적인 변화도 군집 간에 밀접한 연관성을 보이지 않은 것으로 보아, 대기 중 미세먼지 농도의 변화 경향과 주기적 특성은 군집 간에 차별성을 보이는 것으로 판단된다. 군집별 평균 상관계수를 비교한 결과, 미세먼지 농도 수준이 가장 낮거나 높은 군집1(전체 모형, r=0.849; 비황사일 모형, r=0.831)과 군집4(전체 모형, r=0.805; 비황사일 모형, r=0.809)의 예측 정확도가 다른 두 군집(0.764~0.782)에 비해 높게 분석되었다. 이는, 군집을 구성하는 관측지점의 등질성이 상대적으로 높은 군집1과 4에서 예측 모형의 성능이 보다 양호하게 반영된 결과로 사료된다. 비황사일을 통한 예측값 결과는 원 자료 기반의 예측값과 거의 흡사한 결과를 보여주었다. 두 예측 시계열 간의 군집별 Pearson 상관계수는 0.965~0.984 범위로 매우 높게 조사되었다.
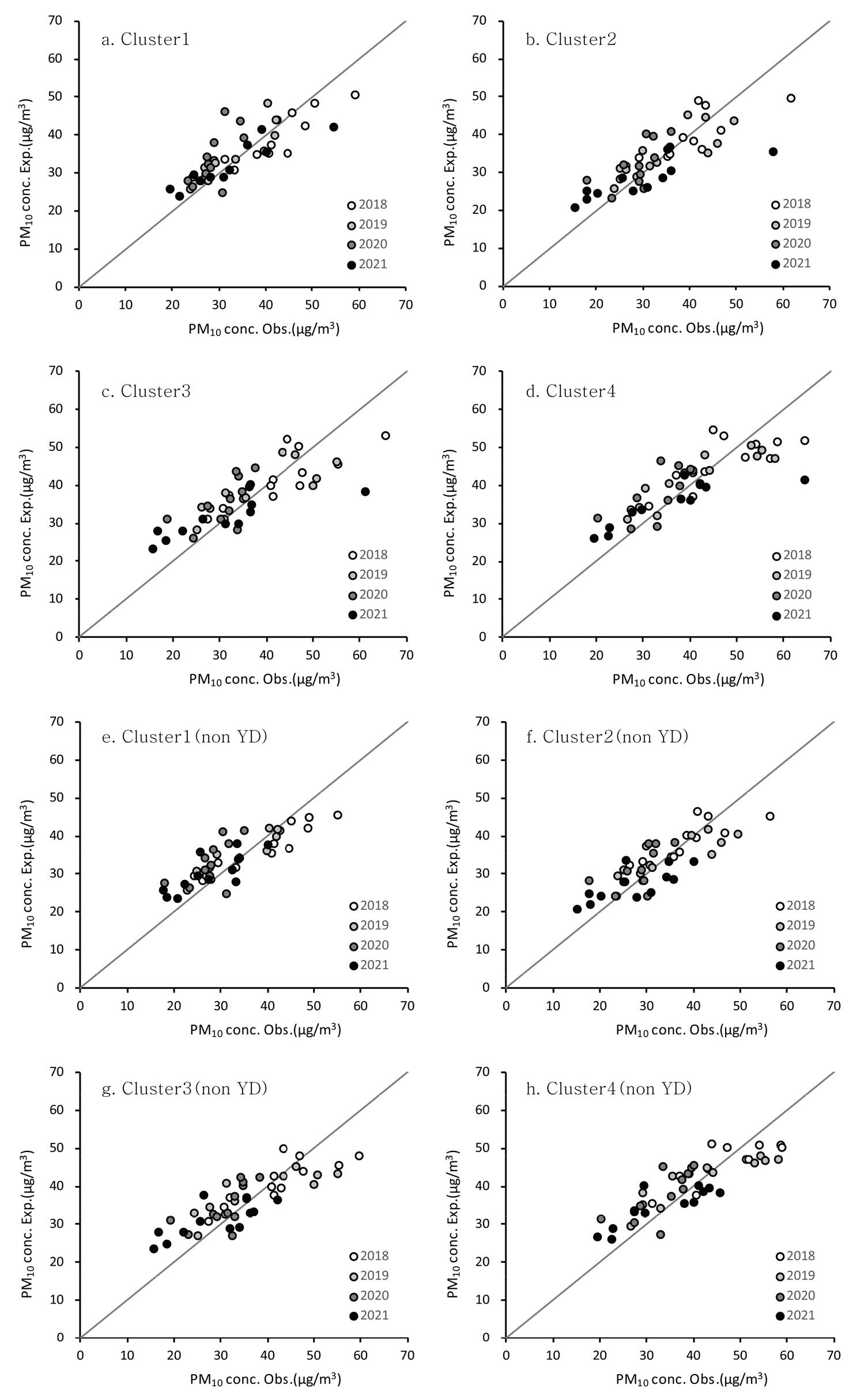
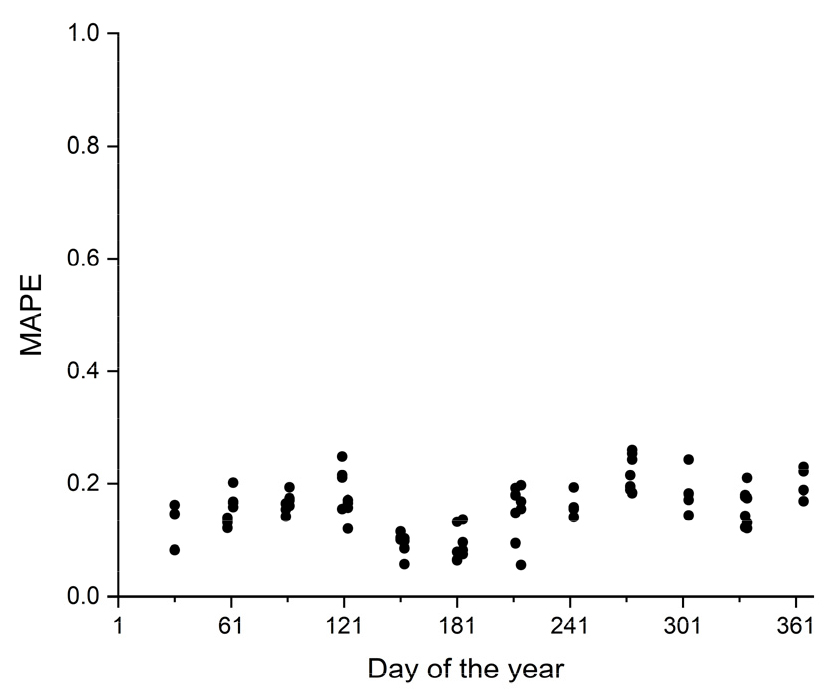
그림 7은 Prophet 모형의 예측 결과를 관측값과 비교한 그래프이다. 전체 자료가 사용된 예측 모형과 비황사일 기반의 예측 모형은 서로 유사한 적합도를 보여주었다. 특히, 대기 중 미세먼지 농도가 현저하게 높거나 낮은 구간에 대하여 두 모형은 유사한 적합도 결과를 보였는데, 농도가 낮은 구간에 대해서는 과대 추정을, 농도가 높은 구간에 대해서는 과소 추정하는 경향을 나타냈다. 다만, 전체 자료 모형은 비황사일 모형에 비하여 예측값 범위가 농도 증가에 따라 1:1 기준선에서 점차 확대되는 양상을 보였다. 군집별 적합도를 보다 구체적으로 분석하기 위하여 최근 4년(2018~2021년)간의 예측 결과를 그림 8을 통해 살펴보았다. 전체적으로, 군집별 예측값의 적합도는 큰 차이를 보이지 않았지만, 대기 중 미세먼지 농도가 낮은 구간에 대해서는 모형의 과대 추정 경향이, 농도가 높은 구간에 대해서는 과소 추정되는 경향이 뚜렷이 나타났다. 특히, 코로나19 확산의 영향이 직접적으로 나타난 2020년과 2021년에 대해서는 그래프 좌하단 중심으로 과대 추정된 모형 결과가 명확하게 반영되었다. 결과적으로, 해당 연도에 대해 산출된 관측값과 예측값 간 상관도는 현저하게 낮게 도출되었다(그림 9). Prophet 모형의 타당성 검토를 위해 산출한 평균절대비오차(MAPE)를 1년 범위의 시간 순서로 분석한 결과, 시계열에 따른 예측 성능의 저하는 발생하지 않았다(그림 10).
3. Prophet 모형 매개변수(parameter)의 영향
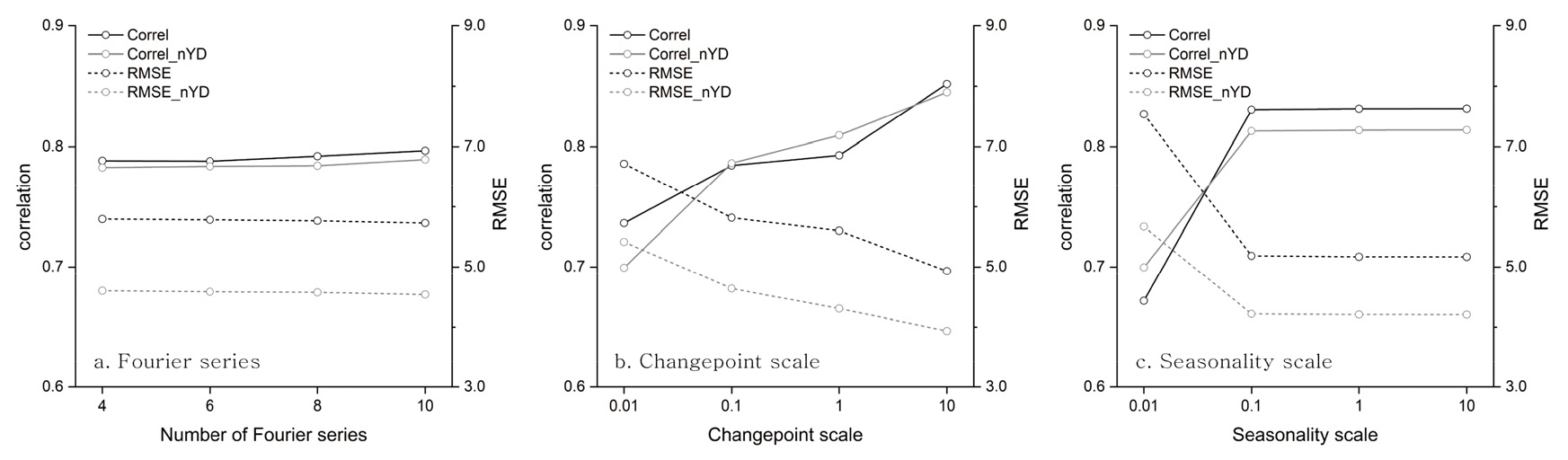
Prophet 모형에서 seasonality 매개변수는 시계열적으로 반복되는 주기 또는 사이클, 즉 24시간 주기로 반복되는 일 주기, 일주일 단위로 반복되는 주간 주기, 1년을 단위로 반복되는 계절 주기 등을 일컫는다. 이러한 주기성의 크기나 규모(magnitude)는 시간의 흐름에 따라 일정하게 유지되거나 변동된다. 연구 기간 중 미세먼지 월평균농도의 연간 표준편차는 2006년 15.42㎍m-3 수준에서 꾸준히 감소하여 코로나19의 영향으로 대기질 개선이 이루어진 2020년에는 4.67㎍m-3까지 급감하였다(2006년 대비 69.7% 감소). 따라서 본 연구에서는 주기성 크기가 일정하게 유지되는 경우에 적합한 가법 모형(additive model)보다는 시계열적인 주기성 변동을 반영한 농도 추정이 보다 적합하다고 판단하여 승법 모형(multiplicative model)을 적용하였다. 나머지 3가지의 매개변수를 군집별로 적용한 결과를 표 2에 제시하였다. 푸리에 급수를 4부터 10까지 조정하여 연구기간 중 전체 추세와 연중 변화 곡선을 각 인자별로 산출한 결과, 푸리에 급수 조정을 통한 계절적 적합도 측면에서 모형의 성능 개선은 크게 이루어지지 않았다. 평균제곱근오차(RMSE) 역시 푸리에 급수 조정에 따른 모형의 개선 효과는 미미했음을 보여주었다(그림 11, 그림 12a).
변곡점 또는 변환점(change point)은 예측 추세선의 기울기가 급변하는 시점을 의미한다. Prophet 모형은 입력 자료의 초기 80%에 해당하는 기간에 대하여 잠재적인 변곡점을 일정 간격으로 설정하고 분석자의 매개변수 조정을 통해 모형의 적합도를 개선 가능하게 한다. Prophet 모형에서는 seasonality_prior_scale() 함수를 통해 이를 조정하며, 통상적으로 적용되는 값은 0.001~0.5 범위로 알려져 있다. 변곡점 매개변수값이 증가할수록 Prophet 모형은 추세 변화에 대한 유연성(flexibility)을 보다 더 허용하며, 감소할수록 그 유연성은 떨어진다(Rafferty, 2021). 분석 결과, 변곡점 매개변수 증가에 따라 모형의 적합도는 지속적으로 증가하는 것으로 나타났다(표 2, 그림 12b). 군집별로 변곡점 매개변수 조정에 따른 관측값-예측값 간 상관계수 개선은 8.2~15.7% 범위로, RMSE 개선은 -12.7~-26.6% 범위에서 이루어진 것으로 각각 조사되었다.
연간 발생하는 미세먼지 농도의 계절적 등락 현상에 대해 Prophet 모형이 적합도를 개선하기 위해서는 주기성 매개변수 조정을 통해 계절적 변화의 크기를 설정하는 과정을 거치게 된다. 이러한 계절적 주기성 조정은 seasonality_prior_scale() 함수를 통해 수행된다. Prophet 모형이 초기값으로 설정하는 주기성 매개변수값은 10이며, 변곡점 매개변수에 적용되는 것과 같이 수치 증가에 따라 주기성의 유연성은 확대되고, 반대로 그 값이 작아질수록 주기성 적합의 유연성은 제한된다. 분석에 적용된 매개변수값은 0.01~10 범위에서 조정되었는데, 0.01에서 0.1로 증가하면서 관측값-예측값 간 상관계수 개선은 군집별로 17.8~26.9%, RMSE의 개선은 -23.0~-31.2% 범위에서 이루어진 것으로 조사되었다. 하지만 그 이후로는 변수값의 증가에 따른 모형의 적합도 개선은 매우 미미하게(0.5% 미만) 나타났다(표 2, 그림 12c). 또, 매개변수의 종류에 상관없이 비황사일 자료를 통한 모형은 전체 자료에 기반한 모형에 비해 군집별 RMSE가 11.3~24.8% 작게 조사되었다.
표 2.
푸리에 급수, 변곡점 척도, 계절성 척도별 관측치-예측치 간 Pearson 상관계수 및 RMSE 비교
V. 요약 및 결론
Facebook Prophet 모형은 다양한 사회경제적 현상뿐만 아니라 일정한 주기로 반복되는 자연 현상에 대한 방대한 시계열 자료를 대상으로 비교적 직관적인 매개변수 조정을 통해 예측값을 도출하는 효용성과 편의성을 갖춘 도구이다. 특히, 장기 시계열 자료의 경우, 누락치나 이례치가 존재해도 별도의 자료 처리 과정 없이 분석이 가능할 뿐만 아니라 각종 현상의 시계열적 특징에 직접적인 영향을 주는 이벤트의 역할을 비교적 쉽게 반영할 수 있는 장점도 있다. 대기 중 미세먼지 농도 변화는 주기성을 나타내는 전형적인 현상일 뿐만 아니라 다양한 시간 단위에서 국지적인 특징을 고려하여 그 변화상을 시의적절하게 추정하고 예측할 필요가 있다. 부산광역시 전체로 보면, 대기 중 미세먼지 평균농도는 점차 낮아지고 있어 대기질 관리 측면에서 긍정적 신호를 보이고 있다. 하지만, 국지적으로 볼 때, 미세먼지 농도의 시계열적 변화 패턴은 공간적으로 동질적이지 않다. 관측지점 주변의 토지이용 특성과 미세먼지 농도 수준에 따라 부산광역시 대기질 관측지점을 모두 4개 군집으로 구분하여 Prophet 모형에 기반한 예측 분석을 수행한 결과는 다음과 같다:
첫째, 최근 16년 동안 전반적인 미세먼지 평균농도의 감소 경향에 따라 계절적 농도 변화 폭이 작아지고 있어서, 장기 자료의 Prophet 예측 모형은 가법 모형보다는 승법 모형을 적용하는 것이 보다 적절한 것으로 나타났다. 군집별 분석 결과, 토지이용 특성이 상대적으로 등질적인 군집1과 4에서의 모형 적합도가 거주지, 상업, 혼합지역 등으로 구성된 군집2와 3에 비해 높게 나타났다. 또, 미세먼지 평균농도 수준이 가장 낮은 군집1은 나머지 3개 군집과 달리 연구기간 중 미세먼지 농도의 상승과 하강 추이를 모두 나타냈다.
둘째, 4개 군집 전체에 걸쳐, 미세먼지 농도 수준이 낮은 구간에서는 모형의 과대추정이, 반대로 농도 수준이 높은 구간에서는 과소 추정이 발생되었다. 특히, 코로나19 확산 이전과 이후 시기를 비교한 결과, 2018~2019년에 비해 코로나19 확산의 직접적 영향이 나타난 2020~2021년에 대하여 Prophet 모형은 현저하게 과대 추정하였다. 결과적으로 관측값과 예측값 간 상관계수는 예년에 비해 현격하게 낮아져, 대기질에 미치는 감염병 확산의 영향이 뚜렷하게 확인되었다.
셋째, Prophet 모형의 주기성 분석에 사용되는 푸리에 급수가 높게 설정될 경우, 모형의 과대적합이 발생한 반면 모형의 적합도 개선은 이루어지지 않았다. 즉, Prophet 모형의 푸리에 급수 매개변수값이 6에서 10까지 상향 조정되더라도 관측값과 예측값 간 상관계수의 개선은 미미하게 나타났다. 따라서 미세먼지 농도의 연간 주기성은 상위 4개 주요 파형의 합으로 대부분 설명되는 것으로 판단된다.
넷째, 미세먼지 농도 변화에 있어서 변곡점 조정은 Prophet 모형이 유연성을 발휘할 수 있도록 높게 설정하는 것이 적절한 것으로 나타났다. 분석 결과, Prophet 모형에서 통상적으로 적용되는 변곡점 매개변수 범위(0.001~0.5)에 비해 모형의 변곡점 탐지가 유연하게 이루어지도록 보다 높게 설정할수록 예측 모형의 적합도는 증가하였다.
다섯째, 연중 발생하는 계절적 변동의 크기 조정, 즉 주기성 매개변수 조정은 제한된 범위에서 의미를 갖는 것으로 조사되었다. Prophet 모형이 초기값으로 설정하는 주기성 매개변수값은 10인데, 분석 결과 0.1보다 더 커지는 경우에는 관측값-예측값 간 상관계수의 개선이나 평균제곱근오차의 개선이 거의 나타나지 않았다.
본 연구는 월평균농도 자료를 기초로 예측 모형의 성능을 평가하였는데, 연도별로 코로나19 확산의 영향, 미세먼지 농도 수준별 영향, 황사일과 같은 이례적 농도값의 영향 등이 모두 모형의 적합도에 영향을 주는 것으로 평가되었다. 이러한 시계열적인 변화 요인들은 일별 수준에서 세부적으로 분석할 경우, 보다 구체적이고 정교한 적합 결과를 도출하는 데에 도움을 줄 것으로 판단된다. 즉, 시간대별, 요일별 주기성뿐만 아니라 주말, 휴일, 연휴 및 특수 이벤트 효과를 모형 속에 통합하여 시공간적인 변동성에 대한 유연한 대응을 필요로 하는 환경에 적용할 수 있다는 측면에서 앞으로 Prophet 모형의 활용 잠재력이 높다고 할 수 있다.
