I. 서론
1. 연구 배경 및 목적
2. 연구의 범위 및 방법
II. 선행 연구 검토
III. 연구 분석 방법
1. 데이터 수집 및 구축
2. 분석 프로세스
3. 분석 모델 선정
IV. 분석 결과
V. 결론
I. 서론
1. 연구 배경 및 목적
일하는 부모를 대신하여 영유아를 보호하고 교육하는 어린이집은 20년간 약 2.3배 증가하였지만, 대부분은 공공 영역이 아닌 민간 영역에서 양적으로 확대되어 왔다. 정부가 보육 국가책임제를 표방하면서 보육정책 예산 규모는 크게 늘었지만 정작 부모들은 자녀를 믿고 맡길 수 있는 어린이집이 부족하다고 호소하는 현실이다(김미정·이지선, 2018).
정부에서는 국공립어린이집 입소 불편 및 확충 요구 등 지속적인 제기로 인하여 국정과제(48-3)로 선정하였고, 2022년 국공립어린이집 이용 아동 40%, 2025년 50% 증가를 위한 확충 사업을 진행하고 있다(국정기획자문위원회, 2017). 국공립어린이집 추가 설치 위치는 저소득층 밀집 지역 및 공공 보육의 취약 지역을 우선적으로 설치해야 하며, 모든 영유아를 위한 적절한 어린이집 확보가 필요하다(보건복지부, 2017).
국공립어린이집은 국가 지원 예산이 쓰이기 때문에 비용이 저렴하면서 교육의 질이 높고, 정부의 보육지침에 있어 운영 방법이 명확하다는 장점이 있다. 하지만, 신뢰도가 높은 만큼 부모들에게는 경쟁률도 높아 입학이 어렵다는 단점도 있다. 지역적 보육수요 및 접근성 등을 고려하여 적절히 공급되고 있는지에 대한 면밀한 검토가 필요하다(김은정, 2014).
현재 국공립어린이집 선정 방법은 행정동별 어린이집 비율로 설치 위치를 지원하고 있으며 (영등포구, 2018), 서울시 동작구, 오산시 등은 빅데이터 분석을 통해 국공립어린이집 사각지대를 도출하여 제공하고 있다.
하지만, 기존 국공립어린이집에 대한 평가가 없고 행정동으로 입지 위치를 도출하는 범위, 단위에서의 한계점을 보이고 있기 때문에 본 연구에서는 1차 역세권 거리인 250m 격자 단위로 분석하여 국공립어린이집 평가 및 추가 설치에 대한 위치를 제공하는데 목적이 있다. 아울러 국공립어린이집 설치에 영향을 주는 요인을 파악하고, 격자별 데이터 구축 및 분석 모델을 활용할 수 있는 방법론을 제시하여 공간 빅데이터 연구 분석 사례로서 공공 보육의 사각 지대에 있는 주민에게 지원하고자 한다. 연구 수행을 위해 통계 분석 프로그램인 R과 공간 분석 및 시각화 소프트웨어인 QGIS를 사용하였다.
2. 연구의 범위 및 방법
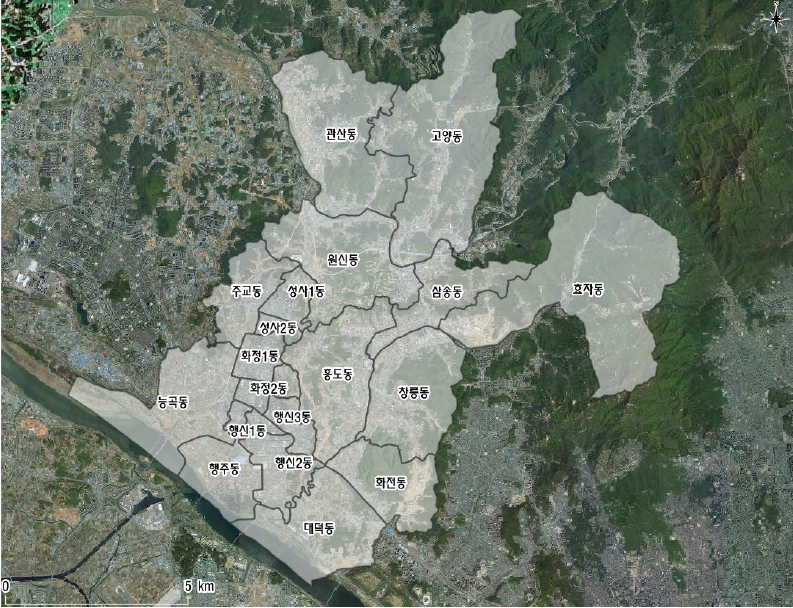
본 연구의 공간적 범위는 경기도 고양시 덕양구로 인구 480,386명, 면적 165,539km²으로 고양시의 61,9% 해당되며, 32개 법정동과 그림 1과 같이 19개의 행정동으로 구분된다. 덕양구는 주거지역, 상업지역, 농촌지역, 녹지지역, 농림지역 등 다양한 용도지역을 가지고 있으며 서울, 경기, 인천 등의 다른 구로 통근, 통학을 하는 비중이 가장 높은 구이다(고양시, 2018).
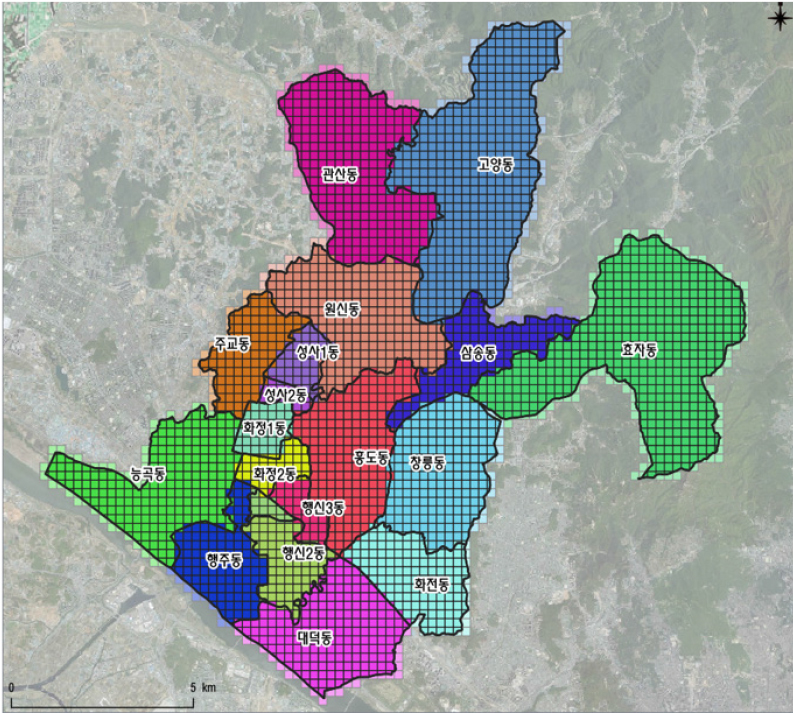
보육의 사각지대에 있는 덕양구 주민에게 집에서 가까운 위치의 국공립어린이집을 지원하고 다른 구, 타 지역에서도 활용이 가능하도록 국공립어린이집 분석 데이터, 프로세스, 활용 모델 등을 제공하고자 한다. 연구에 활용하는 분석 단위는 1차 역세권 거리인 250m 단위이다. 보행 접근이 가능하고 대중교통 이용이 편리한 거리를 말하며, 사각 지대 도출 및 기존 국공립어린이집을 평가하기 위해 덕양구를 격자별로 분석하였다(그림 2).
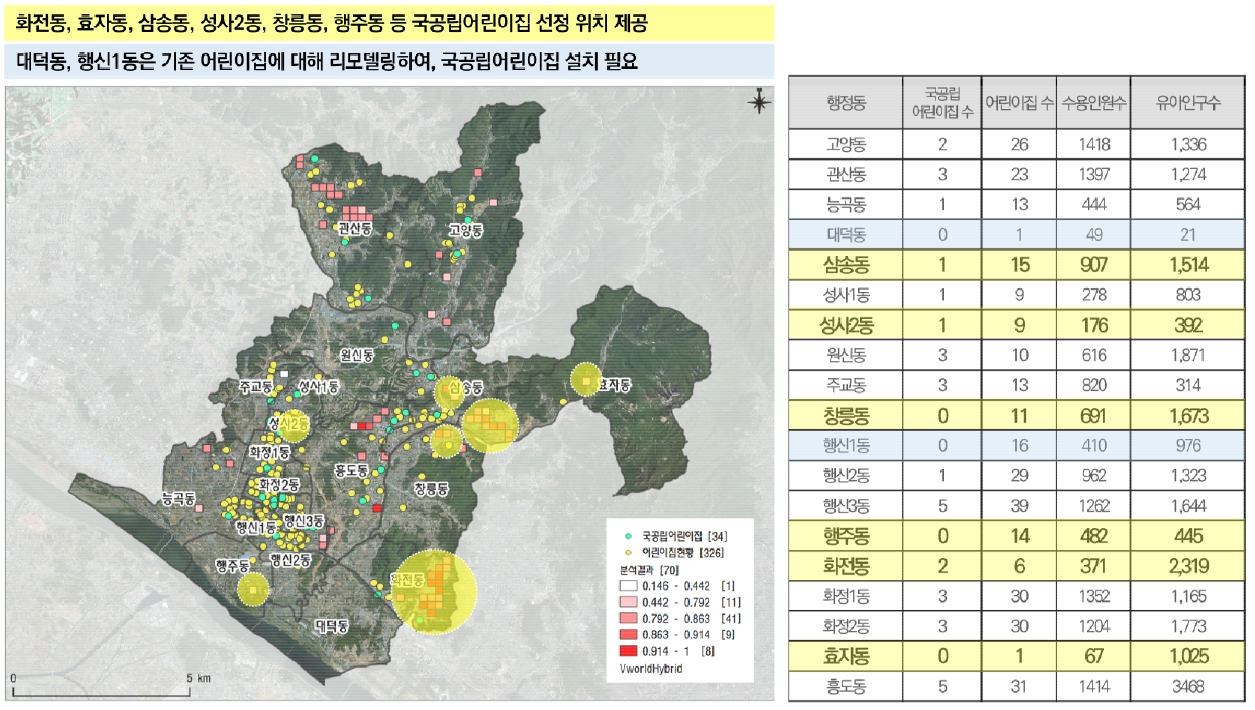
21년도 기준의 경기도 어린이집 데이터를 사용하여, 덕양구 행정동별 국공립어린이집을 현황 분석한 결과이다(그림 3). 덕양구에 설치된 국공립어린이집은 총 34개이며 대덕동, 창릉동, 행신1동, 행주동, 효자동은 0개로 국공립어린이집이 없었다. 행정동별 유아인구 대비 국공립어린이집 수용인원은 봤을 때 효자동, 화전동, 행신1동, 삼송동, 창릉동의 비율이 낮았다.
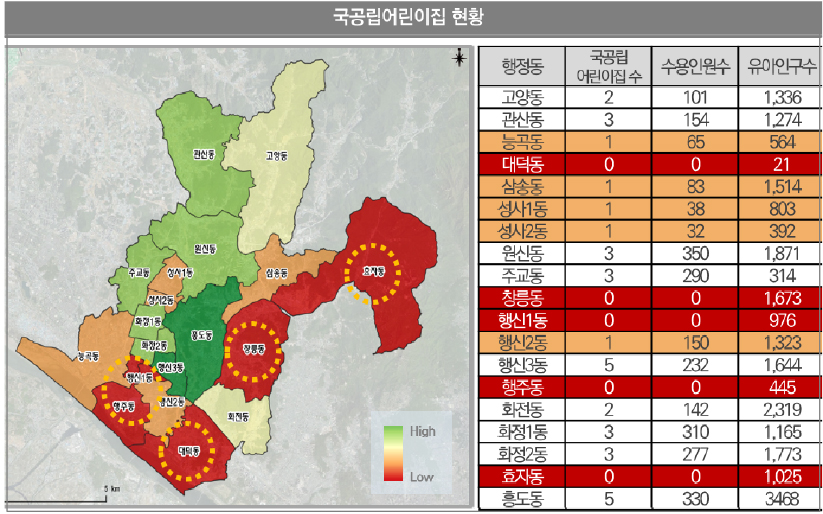
국공립어린이집은 현재의 어린이집을 리모델링하여, 설치할 수 있기 때문에 어린이집 현황을 확인하였다.
전체 어린이집은 총 326개이며 효장동, 대덕동, 화전동, 성사1동, 성사2동은 어린이집 수가 10개 미만이다. 행정동별 유아인구 대비 어린이집 수용인원은 효자동, 화전동의 비율이 낮았다(그림 4).
결과적으로 덕양구 효자동, 화전동 등 해당 지역에 대해 국공립어린이집 설치가 필요하다는 것을 볼 수 있었다. 본 연구에서는 실질적으로 주민에게 지원하기 위해서 격자별로 설치가 필요한 위치를 도출하였다.

II. 선행 연구 검토
선행 연구 사례를 통해 분석에서 활용하기 위한 데이터, 분석 방법, 활용 모델을 파악하였고, 기존 연구의 한계점에 대해서는 개선점을 모색하여 국공립어린이집 분석 과정 및 모델에 적용하였다. 분석 결과는 지도 스타일을 지정하거나, 제작할 수 있는 QGIS를 활용하여 시각화하였다(안재성 등, 2020).
김진영·김영훈(2014) GIS를 활용한 천안시 국공립어린이집 최적지 분석에 관한 연구사례는 어린이집, 유아인구수 데이터를 사용하여 GIS 공간분석기법인 Density-kernel, Clustering를 통해 동별 최적지 분석을 하였다. 하지만, 비지도 학습 분석 방법과 국공립어린이집에 선정 및 평가에 필요한 주요 데이터인 주거지역에서의 거리접근성, 위험시설물 등을 고려 안 했기 때문에 분석 데이터 및 방법에서의 한계점을 보였다.
이제연·박승규(2017) 공간정보를 활용한 주민생활서비스 접근성 연구 사례에서는 도로망을 이용하여 어린이집 생활서비스 데이터를 구축하고 네트워크 분석을 통해 접근성을 파악하였지만, 현실적으로 어린이집 취약지역을 접근성으로만 보기에는 데이터 유효성에서의 한계점을 보였다.
2018년 영등포구 국공립어린이집 40% 확충 사업을 보면 동별 어린이집 비율 및 국공립어린이집 이용률이 적은 지역부터 우선 신축을 통해 공공보육 필요 지역을 중점 추진을 하였으나, 실질적으로 취약 지역에 설치하기에는 행정동이라는 분석 단위에서의 한계점을 보였다.
2018년 용인시 국공립어린이집 분석을 보면 격자별 데이터 구축 및 사각지대를 분석을 통해 취약지역을 도출하였지만, 기존의 설치한 국공립어린이집에 대한 적합성 평가가 없으며, 분석에 사용한 데이터 및 방법론을 확인할 수 없기 때문에 연구 사례로 활용하는 부분에서 어려움이 있다.
김예술 등(2020) 서울 공공자전거 신규 대여소를 위한 수요량 예측 분석은 신규 대여소를 예측하기 위하여 선형 회귀 모형(linear regressionmodel)과 랜덤 포레스트(random forest)를 사용하였다. 선형 회귀 모형은 종속변수와 독립변수 간의 선형성 가정하에 계산이 쉽고 빠르며 결과에 대한 설명이 용이하다는 장점이 있다. 랜덤 포레스트는 종속변수와 독립변수 간의 선형성 가정이 필요하지 않고 변수들의 교호작용(interaction) 역시 설명 가능한 모델이다. 예측력에서 선형 회귀 모형보다 우수한 성능을 보이지만 해석이 어렵다는 단점이 있다. 본 연구에서의 국공립어린이집 추가 선정을 위해 선형, 비선형 모델을 비교하여 분석에 적합한 모델을 선정하였다.
2020년 행정안전부 표준분석모델 돌봄센터 입지분석에서는 상관분석 등 통계적 접근 방법을 통해 주요 요인을 도출하고 정사영상을 통해 격자별 공간 분석 결과를 시각화하였다. 하지만, 기존 센터 위치에 대한 적합성 평가가 없기 때문에 입지 분석에서의 한계점을 보였다.
앞서 선행 연구 사례의 주요 시사점을 적용하여 분석 프로세스를 설계하였다. 먼저 어린이집, 유아인구, 거주인구, 거리접근성 등 국공립어린이집 평가 및 설치에 필요한 데이터를 수집하였고 선형 회귀 분석, 로지스틱회귀분석, 랜덤포레스트 분석 모델로 활용하여 본 연구에 적합한 모델을 비교, 선정하였다.
선행 연구 사례의 한계점에 대해서는 3가지 개선사항을 모색하여, 본 연구 분석에 적용하였다.
1) 법률, 정부정책 및 선행 연구 사례 등을 통해 국공립어린이집 선정에 필요한 주요 데이터를 모두 수집하였다. 어린이집 현황, 인구(총인구, 유아인구, 생산가능인구), 공시지가, 개별주택가격, 위험시설물(공장, 위험물저장및처리시설 등), 건축물수, 국가표준격자, 행정읍면동, 주용도코드(단독주택, 공동주택, 제1종근린문화시설 등), 도로, 지하철역 위치 등을 활용하였다.
2) 국공립어린이집 선정을 위해 행정동별 위치에서 250m 격자별로 데이터 구축 및 분석을 하였다. GIS 공간 분석을 하여 데이터 마트를 구축하고 상관분석, 회귀분석, 머신러닝 모델 등을 활용하여 국공립어린이집에 영향을 주는 변수를 파악하였다.
3) 분석 결과를 직관적으로 보이기 위해 QGIS로 시각화하였다. 영유아보호법의 어린이집 설치 기준에 따라 유아인구수, 주용도명, 지하철, 도로수, 위험물 저장 및 처리시설 50m 이내, 주유소, 천연가스 충전소 등 25m 이내, 수용인원 20명 이하인 경우 단독주택, 공동주택에 설치 기준으로 기존 국공립어린이집을 평가하였고, 국공립어린이집 설치가 필요한 장소에 대해서는 위치 및 속성 테이블을 통해 정보를 볼 수 있도록 도출하였다.
III. 연구 분석 방법
1. 데이터 수집 및 구축
국공립어린이집 연구 분석하는데 필요한 데이터는 총 17개 데이터로 표 1과 같다. 데이터는 법률, 정부정책, 선행연구사례를 토대로 국공립어린이집 위치에 영향을 줄 수 있는 의미 있는 데이터를 수집하였다. 데이터는 보유기관별 웹사이트를 통해서 받을 수 있다.
표 1.
수집 데이터 목록
수집한 데이터를 QGIS 프로그램을 활용하여, 격자별로 매칭하고 분석 데이터 마트를 구축하였다(그림 5).
정확한 분석을 위해 국공립어린이집 위치, 유아인구수, 어린이집 접근성, 위험물 저장 및 처리시설 등 정사영상과 비교하여 데이터 품질을 확인하였다(그림 6).
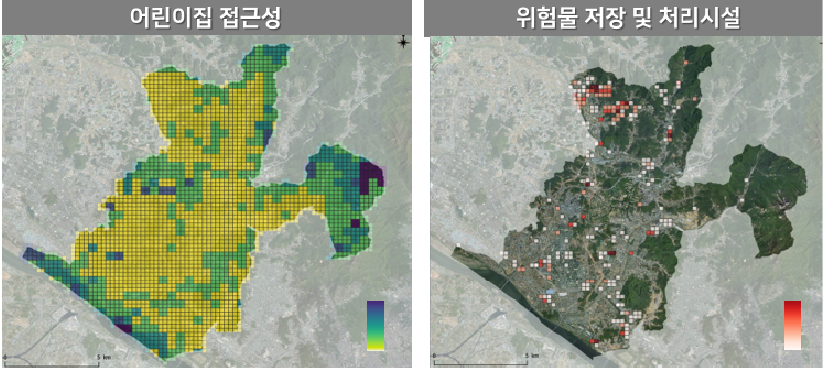
2. 분석 프로세스
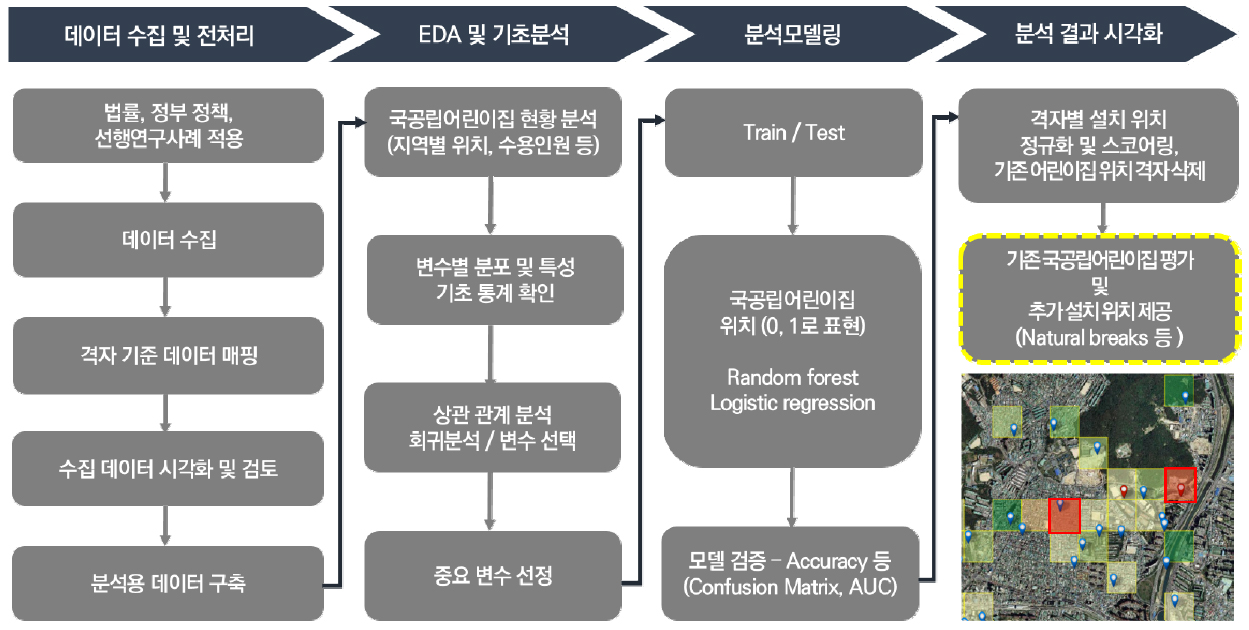
국공립어린이집 위치 평가 및 추가 선정을 위한 분석은 크게 4단계이며 그림 7과 같이 데이터 수집 및 전처리 및 전처리, EDA(Exploratory Data Analysis) 및 기초분석, 분석모델링, 시각화 단계로 진행하였다. 데이터 분석기법과 공간정보 처리기법을 활용하여 처리와 분석이 가능하게 데이터 마트를 구축하였다(구자용, 2015). GIS 공간 분석을 통해 기존 국공립어린이집 위치를 평가하였고, 국공립어린이집 추가 선정에 대해서는 머신러닝인 랜덤포레스트를 활용하여 입지 선정에 대한 모델로 정립하였다.
1)데이터들을 하나의 좌표계인 EPSG:5179로 통일하여 250m 격자에 매칭하였다.
2)국공립어린이집 현황분석, 상관분석, 다중공선성, 회귀분석을 통해 국공립어린이집에 영향을 주는 변수를 도출하였다.
3)국공립어린이집을 종속변수로 활용하고 상관관계, 다중공선성, 회귀분석에서 나온 변수를 독립변수로 사용하여 랜덤포레스트, 로지스틱회귀분석을 통해 분석을 진행하였다. 분석 모델은 Confusion Matrix, AUC(Area Under the Curve) 정확도 비교 검증을 통해 높은 성능의 모델을 선정하였다.
4)위험물 저장 및 처리시설 등 공간 분석을 통해 기존 국공립어린이집을 평가하고, 선정의 영향을 주는 요인 변수를 Value값으로 활용하여 격자별로 점수화하였다. 격자별로 명확하게 분류하기 위해 점수를 Natural Breaks를 하여 5개 등급으로 시각화하였다.
수집한 데이터의 NULL값에 대해서는 분석이 가능하도록 0으로 변경하였다. 국공립어린이집 위치 정보는 주소로 제공하기 때문에 Geo-coding을 통해 경위도 좌표로 추출하고, EPSG:5179 UTMK 좌표로 변환하였다.
분석 단위는 격자 250m 기준으로 속성 결합, 공간 결합을 통해 데이터 마트를 구축하였다. (산, 하천 제외 격자:1,894개, 국공립어린이집격자:197개)
상관분석 및 다중공선성을 통해 분석 모델에 활용하는 데이터를 도출하였다. 상관분석은 일부 예측 변수가 다른 예측 변수와 상관 정도가 높아, 부정적 영향을 미치는 현상 방지하기 위해서 하는 분석으로 총인구, 생산가능인구수, 민간어린이집 등 높은 양의 상관관계인 0.7 이상을 보였다(그림 8).
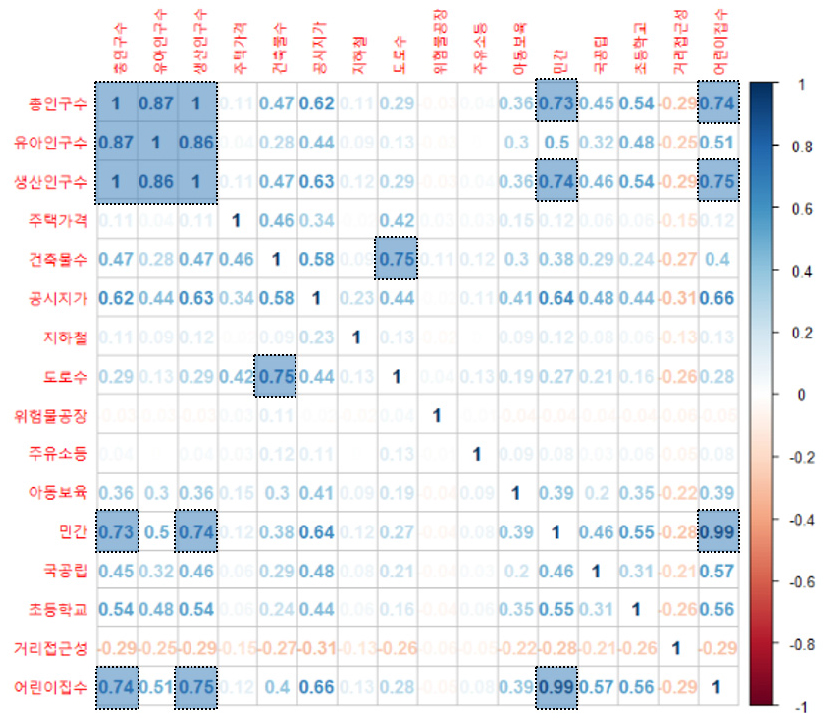
상관 관계가 있는 변수를 제외하기 위해 다중공선성을 통해 VIF 값이 10 이상을 가진 총인구수, 생산인구수, 민간어린이집, 전체어린이집 데이터를 제외하여 분석 모델에 적용하였다(표 2).
표 2.
다중공선성 VIF
분석 모델은 로직스틱 회귀분석(Logistic Regression), 랜덤포레스트(Random Forest)을 활용하였다.
로지스틱 회귀분석은 일반화 선형모형이라 불리는 큰 범주의 통계모형 모델링에 속하는 방법으로 문자 그대로 선형적이지 않은 대상(비선형)을 선형적으로 일반화 시킨모형이다. 종속변수가 범주형 자료일 때는 OLS 회귀모형 대신 로지스틱 회귀모형을 분석에 이용한다. (강현모·이상경, 2019).
랜덤 포레스트는 의사결정나무를 많이 심어 숲을 만든다는 의미로 Forest라고 하며 여기서 Random이 붙은 이유는 숲에 심는 의사결정나무들에 쓰이는 특성들을 랜덤하게 뽑아 만들기 때문에 랜덤포레스트라고 한다. 의사결정나무의 회귀 결과값은 의사결정나무의 회귀 평균으로 얻어진다. 이는 의사결정나무 방식의 약점 중 하나인 과적합 가능성을 해소하면서도, 더 복잡한 속성 구조를 안정적으로 탐색할 수 있는 기법이다(홍정의, 2021).
랜덤 포레스트 알고리즘은 의사결정 나무 중 CART (classification and regression tree)와 앙상블 기법(ensemble learning) 중 배깅(bagging) 알고리즘을 조합한 것으로, Breiman에 의해 2001년 제안되었다. CART 알고리즘을 채택하였기 때문에 데이터의 유형과 분포의 제약 없이 사용 가능하며, 과대 적합의 위험이 낮기 때문에 다수의 머신러닝 연구에서 채택되고 있다(이인지·유현식, 2020).
3. 분석 모델 선정
로직스틱 회귀분석과 랜덤포레스트 모델 검증 결과를 비교하여 분석에 적합한 모델을 선정하였다.
AUC 검증은 ROC Curve의 아래 면적이 클수록, 면적의 값을 나타내는 AUC 값이 1에 가까울수록 모델의 성능이 좋다는 것을 말한다(그림 9). 혼동행렬인 Confusion Matrix 값도 1에 가까울수록 정확도가 높다는 것을 의미한다.
모델 성능, 정확도가 우수한 랜덤포레스트(Random Forest)를 선정하여 분석 모델에 적용하였다(그림 10).
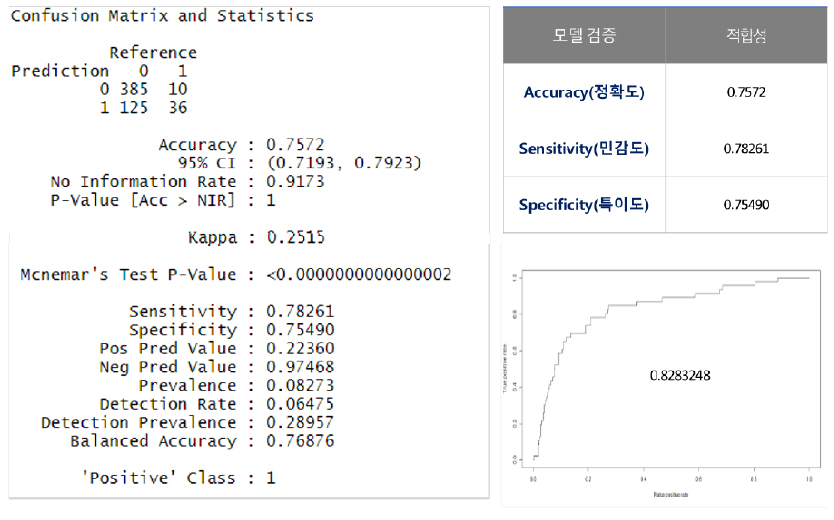
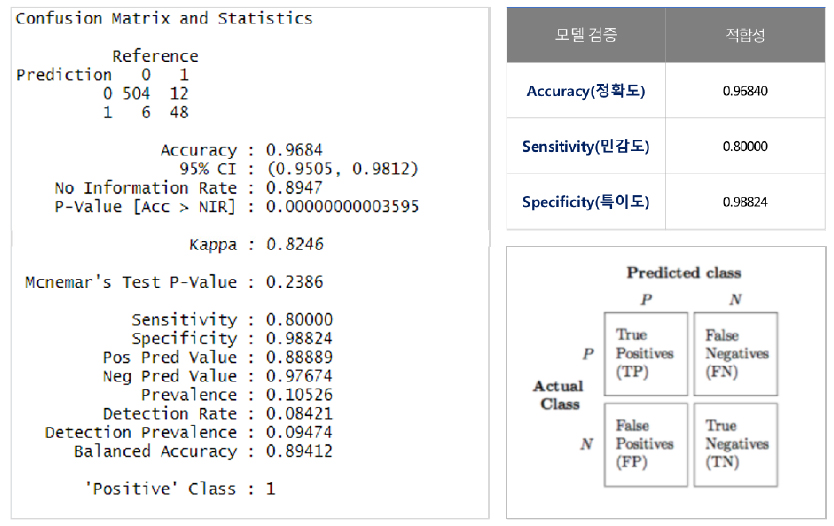
- AUC, Confusion Matrix 모델 검증 결과(표 3).
- 정확도 Positive(1), Negative(0) 바르게 분류한 비율.
- 민감도 Positive(1)라 분류한 것 중 실제값이 Positive (1)인 비율.
- 특이도 Negative(0)라 분류한 것 중 실제값이 Negative (0)인 비율.
- Random Forest F1 Score (0.8421053).
표 3.
로지스틱 회귀분석, 랜덤포레스트 비교
| 검증 | 로지스틱 회귀분석 | 랜덤포레스트 | |
| AUC(모델 성능, 정확도) | 0.8283 | 0.8941 | |
|
Confusion Matrix | 정확도 | 0.7572 | 0.9684 |
| 민감도 | 0.7826 | 0.8000 | |
| 특이도 | 0.7549 | 0.9882 | |
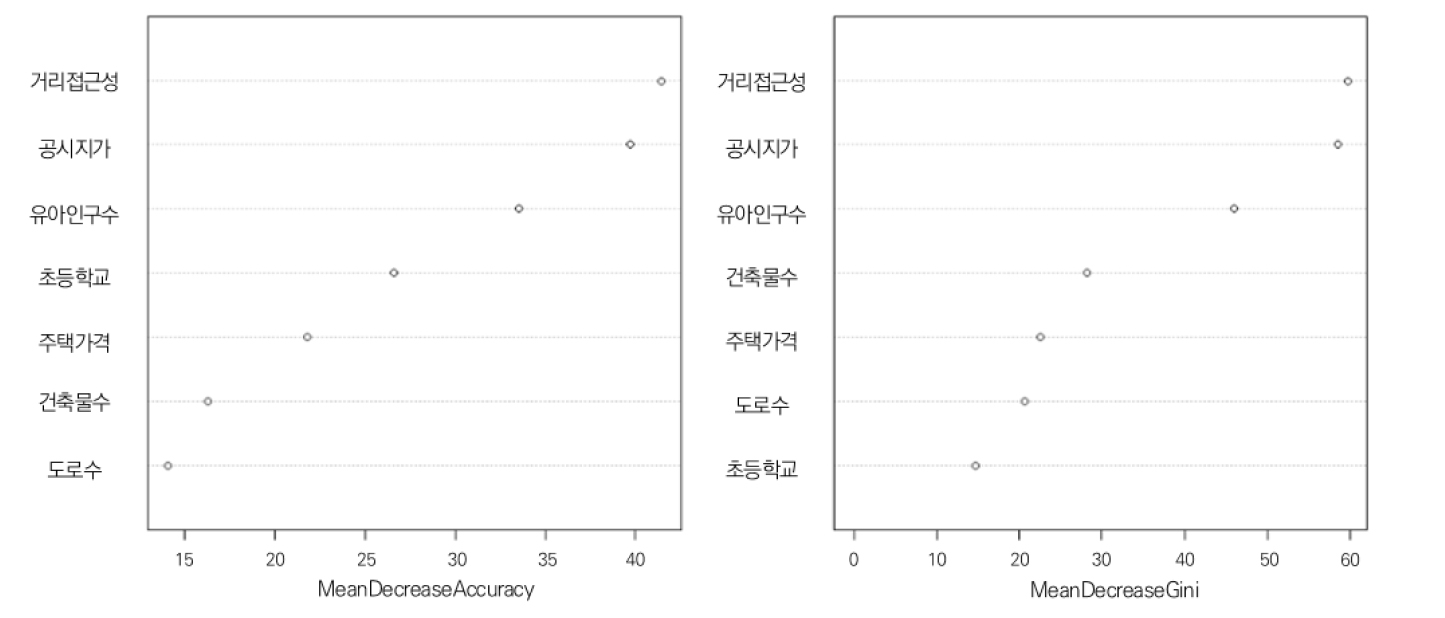
국공립어린이집에 대한 독립변수들의 중요도를 나타내는 MeanDecreaseAccuracy(정확도 개선의 중요변수), MeanDecreaseGini(노드 불순도 개선의 중요변수)는 Random Forest에서 가지를 칠때 얼마나 정확도가 올라가는지를 나타내는 지표이다(그림 11).
국공립어린이집 종속변수(1:있다, 0:없다)에 대한 MeanDecreaseGini 중요변수는 거리접근성(59.63), 공시지가(58.44), 유아인구수(45.92), 건축물수(28.12), 개별주택가격(22.51), 도로수(20.72), 초등학교(14.68)이다.
중요변수의 가중치를 활용하여 격자별로 점수화하고, 정규화 및 NaturalBreaks를 통해 국공립어린이집 설치가 필요한 위치를 시각화 하였다.
IV. 분석 결과
국공립어린이집 위치 평가 및 추가 선정이 필요한 지역에 대한 결과는 QGIS 프로그램을 통해 확인하였다. 국공립어린이집 위치 평가는 영유아보호법의 어린이집 설치 기준에 따라 유아인구수, 주용도명, 지하철, 도로수, 위험물 저장 및 처리시설 50m 이내, 주유소, 천연가스 충전소 등 25m 이내, 수용인원 20명 이하인 경우 단독주택, 공동주택에 설치 기준으로 평가하였다.
평가 결과 시립화전어린이집, 시립원당어린이집, 시립꽃우물어린이집, 시립화정어린이집 주변에는 위험물 저장 및 처리시설이 있는 것으로 도출되었다(그림 12).
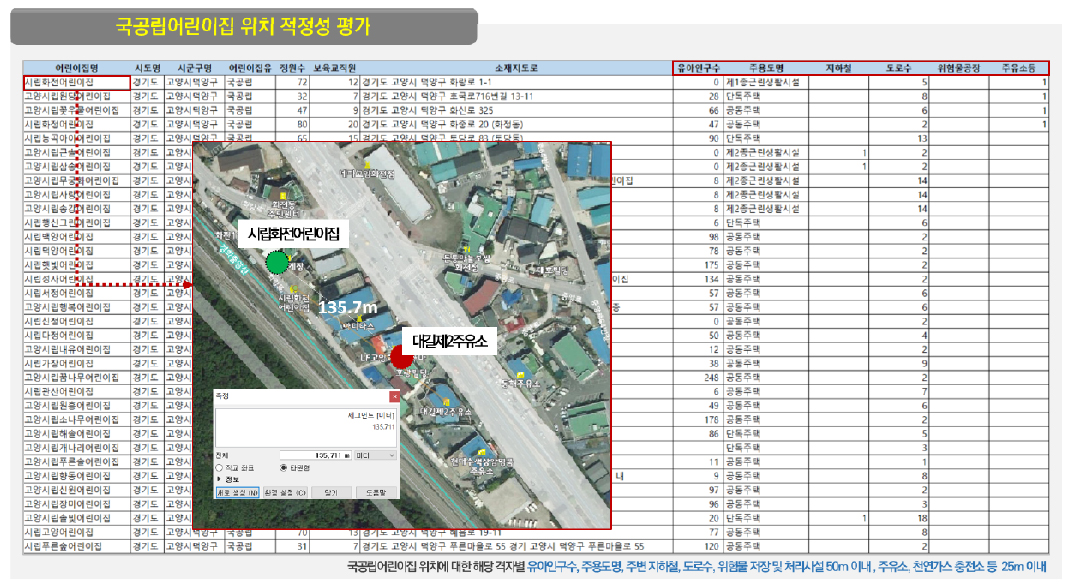
평가 결과는 QGIS의 속성정보 테이블로 볼 수 있으며, 위험 지역 등 도출한 국공립어린이집에 한하여 현장 조사를 통해 확인이 필요하다.
국공립어린이집 추가 선정 위치는 국공립어린이집 설치에 영향을 주는 중요 변수를 사용하여 격자별(250m* 250m) 점수로 표현하였다. 유아인구가 1명이라도 없는 격자는 제외하였으며, NaturalBreaks 등급 내의 분산은 최소화하고 등급간의 분산은 최대화하는 알고리즘를 통해 5등급으로 분류하여 시각화하였다.
국공립어린이집 추가 선정 위치는 격자 70곳으로 도출되었다(그림 13).
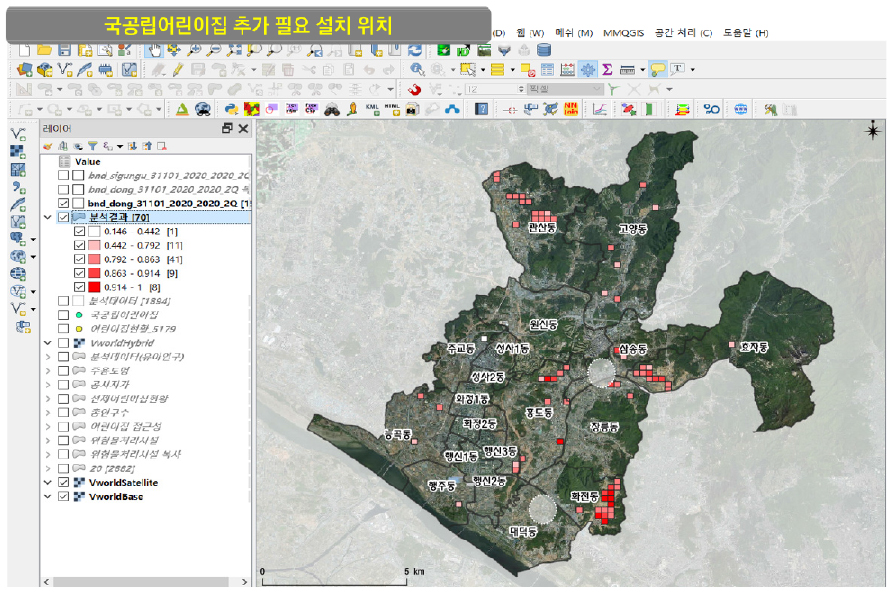
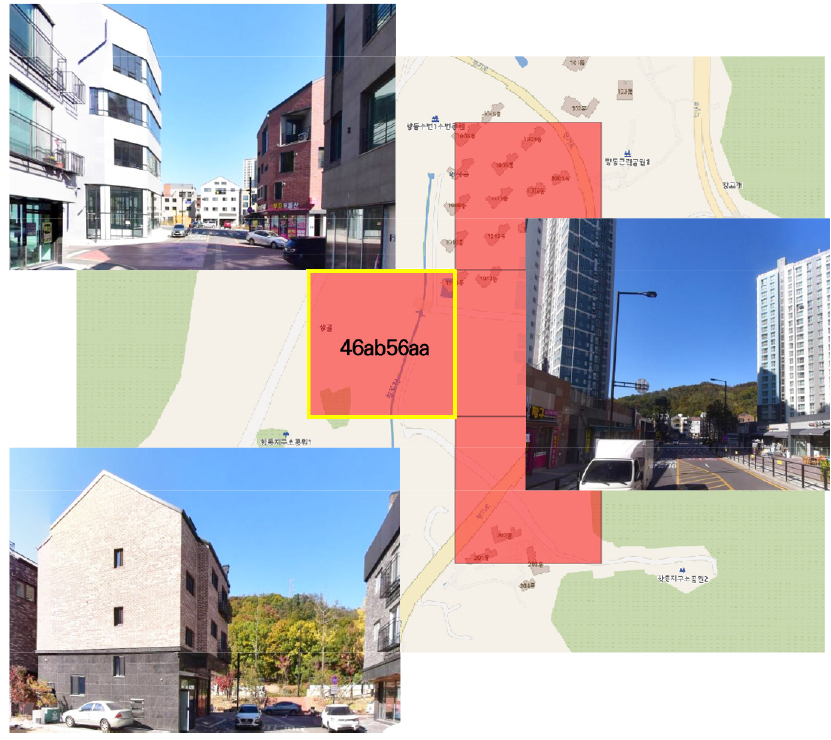
도출된 정보는 속성정보 테이블을 열어서 설치가 필요한 곳의 격자 번호(gid), 행정동의 위치 정보를 볼 수 있다. 분석 결과를 검증하기 위해서 정사영상을 통해 점수가 높은 0.8이상의 2곳을 확인하였다(그림 14).

효자동의 48aa61ba, 화전동의 45ab55ba 격자를 확인한 결과, 해당 위치는 유아인구가 있는 공동, 단독주택 지역이며 기존 국공립어린이집 및 전체 어린이집 대한 접근성이 멀어 실질적으로 보육의 취약지역으로 볼 수 있었다. 향후 해당 위치에 국공립어린이집을 설치하여 보육의 공공성을 강화하고 주민에게 도움을 주는 행정 업무가 필요하다.
V. 결론
GIS 공간 분석 및 AI 랜덤포레스트 모델을 사용하여 실질적으로 국공립어린이집 필요한 지역을 도출할 수 있었다(표 4).
표 4.
국공립어린이집 설치가 필요한 지역(상위 20개)
화전동, 효자동, 삼송동, 성사2동, 행주동은 격자별 점수가 높은 46ab56aa 등에 국공립어린이집을 선정하여, 그림 15와 같이 국공립어린이집 사각 지대에 있는 주민에게 지원해야 한다. 대덕동, 행신 1동은 기존 어린이집을 리모델링하여 설치가 필요하다(그림 16).
본 연구의 국공립어린이집 평가 및 선정에 대한 분석은 국정과제 48-3의 2022년 국공립어린이집 이용 아동 40%, 2025년 50% 증가를 위한 선행 연구 모델로 활용이 가능하다. 더불어 재개발 지역을 분석에 추가 적용한다면 향후 도시 계획의 변화에 맞게, 국공립어린이집 설치 위치를 선정할 수 있을 것이다.
현재 국공립어린이집 추가 설치 위치는 저소득층 밀집 지역에 대해 우선적으로 설치해야 한다는 것을 법률에서 의거하고 있기 때문에 기초생계급여 데이터를 활용하여, 격자를 선택하는 방향으로 적용한다면 선별적으로 설치를 할 수 있다고 본다.
본 연구에서 활용하는 데이터는 법률, 정책, 선행연구사례를 기반으로 수집하였으나, 실질적으로 현재의 문제점을 직시하고 활용하기 위해서는 국공립어린이집을 관리하고 운영하는 전문가를 통해 향후 보완 연구가 필요하다.