

I. 서론
II. 자료와 방법
1. 딥러닝 기반 초해상화 모델
2. 연구 자료
3. 연구 방법
4. 평가 방법
III. 결과 및 토의
1. 입력 영상 초해상화
2. 저해상화 후 초해상화
IV. 결론
I. 서론
위성을 활용한 원격탐사는 광범위한 영역을 주기적으로 관측하는 장점이 있어, 최근 그 활용도가 더욱 증가하고 있다. 광학위성을 활용한 원격탐사 기술은 활용수요에 따라 지속적으로 발전되어 왔으며 다양한 분야로 확장되어 활용되고 있다(Benediktsson et al., 2012). 그러나 원격탐사 응용분야에서는 더욱 세부적인 고해상도 영상이 요구되지만 하드웨어의 제한과 위성의 운용 궤도로 인해 위성영상은 일반적인 이미지보다 더 복잡하고 정밀하지 못한 경우가 많다(Xu et al., 2018). 이에 위성영상의 실질적 활용성을 증대시키기 위해서는 위성영상의 공간해상도 향상을 위한 방인이 요구된다. 초해상화 기법은 센서의 한계를 극복하여 이미지 해상도를 향상시키는 기술로, 원본 영상보다 공간정보를 세분화하여 픽셀(pixel) 수를 증가시킨다(Park et al., 2003). 또한 해상도에 따른 하드웨어의 부하를 방지하고 저해상도 영상정보의 하위 픽셀 수준에서 영상을 재구성할 수 있는 특징이 있다(Yang et al., 2015). 이처럼 공간해상도에 따라 객체정보를 파악하는 수준에는 차이가 존재하며(구자용, 2011), 초해상도화(Super Resolution, SR) 기법을 통해 탐지 정확도를 향상시키는 방법이 시도될 필요가 있다(최소연 등, 2022).
초해상화 기법을 활용한 위성영상 고해상화 연구는 많은 분야에서 시도되어 왔다(Merino and Nunez, 2007; Shen et al., 2009; Yang et al., 2010; Pan et al., 2013; Zhang et al., 2014). Merino and Nunez(2007)은 천문학 분야에서 잘 알려진 가변 픽셀 선형 재구성 알고리즘을 적용하 바 있으며, Shen et al.(2009)은 MODIS(Moderate Resolution Imaging Spectroradiometer) 원격탐사 이미지를 복원하기 위한 초고해상도 이미지 재구성 알고리즘을 제안하였다. Yang et al.(2010)은 희소 신호 표현을 기반으로 낮은 해상도 이미지 패치에 대한 희소 표현을 찾고 이 표현을 사용하여 고해상도 이미지 패치를 생성하였다. Pan et al.(2013)은 고해상도 이미지 패치를 희소하게 나타내는 사전을 식별하는 것을 목적으로 압축 센싱, 구조적 자기 유사성, 사전 학습 기반 방법을 사용하였다. Zhang et al.(2014)는 다중 각도 원격탐사 이미지의 초고해상도 복원을 위해 적응 가중 초고해상도 기술을 제안하였다.
이처럼 초해상화는 여러 분야의 다양한 기법들을 활용한 연구가 진행되어 왔지만, 최근에는 영상인식 분야에서 보다 정밀한 분석을 위해 딥러닝 기법을 기반으로 하는 초해상화 연구가 많이 진행되고 있다. 하지만, 이러한 딥러닝 기반의 초해상화 모델들을 위성영상에 적용하여 그 효과를 비교한 연구는 많지 않다. 이에 본 연구에서는 딥러닝 기반 초해상화 모델을 광학 위성 영상에 적용하여 그 가능성을 검토하고자 한다. Sentinel-2 위성 영상과 국토위성(Compact Advanced Satellite, CAS500-1)의 Red, Green, Blue밴드로 만든 트루 컬러(true color) 영상에서 EDSR (Enhanced Deep Super-resolution Network), WDSR (Wide Activation for Efficient and Accurate Image Super-Resolution), SRGAN (Super-Resolution Generative Adversarial Network), ESRGAN (Enhanced Super-Resolution Generative Adversarial Network)의 네 가지 딥러닝 기반 초해상화 모델을 통해 고해상도화 하고 그 결과를 비교분석하여 가용성을 평가하였다.
II. 자료와 방법
1. 딥러닝 기반 초해상화 모델
연구에서 사용한 모델은 CNN(Convolutional Neural Network)기반의 1)EDSR (Enhanced Deep Super-resolution Network)과 이를 발전시킨 2)WDSR(Wide Activation for Efficient and Accurate Image Super-Resolution), 그리고 GAN(Generative Adversarial Network)기반의 3)SRGAN(Super-Resolution Generative Adversarial Network)과 이를 개선시킨 4)ESRGAN(Enhanced Super-Resolution Generative Adversarial Network)을 사용하였다. 네 가지 모델을 Sentinel-2와 국토위성영상에 적용하여 단일 영상기반 초해상화(Single Image Super resolution, SISR)를 수행하였다.
1) EDSR (Enhanced Deep Super-resolution Network)
EDSR은 딥러닝을 활용한 초해상도 영상 생성을 위한 모델 중 하나로, 영상 해상도 향상시켜 시인성을 높이는 데 중점을 둔다(그림 1). EDSR의 핵심적 특징은 네트워크의 깊이를 증가시킴으로써 더 나은 성능을 낼 수 있다는 것이다. 각 레이어에서는 특성 맵의 적절한 결합과 잔여 연결(residual connection)을 활용하여 영상의 고주파 성분을 효과적으로 학습한다. 또한 기존의 잔차 네트워크를 개선하고 모델을 확장시키면서 훈련 절차를 안정화하도록 구성되어 성능이 향상되었다. 최근에는 EDSR을 개선한 다중스케일 심층 초해상도 시스템(Multi-scale Deep Super-Resolution system, MDSR) 및 훈련 방법이 제안되었다. 이 시스템은 단일 모델에서 다양한 업샘플링 비율의 고해상도 영상을 복원할 수 있다. 제안된 방법들은 벤치마크 데이터셋에서 최첨단 방법보다 우수한 성능을 보이며, NTIRE2017 초해상도 챌린지에서 수상함으로써 그 우수성을 입증하였다(Lim et al., 2017).
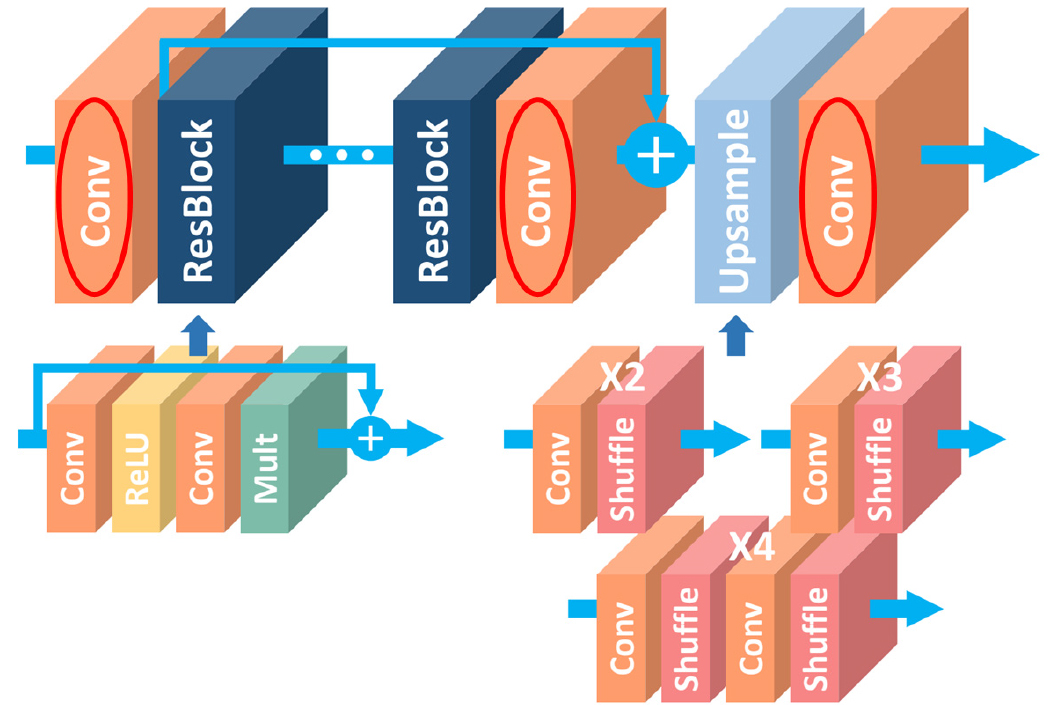
2) WDSR (Wide Activation for Efficient and Accurate Image Super-Resolution)
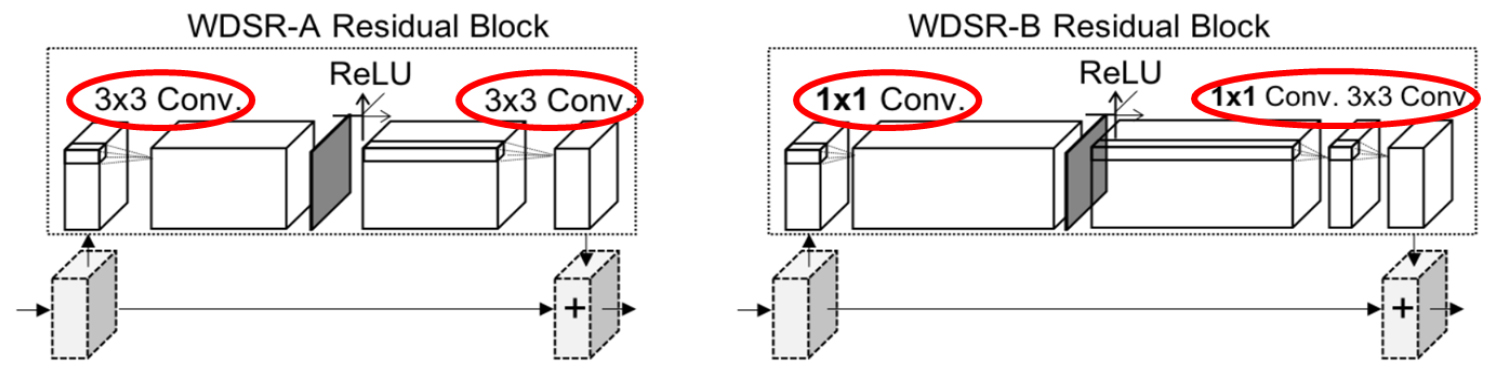
WDSR은 EDSR의 발전된 형태로, 더 넓은 활성화 함수를 사용하여 영상의 해상도를 높이는 데 중점을 둔 모델이다(그림 2). 넓은 활성화 함수는 모델이 다양한 고주파 특성을 잡아내도록 도와준다. 매개변수와 계산 리소스가 동일하다면 Rectified Linear Unit (ReLU) 활성화 함수(activation function) 적용 전 단계에서 더 넓은 특징맵을 가진 모델이 우수한 성능을 보였다. 이로 인해 생성된 초해상화 네트워크는 각 블록에서 활성화 함수 이전에 더 넓은 채널을 가지며, 효율적인 특징 매핑(identity mapping)을 수행한다. 이에 선형 저랭크 합성곱(linear low- rank convolution)을 도입하여 활성화 함수를 더 확장함으로써 계산 부담을 줄이고 정확도를 향상시켰으며, 가중치 정규화(weight normalization)를 통해 훈련하여 더 나은 정확도를 얻었다. WDSR은 PSNR (peak signal-to-noise ratios) 면에서 대규모 영상 초해상화 벤치마크에서 더 나은 결과를 보였다. 이 방법은 NTIRE (New Trends in Image Restoration and Enhancement) 2018 영상 초해상화 챌린지에서 현실적인 트랙에서 가장 높은 점수를 받아 그 우수성을 입증받은 모델이다(Yu et al., 2018).
3) SRGAN (Super-Resolution Generative Adversarial Network)
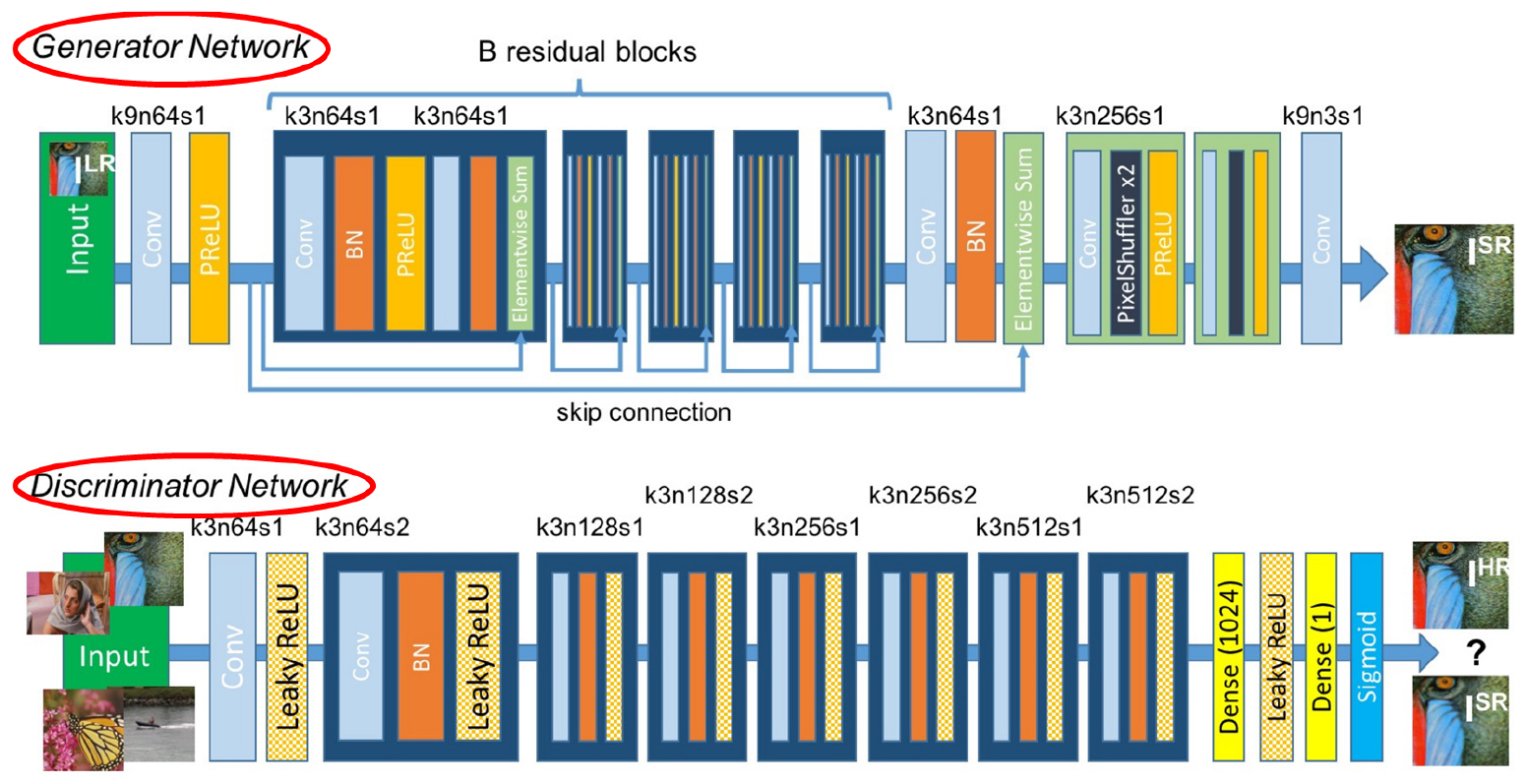
SRGAN은 기존의 손실 함수에 생성적 적대신경망(Generative Adversarial Network, GAN)의 손실을 추가하여 더 자연스러운 고해상도 영상을 생성하는 초해상도 모델이다(그림 3). 4배 업샘플링 팩터(upscaling factors)에 대한 현실적인 영상을 추론할 수 있는 프레임워크이며, 이를 위해 적대적 손실(adversarial loss)과 내용 손실(content loss)로 구성된 지각 손실 함수(perceptual loss function)를 사용하였다. 적대적 손실은 판별자 네트워크(discriminator network)를 사용하여 자연 영상 매니폴드(manifold)로 투입하는 데 사용되며, 이 네트워크는 초해상화 영상과 입력 영상을 구별하도록 훈련된다. 또한 픽셀 공간의 유사성이 아닌 지각적 유사성에 기인한 내용 손실을 사용한다. 심층 잔차 네트워크는 현실적인 질감 복원이 가능하며, MOS (mean-opinion-score) 테스트에서 SRGAN을 사용하여 지각적 품질에서 큰 향상을 보여주었다(Ledig et al., 2017).
4) ESRGAN (Enhanced Super-Resolution Generative Adversarial Network)
ESRGAN은 SRGAN을 개선한 모델로, GAN 기반의 초해상도 영상 생성에서 우수한 성능을 보여준다(그림 4). ESRGAN은 GAN의 학습 안정성과 생성된 영상의 품질을 향상시키기 위해 향상된 생성자 및 판별자 아키텍처를 도입했다. 기본 네트워크 구축 단위로 배치 정규화(batch normalization) 없이 잔차 내 잔차 밀집 블록(Residual-in-Residual Dense Block, RRDB)을 적용하였다. 또한 판별자가 절대값 대신 상대적 실제성을 예측하도록 하며, 활성화 함수 이전의 특징을 사용하여 지각적 손실을 개선함으로써 밝기 일관성을 유지시키고 질감복구를 가능하게 한다. 이러한 개선된 특징들로 ESRGAN은 SRGAN보다 현실적이고 자연스러운 질감으로 일관되게 더 나은 시각적 품질을 제공하여 PIRM2018-SR Challenge에서 가장 우수한 평가를 받았다(Wang et al., 2018).

2. 연구 자료
Sentinel-2는 유럽 연합 집행위원회(European Commission, EC)의 코페르니쿠스(Copernicus) 지구 관측 프로그램의 일환으로 유럽우주기구(European Space Agency, ESA)가 추진하여 개발된 지구 관측 위성군이다. 동일한 태양 동기 궤도에 배치된 두 대의 극궤도 위성인 Sentinel-2 A와 B로 이루어져 있으며, 이 두 위성들은 180도 이상의 위상 차이를 가진다. 적도 기준 5일의 높은 재방문 주기를 가지며, 290km의 넓은 관측폭(swath)으로 지표면 조건의 변동을 모니터링 하는 것을 주요 임무로 한다(ESA, n.d.). 본 연구에서는 ESA에서 제공하고 있는 대기보정과 기하보정이 완료된 Level-2A 자료 중 JPEG2000형식의 TCI (True Color Image)영상을 활용하였다. 이는 10m의 공간해상도를 가지는 B02(Blue), B03(Green), B04(Red) 밴드로 구성된 RGB 영상이며, 반사율은 1에서 255사이로 코딩되며 0은 no data를 의미한다. 영상은 초해상화 방법 간의 비교를 용이하게 하기 위해 작은 객체가 많이 밀집되어 있는 지역을 선정하였으며, 2022년 영상 중 구름비율이 5% 이하의 청천 영상을 사용하였다.
Sentinel-2 영상과의 공간해상도에 따른 결과 차이를 비교하기 위해 국토위성 영상을 사용하였다. 차세대 중형위성 1호(Compact Advanced Satellite, CAS500-1)는 국토위성으로도 불리며, 500kg 위성으로 50cm의 공간해상도를 가진 전정색(Panchromatic) 밴드와 2m의 공간해상도를 가진 다중분광 밴드로 구성되어 있다. 재방문 주기는 4.6일이며, 관측폭(swath width)은 12 km이다(김진광 등, 2022). 본 연구에서는 기하보정과 정밀정사가 완료된 Level 2G을 활용하였다. 팬샤프닝(Pan-sharpening) 알고리즘을 통해 2m 분광밴드 영상과 0.5m 전정색 영상의 상관관계를 기반으로 만들어진 0.5m 분광밴드 영상을 활용하였다(국토위성센터, 2021). ENVI(The Environmental for Visualizing Images) 소프트웨어에서 Red, Green, Blue 밴드를 합성하여 반사율을 0~255로 변환하여 트루 컬러 영상을 만들었다.
3. 연구 방법
본 연구에서는 EDSR, WDSR, SRGAN, ESRGAN을 제안한 각 연구에서 제시된 매개변수를 사용하였으며, 가중치는 다양한 장면이 포함된 DIV2K (DIVerse 2K resolution high-quality images for image processing) 데이터셋로 학습된 가중치를 사용하였다. 모델의 크기 및 효율을 고려하여 Sentinel-2 및 국토위성 영상의 폭과 넓이를 1,024 픽셀 크기로 자른 영상을 입력 영상으로 사용하였다(그림 5).
네 모델을 크게 두 가지 방법으로 실험을 하였는데, (1) 입력 영상인 폭과 넓이 1,024픽셀(pixel)인 입력 영상에서 4배 초해상화하여 폭과 넓이 4,096 픽셀인 영상을 출력하였다. 추가로, 패치의 크기에 따른 차이가 발생하는지 보기 위해 1,024 픽셀 영상을 128픽셀 패치로 자른 영상을 초해상화 한 후 다시 합쳐 1,024 픽셀 영상으로 생성하였다. (2) 입력 영상인 폭과 넓이 1,024 픽셀인 입력영상에서 4배 저해상화한 후 다시 4배 초해상화하여 복원하였다. 복원된 영상은 입력영상과 같은 크기의 영상이 출력되었으며, 저해상화에는 영상 다운샘플링에 일반적으로 활용되는 리샘플링 기법인 INTER_AREA을 사용하여 주변 픽셀기반으로 보간하였다.

4. 평가 방법
본 연구에서는 입력영상과 초해상화 된 영상을 육안으로 비교하기 위해 입력영상에서 일부분을 자른 후 확대하였고, 초해상화 된 영상은 입력 영상을 기준으로 같은 공간만큼 자른 후 확대하였다. 이렇게 확대된 영상을 육안으로 비교하여 정성적으로 평가하였다. 네 모델의 초해상화 결과 영상과의 비교군으로 INTER_LINEAR 기법으로 보간한 영상을 생성하였다.
초해상화를 한 영상에는 정답과 레이블로 불리는 Ground-Truth(GT)가 없으므로 정성적인 평가를 수행하였다. 평가지표는 추가적인 참고자료로 활용하였으며, PSNR (Peak Signal-to-Noise Ratio)과 SSIM (Structural Similarity Index) (Wang et al., 2004)을 사용하였다. PSNR은 압축된 영상 또는 신호 재구성 영상과 입력 영상 간의 픽셀 차이를 dB 단위로 측정하는 데 사용된다. PSNR 점수가 높을수록 재구성된 영상의 품질과 픽셀 충실도가 높음을 나타낸다. SSIM은 두 영상 간의 밝기, 대조 및 구조의 노이즈 간섭 왜곡을 측정하는 지표이다. PSNR은 주로 잡음을 고려하며, SSIM은 인간 시각 시스템의 특성을 고려하여 구조적 유사성을 측정한다. 영상이나 비디오의 품질을 평가하기 위해서는 두 지표를 함께 사용하는 것이 일반적이다. PSNR은 (2)와 같이 계산된다.
여기서 는 최대 픽셀 값을 나타내며 트루 컬러 영상의 경우 는 255이다. 그리고 MSE는 크기가 인 영상 와 간의 평균 제곱 오차를 나타낸다. SSIM은 (3)과 같이 계산된다.
여기서 와 는 각각 영상 와 의 픽셀 평균을 나타내며, 는 영상 와 의 공분산을 나타낸다. 및 는 각각 영상 와 의 대응하는 분산을 나타낸다. 및 는 0으로 나누는 것을 피하기 위한 상수이다. 또한, 은 영상 픽셀 변동의 범위이다. 과 는 각각 기본값으로 0.01 및 0.03으로 설정된다.
III. 결과 및 토의
1. 입력 영상 초해상화
그림 6, 7은 Sentinel-2 위성 영상에서, 그림 8, 9는 국토위성 영상에서의 입력 영상으로 폭과 넓이가 1,024 픽셀인 부분 및 이를 보간법 및 네 가지 딥러닝 기반 모델을 사용하여 4배 초해상화한 폭과 넓이가 4,096 픽셀인 결과영상의 일부분을 확대한 그림이다. 딥러닝 기반 모델로 초해상화 된 결과를 살펴보면, 입력 영상과 보간법을 통한 결과 영상에 비해 뚜렷한 차이가 나타나며, 네 가지 모델 모두 성공적으로 초해상화가 수행되었음을 알 수 있다. WDSR 모델이 EDSR 모델보다, 그리고 ESRGAN 모델이 SRGAN 모델보다 더 효과적인 초해상화를 보여주고 있다. EDSR 모델과 SRGAN 모델에서는 결과 영상에 더 많은 노이즈가 발생했지만, WDSR 모델과 ESRGAN 모델에서는 이러한 노이즈가 감소한 것으로 나타났다. 또한, ESRGAN 모델의 결과가 WDSR 모델의 결과보다 객체의 테두리가 더 선명해 보이지만, 더 많은 왜곡이 발생한 것으로 관찰되었다.




그림 10은 128픽셀 패치로 잘라낸 각 패치를 초해상화하고 다시 결합한 결과영상이다. 각 패치에서는 결과의 차이가 나타나지 않았으나, 패치 테두리와 이어지는 부분에서 일관성이 부족한 현상이 생겼다. 이는 모델의 초해상화 과정에서 테두리 부분의 초해상화가 일부 정확하지 않음을 나타낸다. 각 패치의 테두리 부분에서는 모델이 주변 픽셀을 활용하여 초해상화를 수행할 때에 서로 다른 픽셀을 참조한 영향으로 추정된다. 또한, 국토위성 영상에서는 Sentinel-2 위성 영상에 비해 작은 객체인 자동차와 같은 대상에서도 효과적인 초해상화가 이루어지고 높은 선명도의 영상이 생성되었다.

2. 저해상화 후 초해상화
그림 11, 12는 Sentinel-2 입력영상, 저해상화 영상, 4배 초해상화 영상이고, 그림 13, 14는 국토위성 입력영상, 저해상화 영상, 4배 초해상화 영상에 해당한다. 각 평가지표는 입력영상과 최종 초해상화 결과영상간 PSNR과 SSIM을 계산한 결과이다.




저해상화 후 다시 초해상화를 한 결과영상이 입력영상과 유사하거나 동일한 결과로 도출될 것으로 기대했지만, 실제로는 저해상화 과정에서 화소가 왜곡되어 입력영상과는 다른 결과를 보였다. 이는 초해상화 과정이 입력영상과 동일한 영상을 재현하는 것이 아니라 재구성하는 과정임을 반영하고 있다. 특히 GAN 기반 모델들은 초해상화 과정에서 세부사항을 과하게 강조하여 왜곡된 결과를 생성하는 경향이 있었다. 그러나 초해상화된 결과영상은 입력영상과 동일한 해상도를 가지면서도 객체들이 더 뚜렷하게 구별되었다.
또한, 국토위성 영상은 Sentinel-2 위성 영상보다 조밀한 공간해상도를 가지고 있다. 이에 따라 국토위성 영상에서는 왜곡 현상이 현저히 감소한 것을 관찰할 수 있었다. 이는 Sentinel-2 위성 영상의 저해상화 영상과 달리 객체의 형태가 보존되어 왜곡이 줄어들었기 때문으로 추측된다.
표 1은 그림 11, 12, 13, 14에서 계산된 평가지표 PSNR과 SSIM을 정리한 표이다. 평가지표에서는 CNN 기반 모델, 보간법, 그리고 GAN 기반 모델 순으로 높은 평가지표를 보여준다. 특히 GAN 모델의 경우 PSNR과 SSIM이 상대적으로 낮게 평가되었는데, 이는 GAN 모델이 기존 픽셀이 아닌 실제영상의 분포를 기반으로 학습하며 더 자연스럽게 재구성을 시도하기 때문이다. 결과적으로 객체가 저해상화 과정에서 왜곡되지 않고 보존되는 경우, 높은 품질의 초해상화 영상이 생성됨을 확인할 수 있었으며, 객체의 크기가 해상도에 비해 크다면 더 우수한 초해상화 결과를 얻을 수 있음을 알 수 있었다.
본 연구에서는 모델의 가중치가 위성영상이 아닌 통상적인 일상 영상을 기반으로 학습되었으며, 특히 Sentinel-2 위성 영상은 최신 위성에 비해 비교적 낮은 해상도를 갖고 있어 저해상화 후 초해상화 과정에서 왜곡이 강조되었다. 반면 국토위성 영상에서는 해상도 복원 과정에서의 왜곡이 상대적으로 덜 발생하였는데, 객체의 크기에 비해 높은 해상도를 갖는 경우에는 딥러닝 기반의 초해상화 기법이 기존의 보간법에 비해 더 선명한 영상을 생성하는 것으로 해석할 수 있다. 이로써 상대적으로 높은 해상도를 갖는 국토위성 영상에서는 딥러닝 기법을 활용한 초해상화가 효과적이며 고품질의 결과를 도출할 수 방안이라 판단된다.
표 1.
Evaluation indices from super-resolution results
| Linear | EDSR | WDSR | SRGAN | ESRGAN | ||
| Fig 11 | PSNR | 16.838 | 16.603 | 16.579 | 15.022 | 11.196 |
| SSIM | 0.545 | 0.618 | 0.62 | 0.505 | 0.365 | |
| Fig 12 | PSNR | 22.122 | 21.946 | 21.973 | 19.92 | 16.032 |
| SSIM | 0.74 | 0.77 | 0.771 | 0.644 | 0.592 | |
| Fig 13 | PSNR | 23.982 | 24.27 | 24.296 | 23.217 | 22.526 |
| SSIM | 0.754 | 0.789 | 0.791 | 0.682 | 0.666 | |
| Fig 14 | PSNR | 25.838 | 26.274 | 26.288 | 25.076 | 24.023 |
| SSIM | 0.797 | 0.832 | 0.833 | 0.737 | 0.705 | |
IV. 결론
본 연구에서는 Sentinel-2 위성 영상과 국토위성 영상에서 딥러닝 기반 초해상화 모델의 성능을 평가하였다. 딥러닝 기반 초해상화 모델은 기존의 보간법에 비해 우수한 성능을 보였으며, 특히 국토위성 영상과 같이 해상도가 상대적으로 높은 경우 더 효과적이었다. 객체가 저해상화 과정에서 왜곡되지 않고 보존되는 경우에는 높은 품질의 초해상화 영상이 생성되었으며, 객체의 크기가 해상도에 비해 크다면 우수한 초해상화 결과를 얻을 수 있다. 본 연구의 초해상화 모델 가중치는 일상 영상으로 학습된 가중치를 활용하였으나, 향후 영상의 시인성 향상을 통해 객체 식별을 보다 원활하게 하기 위해서는 위성영상으로 학습한 가중치를 적용한 초해상화 연구가 필요하다. 또한, 트루 컬러 영상만을 대상으로 수행되었으며, 그 외 다른 밴드의 영상이나 반사도에 대한 적용 가능성을 검토할 필요가 있다. 현재까지 수행된 초해상도 연구들에서 얼마나 정확하게 잘 수행 되었는지를 평가할 수 있는 정량적 지표가 제시되지는 않았다. 이에 향후 연구에서 지상기준점과 같은 Ground-Truth 역할을 할 수 있는 물체를 활용한다면 정량적인 검증이 가능할 것으로 사료된다. 또한 본 연구에서는 활용된 모델 이외에도 다양한 초해상화 기법들과의 비교연구를 통해 더욱 향상된 품질의 초해상도 영상을 생성함으로써 활용성을 제고시킬 필요가 있다. 위성영상에서 딥러닝 기반 초해상화 모델을 활용하면 보다 선명한 영상을 얻을 수 있으며, 이는 도시 계획, 환경 모니터링, 재해 감시 등과 같이 다양한 분야에서 활용될 수 있을 것이다.
